Machine learning operations (MLOps) is the practice of efficiently developing, testing, deploying, and maintaining machine learning (ML) applications in production. MLOps automates and monitors the entire machine learning lifecycle and enables seamless collaboration across teams, resulting in faster time to production and reproducible results.
The Challenges of MLOps
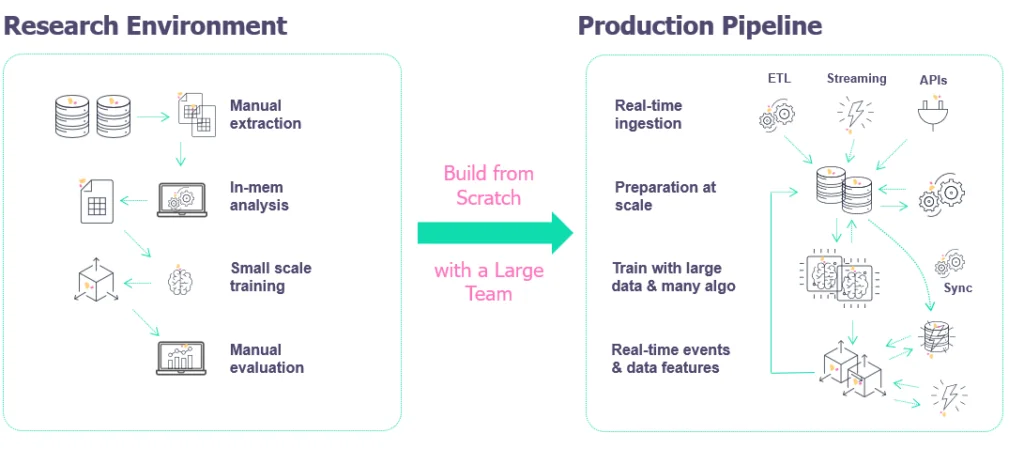
AI and ML practices are no longer the luxury of research institutes or technology giants, and they are becoming an integral ingredient in any modern business application. According to analysts, most organizations fail to successfully deliver AI-based applications and are stuck in the process of turning data science models and feature engineering logic, which were tested on sample or historical data, into interactive applications which work with real-world and large-scale data.
Organizations tend to put too much emphasis on the creation of ML models and placing them behind some API end point. This emphasis overlooks the bigger challenges such as accessing and preparing data in production, integrating the models with online business applications, monitoring and governing the model’s performance, or delivering continuous improvements. The data science and model development process must be a fundamental part of building any modern application.
One of the key challenges is that the data science team often works in a silo, cut off from the engineering and DevOps teams, and use manual development processes, which then need to be manually converted into production-ready ML pipelines. This requires separate teams of ML engineers, data engineers, DevOps and developers to invest additional time and resources, often much more than initially anticipated.
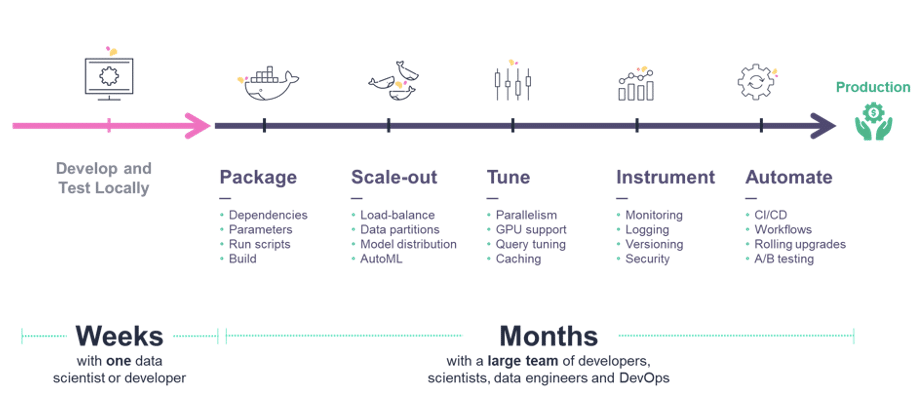
In most cases, the data science logic is refactored into production-oriented frameworks or coding languages, and the data science and engineering teams need to package the code, address scalability, tune for performance, instrument and automate. These tasks are typically manual and can take months. Every time there is a change in the data preparation or model training logic, this whole cycle is repeated.
In a typical development flow, developing code or models is just the first step. The biggest effort goes into making each element production-ready, including data collection, preparation, training, serving and monitoring, and enabling each element to run repeatedly with minimal user intervention.
The research-oriented data science approach that is currently dominant can no longer prevail. Data science MUST adopt agile software development practices with micro-services, continuous integration (CI), continuous delivery (CD), code versioning (Git), and data/configuration/metadata versioning.
MLOps Stages
MLOps: Enabling Continuous Delivery of AI applications
A new engineering practice called MLOps has emerged to address these challenges. As the name indicates, it combines AI/ML practices with DevOps practices, and its goal is to create continuous development, integration and delivery (CI/CD) of data and ML intensive applications.
MLOps is not about running notebooks in production environments and is not about placing an ML model behind an API end point. MLOps is about building an automated ML production environment from data collection and preparation to model deployment and monitoring.
Business benefits:
Deliver business value from data and AI/ML faster
Increase team’s productivity and eliminate silos
Provide reliable and reproducible results
Observe, explain, and improve model behavior and accuracy
MLOps Stage 0: Data Collection and Preparation
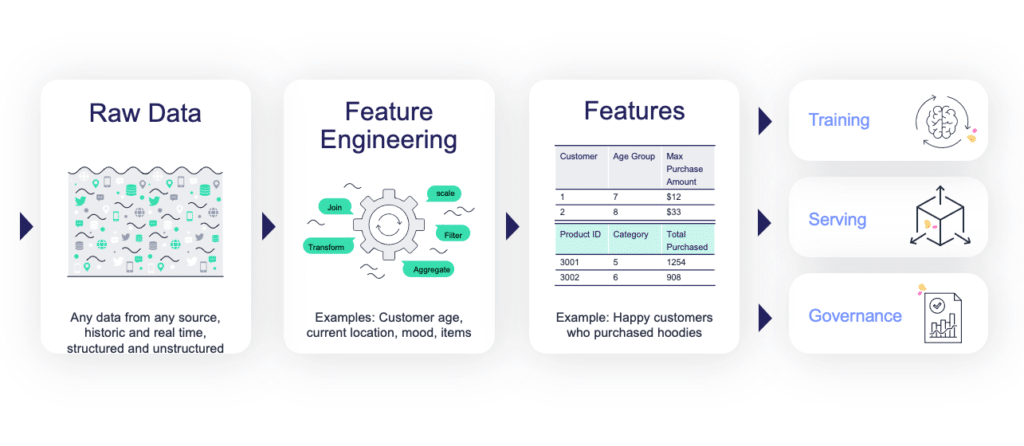
There is no ML without data. Before everything else, ML teams need access to historical and/or online data from multiple sources, and they must catalog and organize the data in a way that allows for simple and fast analysis (for example, by storing data in columnar data structures, such as Parquet).
In most cases, the raw data cannot be used as-is for machine learning algorithms for various reasons such as:
The data is low quality (missing fields, null values, etc.) and requires cleaning and imputing.
The data needs to be converted to numerical or categorical values which can be processed by algorithms.
The data is unstructured in text, json, image, or audio formats, and needs to be converted to tabular or vector formats.
The data needs to be grouped or aggregated to make it meaningful.
The data is encoded or requires joins with reference information.
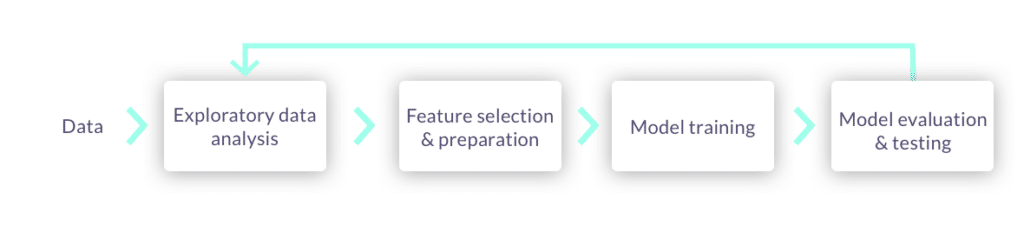
The ML process starts with manual exploratory data analysis and feature engineering on small data extractions. In order to bring accurate models into production, ML teams must work on larger datasets and automate the process of collecting and preparing the data.
Furthermore, batch collection and preparation methodologies such as ETL, SQL queries, and batch analytics don’t work well for operational or real-time pipelines. As a result, ML teams often build separate data pipelines which use stream processing, NoSQL, and containerized micro-services. 80% of data today is unstructured, so an essential part of building operational data pipelines is to convert unstructured textual, audio and visual data into machine learning- or deep learning-friendly data organization.
MLOps solutions should incorporate a feature store which defines the data collection and transformations just once for both batch and real-time scenarios, processes features automatically without manual involvement, and serves the features from a shared catalog to training, serving, and data governance applications. Feature stores must also extend beyond traditional analytics and enable advanced transformations on unstructured data and complex layouts.
MLOps Stage 1: Automated Model Development Pipeline
Data scientists generally go through the following process when developing models:
Extract data manually from external sources
Data labelling, exploration and enrichment to identify potential patterns and features
Model training and validation
Model evaluation and testing
Go back to step 1 and repeat until the desired outcomes have been achieved
The traditional way is to use notebooks, small-scale data, and manual processes, but this does not scale and is not reproducible. Furthermore, in order to achieve maximum accuracy, experiments often need to be run with different parameters or algorithms (AutoML).
With MLOps, ML teams build machine learning pipelines that automatically collect and prepare data, select optimal features, run training using different parameter sets or algorithms, evaluate models, and run various model and system tests. All the executions, along with their data, metadata, code and results must be versioned and logged, providing quick results visualization, compare them with past results and understand which data was used to produce each model.
Pipelines can be more complex—for example, when ML teams need to develop a combination of models, or use Deep Learning or NLP.
ML pipelines can be triggered manually, or preferably triggered automatically when:
The code, packages or parameters change
The input data or feature engineering logic change
Concept drift is detected, and the model needs to be re-trained with fresh data
ML pipelines:
Are built using micro-services (containers or serverless functions), usually over Kubernetes.
Have all their inputs (code, package dependencies, data, parameters) and the outputs (logs, metrics, data/features, artifacts, models) tracked for every step in the pipeline, in order to reproduce and/or explain our experiment results.
Use versioning for all the data and artifacts used throughout the pipeline.
Store code and configuration in versioned Git repositories
Use Continuous Integration (CI) techniques to automate the pipeline initiation, test automation, review and approval process.
Pipelines should be executed over scalable services or functions, which can span elastically over multiple servers or containers. This way, jobs complete faster, and computation resources are freed up once they do, saving significant costs.
The resulting models are stored in a versioned model repository along with metadata, performance metrics, required parameters, statistical information, etc. Models can be loaded later into batch or real-time serving micro-services or functions.
MLOps Stage 2: Building Online ML Services
Once an ML model has been built, it needs to be integrated with real-world data and the business application or front-end services. The whole application or parts thereof need to be deployed without disrupting the service. Deployment can be extremely challenging if the ML components aren’t treated as an integral part of the application or production pipeline.
Production pipelines usually consist of:
Real-time data collection, validation and feature engineering logic
One or more model serving services
API services and/or application integration logic
Data and model monitoring services
Resource monitoring and alerting services
Event, telemetry and data/features logging services
The different services are interdependent. For example, if the inputs to a model change, the feature engineering logic must be upgraded along with the model serving and model monitoring services. These dependencies require online production pipelines (graphs) to reflect these changes.
Production pipelines can be more complex when using unstructured data, deep learning, NLP or model ensembles, so having flexible mechanisms to build and wire up our pipeline graphs is critical.
Production pipelines are usually interconnected with fast streaming or messaging protocols, so they should be elastic to address traffic and demand fluctuations, and they should allow non-disruptive upgrades to one or more elements of the pipeline. These requirements are best addressed with fast serverless technologies.
Production pipeline development and deployment flow:
Develop production components:
API services and application integration logic
Feature collection, validation and transformation
Model serving graphs
Test online pipelines with simulated data
Deploy online pipelines to production
Monitor models and data and detect drift
Retrain models and re-engineer data when needed
Upgrade pipeline components (non-disruptively) when needed
MLOps Stage 3: Continuous Monitoring, Governance, and Retraining
AI services and applications are becoming an essential part of any business. This trend brings with it liabilities, which drive further complexity. ML teams need to add data, code and experiment tracking, monitor data to detect quality problems, monitor models to detect concept drift and improve model accuracy through the use of AutoML techniques and ensembles, and so on.
Nothing lasts forever—not even carefully constructed models that have been trained using mountains of well-labeled data. In these turbulent times of massive global change emerging from the COVID-19 crisis, ML teams need to react quickly to adapt to constantly changing patterns in real-world data. Monitoring machine learning models is a core component of MLOps to keep deployed models current and predicting with the utmost accuracy, and to ensure they deliver value long-term.
MLOps Terminology
Feature Store
A feature store is so much more than simply a repository
Our CEO & CTO discussed
implementing gen AI in highly
regulated industries and innovative ways to mitigate them. We shared our approach for building a 'Gen AI Factory' and so much more.
In our webinar with McKinsey, we dove into the transformative impact of gen AI on enterprise operations, spotlighting advancements across manufacturing, supply chain and procurement.
Watch our session with Databricks to hear advice on improving the accuracy & performance of LLMs while mitigating challenges like risks and escalating costs.