Cloud-Native Will Shake Up Enterprise Storage!
Yaron Haviv | September 16, 2015
Enterprise IT is on the verge of a revolution, adopting hyper-scale and cloud methodologies such as Micro-services, DevOps and Cloud-Native. As you might expect the immediate reaction is to try and apply the same infrastructure, practices and vendor solutions to the new world, but many solutions and practices are becoming irrelevant, SAN/VSAN and NAS among others.
Read my previous blog post for background on Cloud-Native, or this nice post from an eBay expert.
Overview
In the new paradigms we develop software the way cloud vendors do:
- We assume everything can break
- Services need to be elastic
- Features are constantly added in an agile way
- There is no notion of downtime
The way to achieve this nirvana is to use small stateless, elastic and versioned micro-services deployed in lightweight VMs or Docker containers. When we need to scale we add more micro-service instances. When we need to upgrade, DevOps guys replace the micro-service version on the fly and declare its dependencies. If things break the overall service is not interrupted. The data and state of the application services are stored in a set of “persistent” services (Which will be elaborated on later), and those have unique attributes such as Atomicity, Concurrency, Elasticity, etc. specifically targeting the new model.
If we contrast this new model with current Enterprise IT: Today, application state is stored in Virtual Disks. This means we have to have complex and labor intensive provisioning tools to build it, snapshot, and backup. Storage updates are not atomic so we invented “consistent snapshot” which doesn’t always work. We don’t distinguish between shared OS/application files and data, so we must dedup all the overlap. Today the storage layer is not aware of the data semantics, so we deploy complex caching solutions, or just go for expensive All-Flash or In-Memory solution – why be bothered with app specific performance tuning?
Managing Data in a Stateless World
Now that we understand the basic notion that everything can and will break, we have to adopt several key data storage paradigms:
- All data updates must be atomic and to a shared persistency layer. We cannot have temporary dirty caches, cannot use local logs, cannot do partial updates to files, or maintain local journals in the micro-service. Micro-services are disposable!
- Data access must be concurrent (asynchronous). Multiple micro-services can read/update the same data repository in parallel. Updates should be serialized, no blocking or locking or exclusivity is allowed. This allows us to adjust the number of service instances according to demand.
- Data layer must be elastic and durable – we need to support constant data growth or model changes without any disruption to the service. Failures to data nodes should not lead to data loss.
- Everything needs to be versioned to detect and avoid inconsistencies.
You can notice that Enterprise NAS, POSIX semantics and not to mention SAN/VSAN solutions do not comply with the above requirements, and specifically with Atomicity, Concurrency, and Versioning. This can explain why Hyper-Scale Cloud vendors don’t widely use SAN or NAS internally.
With Cloud-Native Apps services like Object Storage, Key/Value, Message Queues, Log Streams are used to make the different types of data items persistent. Disk images may still exist to store small stateless application binaries (like Docker does), those would be generated automatically by the build and CI/CD systems and don’t need to be backed up.
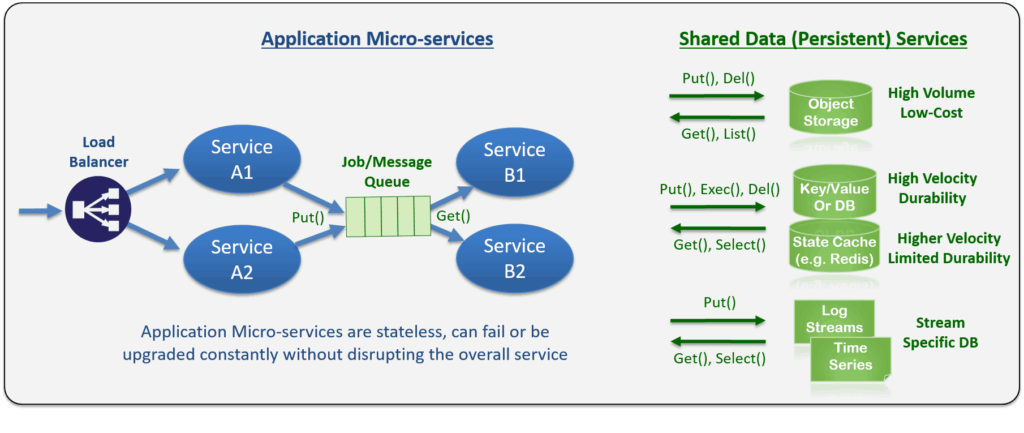
Data items and files are backed up in the object storage, which have built-in versioning, cloud tiering, extensible and searchable metadata. No need for separate backup tools and processes or complex integrations, and no need to decipher VMDK (virtual disk) image snapshots to get to a specific file version since data is stored and indexed in its native and most granular form.
Unlike traditional file storage Cloud-Native data services have atomic and stateless semantics such as Put (to save an object/record), Get (to retrieve an object or record by key and version), List/select (to retrieve a bunch of objects or records matching the query statement and relevant version), exec (to execute a DB side procedure atomically).
The Table below describes some of the key persistent services by category:
| Category | Amazon AWS Service Name | OpenSource Alternatives | Focus |
| Object Storage | S3 | OpenStack Swift | Store mid–large objects cost effectively, extensible Metadata & versioning, usually slow |
| NoSQL/NewSQL DB, Key/Value | DynamoDB,Aurora | Cassandra, MongoDB, Etc. | Store small-mid size objects, data/column awareness, faster |
| Object Cache (in memory) |
ElastiCache (Redis, Memcached) | Redis, Memcached | Store objects in memory (as shared cache), no/partial durability |
| Durable Message Queue | Kinesis | Kafka | Store and route message and task objects between services, fast |
| Log Streams | CloudWatchLogs | Elastic Search (ELK), Solr | Store, map, and query semi-structured log streams |
| Time Series Streams | CloudWatchMonitoring | Graphite, InfluxDB | Store, compact, and query semi-structured time series data |
One may raise the possibility of deploying those persistent services over a SAN or VSAN. But that won’t work well since they must be atomic and keep the data, metadata, and state consistent across multiple nodes and implement their own replication anyway. So using an underline storage RAID/Virtualization is not useful (in many cases even more harmful). The same applies for snapshots/versioning which are handled by those tools at transaction boundaries Vs. at non consistent intervals. In most cases such tools will use just a bunch of local drives.
What to expect in the future?
The fact that each persistent service manages its own data pool, repeats similar functionality, is tight to local physical drives, and lacks data security, tiering, backups or reduction is challenging. One can also observe there is a lot of overlap between the services and most of the difference is at the trade-off between volume, velocity, and data awareness (Variety). In the future many of these tools would be able to use shared Low-Latency, Atomic, and Concurrent Object Storage APIs as an alternative (already supported by MongoDB, CouchDB, Redis, Hadoop, Spark, Etc.). This would lead to centralizing the storage resources and management, disaggregating the services from the physical media, allowing better governess and greater efficiency, and simplifying deployment. All are key for broader Enterprise adoption.
Summary
If you are about to deploy a micro-services and agile IT architecture don’t be tempted to reuse your existing IT practices. Learn how cloud and SaaS vendors do it, and internalize that it may require a complete paradigm shift. Some of those brand-new SANs, VSANs, Hyper-Converged, AFAs, and even scale-out NAS solutions may not play very well in this new world.

