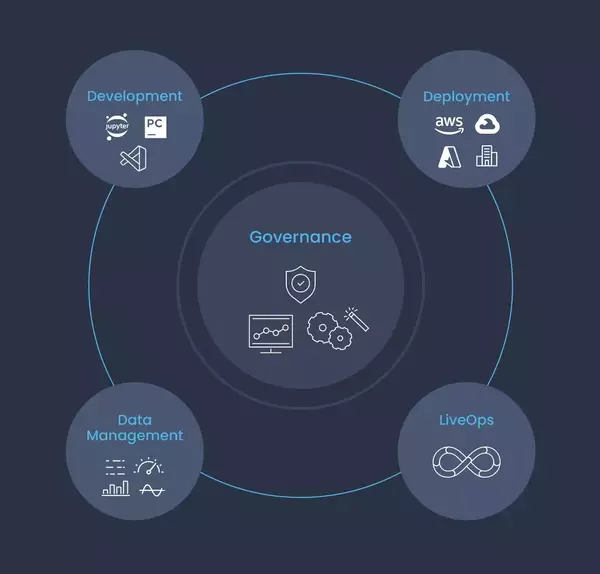
The Iguazio AI Platform enables you to operationalize and de-risk the entire (gen) AI pipeline from data management and development to deployment. Use guardrails to monitor and meet requirements.
Data scientists, data engineers and DevOps can automatically bring business impact with AI at scale, developing on their own or using ready-made AI application recipes and components. The platform includes four resilient and scalable pipelines covering everything from development to production, the ability to eliminate risks by adding guardrails, LLM customization options to improve model accuracy and performance, GPU provisioning capabilities to optimize resources and flexible deployment options, including on-premises, hybrid and multi-cloud.
A data pipeline is the foundation of any AI system. The Iguazio AI platform provides structured and unstructured data pipelines for collecting and ingesting the data, processing it (transformations, cleaning, arranging, versions, tags, labels, indexes, etc.) and managing the data. This helps prepare your data for model training and fine-tuning, supplies real-time data for responsive generative AI applications and supports RAG applications.
Deep diving into these steps in more detail:
When the data is ready as indexed or featured data, it’s time to perform actions like:
The final aspect is managing metadata, which includes:
This pipeline ensures that the generative AI models are up-to-date and optimized for the specific tasks they are designed to perform. The Iguazio AI platform ensures an automated flow of adata prep, tuning, validating and LLM optimization to specific data efficiently using elastic resources (CPUs, GPUs, etc.). This includes:
Iguazio supports any open source or commercial LLM.
The application pipeline is responsible for handling user requests, sending data to the model so it generates responses (model inference) and validation that those responses are accurate, relevant and delivered promptly. The Iguazio AI platform’s application deployment pipeline ensures rapid deployment of scalable real-time serving and application pipelines that use LLMs (locally hosted or external) as well as the required data integration and business logic. This is the pipeline that brings business value to the organization. Deployment is supports across on-prem, hybrid and multi-cloud.
Constant monitoring and governance of all your AI / gen AI applications in production will ensure your applications are accurately working at peak performance. To do so, Iguazio provides a monitoring system pipeline for gathering application and data telemetry to identify resource usage, application performance, risks, etc. The monitoring data can be used to further enhance the application performance. On top of these, the Iguazio AI platform provides built-in monitoring for the LLM data, training, model and resources, with automated model re-tuning and RLHF.
Throughout these four pipelines, the Iguazio AI platform eliminates LLM risks with guardrails that ensure:
GPUs are often under-utilized due to inefficient resource allocation, data bottlenecks, complicated DevOps and limited support for use-cases beyond deep learning. The Iguazio AI platform provides provisioning capabilities that help customers use their GPU investments efficiently, saving heavy compute costs, simplifying complex infrastructure and improve performance.
Iguazio users can:
Iguazio operates with open source at its core, allowing users to future-proof their stack, integrate with any third-party service and maintain flexibility.
MLRun, the open-source AI orchestration framework built and maintained by Iguazio, manages ML and generative AI applications across their lifecycle. It automates data preparation, model tuning, customization, validation and optimization of ML models, LLMs and live AI applications over elastic resources.
MLRun enables the rapid deployment of scalable real-time serving and application pipelines, while providing built-in observability and flexible deployment options, supporting multi-cloud, hybrid and on-prem environments.
Iguazio also maintains Nuclio, the open source serverless framework used to minimize development overhead, increase performance and automate the deployment of AI applications. Nuclio’s capabilities support data ingestion, model training, deployments, resource optimization and more.
Responsibly fine-tune models with RAG, RAFT and more. Improve model accuracy and performance at minimal cost.
Optimize GPU resources by scaling usage up and down as needed.
Multi-cloud, on-premises and hybrid environments all supported.
Monitor AI applications, address regulation needs, remove PII, mitigate bias and more.

