How to Tap into Higher-Level Abstraction, Efficiency & Automation to Simplify your AI/ML Journey
Yaron Haviv and Rajeev Chawla | April 6, 2021
You’ve already figured out that your data science team cannot keep developing models on their laptops or a managed automated machine learning (AutoML) service and keep their models there. You want to put artificial intelligence (AI) and machine learning (ML) into action and solve real business problems. And you’ve discovered that it’s not that easy to move from (data) science experiments to always-on services that integrate with your existing business applications, data, APIs, and infrastructure. Keeping to your SLA, addressing security and governance, and maintaining model accuracy is even harder.
You already bet on Kubernetes as your cloud-native infrastructure, but now you have a micro-services sprawl. How do you manage persistent storage, backup, disaster recovery, and rapid cloning in that environment? How can you lower and control your costs? And can you abstract away all that complexity and focus on higher-level services, which will help you focus on building modern applications instead of chasing Pods and YAMLs?
Accelerating deployment with an integrated MLOps stack and application-aware data management
According to industry reports, data science teams don’t get to focus on data science work. They spend most of their time on data wrangling, data preparation, managing software packages and frameworks, configuring infrastructure, and integrating various components. Many organizations underestimate the amount of effort it takes to incorporate machine learning (ML) into production applications. This problem leads to abandoning entire projects when they’re halfway done --VentureBeat AI reports 87% of data science projects never make it into production. Or, far more resources and time are consumed than first anticipated. Machine learning operations (MLOps) solutions address this challenge: These solutions combine artificial intelligence (AI) and ML practices with DevOps practices. Their goal is to create continuous integration and continuous development and delivery (CI/CD) of data and of ML-intensive applications.
The joint NetApp and Iguazio solution addresses these challenges and accelerates your path to production. The NetApp® Astra™ service tackles the hardest infrastructure challenge in Kubernetes: provisioning of persistent storage, mobilizing the data, and reducing the operational costs of storage. Iguazio provides a fast, automated, and fully managed data-science and MLOps stack that’s based on best-in-class open-source components fully integrated into Iguazio’s proprietary technology. With NetApp and Iguazio working together for you, you can focus your resources on your business goals and get back to your data science projects.
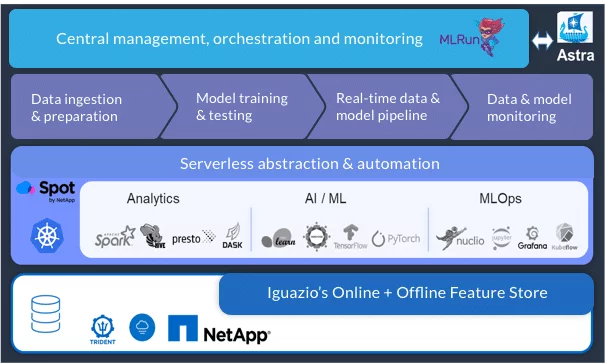
Iguazio’s open-source MLOps orchestration framework, MLRun, integrates and automates the different layers in the data science, data engineering, and MLOps stack to deliver faster results with fewer resources. This framework enables you to run the same code either locally on your PC for a test or, with minimal changes, on a large-scale Kubernetes cluster. Iguazio adds a persistent data layer, which is built using NetApp file and object storage products, plus a real-time database and feature store.
The solution is managed through a central orchestration and monitoring layer with a unified portal, making the UI, CLI, and software development kit (SDK) accessible from anywhere. This accessibility simplifies management of the entire MLOps workflow. The orchestration layer integrates with NetApp Astra to automate data orchestration and mobility tasks.
What this automation lets you do:
- Simplify storage provisioning and better resource utilization.
- Enable service migration or cloning, within or across clouds.
- Simplify data lifecycle management (snapshots, backup, synchronization, etc.).
- Reduce cloud compute costs by leveraging spot instances.
One of the key challenges in data science is to be able to reproduce and explain model results, and models results depend on the data used in training or analytics tasks. NetApp Snapshot™ technology and cloning technology allow you to save many Snapshot copies of your data and reproduce the exact data that was used in training. In today’s hybrid cloud landscape, your organization needs to mobilize data between clusters in the cloud. Your organization also needs to push data collected on premises into the cloud for training or to train with on-premises data and move the results and models to the cloud. With Astra, all of that can be automated, without IT and DevOps hassles.
To learn more about how to simplify and accelerate your AI/ML journey by focusing on efficiency, automation, and higher-level abstraction services, book a live demo.


