McKinsey launches an open-source ecosystem for digital and AI projects
McKinsey blog, September 2023
Nuclio is an open source serverless platform used to minimize development overhead, increase performance and automate the deployment of data science applications.
Github Join Slack

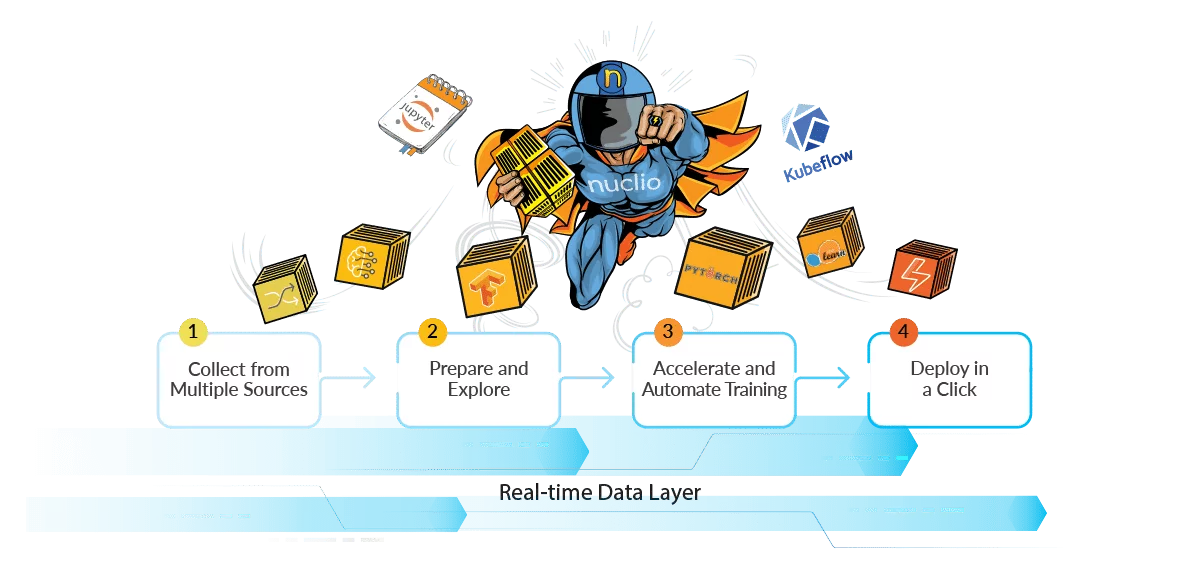
Nuclio parallelizes work within a single pod so that different workers can ingest data simultaneously. It has high throughput and low latency as well as real-time features like zero copy, making it well equipped for data intensive workloads.
Nuclio leverages serverless advantages such as on-demand resource utilization, auto-scaling and automation also for data intensive and batch oriented tasks. It eliminates operational tasks like building, monitoring and artifact tracking, providing the ability to code once and run on different run-times with 2 lines of code.
Users code in a Jupyter notebook and with a simple click convert it to a deployable function. The result is better use of resources on demand as models can scale up and down as needed. Nuclio provides optimized utilization of GPUs and CPUs by using half the amount of resources while achieving better performance.
Dependencies, parameters, run scripts and build
Load-balance, data partitions, model distribution and hyper params
Parallelism, GPU support, query tuning and caching
Monitoring, logging, versioning and security
CI/CD, rolling upgrades and A/B testing







