How to Run Spark Over Kubernetes to Power Your Data Science Lifecycle
Marcelo Litovsky | September 14, 2020
A step by step tutorial on working with Spark in a Kubernetes environment to modernize your data science ecosystem
Spark is known for its powerful engine which enables distributed data processing. It provides unmatched functionality to handle petabytes of data across multiple servers and its capabilities and performance unseated other technologies in the Hadoop world. Although Spark provides great power, it also comes with a high maintenance cost. In recent years, innovations to simplify the Spark infrastructure have been formed, supporting these large data processing tasks.
Kubernetes, on its right, offers a framework to manage infrastructure and applications, making it ideal for the simplification of managing Spark clusters. It provides a practical approach to isolated workloads, limits the use of resources, deploys on-demand and scales as needed.
With Kubernetes and the Spark Kubernetes operator, the infrastructure required to run Spark jobs becomes part of your application. Adoption of Spark on Kubernetes improves the data science lifecycle and the interaction with other technologies relevant to today's data science endeavors.
However, managing and securing Spark clusters is not easy, and managing and securing Kubernetes clusters is even harder.
So why work with Kubernetes? Well, unless you’ve been living in a cave for the last 5 years, you’ve heard about Kubernetes making inroads in managing applications. Your investment in understating Kubernetes will help you leverage the functionality mentioned above for Spark as well as for various enterprise applications.
Before You Start
It’s important to understand how Kubernetes works, and even before that, get familiar with running applications in Docker containers. Start by creating a Kubernetes pod, which is one or more instances of a Docker image running over Kubernetes.

You also need to understand how services communicate with each other when using Kubernetes. In general, your services and pods run on a namespace and a service knows how to route traffic to pods running in your cluster. A service’s IP can be referred to by name as namespace.service-name.
Running Spark Over Kubernetes
A big difference between running Spark over Kubernetes and using an enterprise deployment of Spark is that you don’t need YARN to manage resources, as the task is delegated to Kubernetes. Kubernetes has its RBAC functionality, as well as the ability to limit resource consumption.
You can build a standalone Spark cluster with a pre-defined number of workers, or you can use the Spark Operation for k8s to deploy ephemeral clusters. The later gives you the ability to deploy a cluster on demand when the application needs to run. Kubernetes works with Operators which fully understand the requirements needed to deploy an application, in this case, a Spark application.
What does the Operator do?
- Reads your Spark cluster specifications (CPU, memory, number of workers, GPU, etc.)
- Determines what type of Spark code you are running (Python, Java, Scala, etc.)
- Retrieves the image you specify to build the cluster
- Builds the cluster
- Runs your application and deletes resources (technically the driver pod remains until garbage collection or until it’s manually deleted)
Give it a Try
I’ve put together a project to get you started with Spark over K8s. You can run it on your laptop or take my commands and run it on a larger Kubernetes cluster for larger job executions. All the artifacts and instructions below are available in a Github repo. If you run into technical issues, open an issue in Github, and I’ll do my best to help you.
GitHub repo: http://github.com/marcelonyc/igz_sparkk8s
- Instructions to deploy Spark Operator on Docker Desktop
- Configuration commands and files
- Examples
Pre-requisites
- Docker desktop with Kubernetes enabled
- To run the demo configure Docker with three CPUs and 4GB of ram
Download all the artifacts from this repository
Make a note of the location where you downloaded
Install components
From a Windows command line or terminal on Mac
Confirm Kubernetes is running
kubetctl get pods
Setup Kubernetes dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
Start proxy (on second window)
You can stop it after running helm
kubectl proxy
Install helm
For this setup, download the Windows or Mac binary.
Extract and expand somewhere local.
Documentation: https://helm.sh/docs/
ALL binaries: https://github.com/helm/helm/releases
Windows Binary: https://get.helm.sh/helm-v3.0.0-beta.3-windows-amd64.zip
Create namespace (File provided)
Go to the location where you downloaded the files from this repository
kubectl apply -f spark-operator.json
Deploy Spark Operator Kubernetes packages
Location of hemlhelm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
Location of hemlhelm install incubator/sparkoperator --generate-name --namespace spark-operator --set sparkJobNamespace=default
Optional
kubectl create clusterrolebinding add-on-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default
Configure the Spark application
Get the Spark service account. Make a note of the sparkoprator-xxxxxx-spark name
kubectl get serviceaccounts
Edit spark-pi.yaml
Change the serviceAccount line value to the value you got in the previous command
Run the test application
You must be in the directory where you extracted this repository
kubectl apply -f spark-pi.yaml
Monitor the application
Driver and workers show when running. You should see spark-pi-driver and one worker
kubectl get pods
List all Spark applications kubectl get sparkapplications
Detailed list in JSON format Watch state under status
kubectl get sparkapplications -o json
Watch the job execution
kubectl logs spark-pi-driver -f
Delete the application
kubectl delete -f spark-pi.yaml
Next Steps
This example does not address security and scalability. To take things to the next level, check out Iguazio’s Data Science Platform which was built for production over Kubernetes and provides a high performing multi-model data layer.
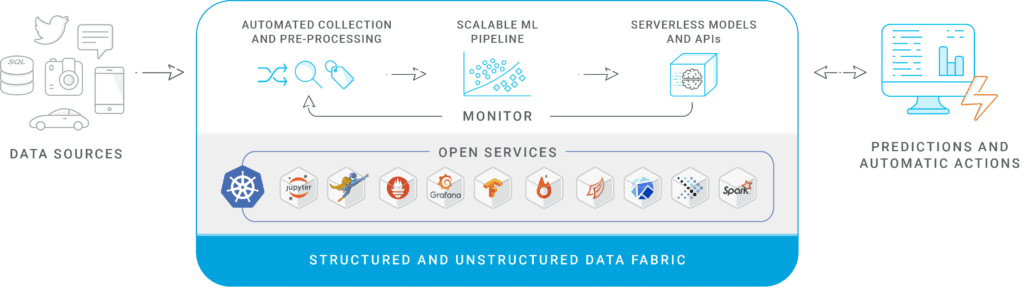
Want to learn more about running Spark over Kubernetes?


