How Seagate Runs Advanced Manufacturing at Scale With Iguazio
Alexandra Quinn | February 15, 2023
Transforming Manufacturing at Seagate: Using AI to Detect Defects on the Factory Floor
Seagate wanted to leverage their vast petabytes of sensor and image data to reduce chip manufacturing times and capital costs and maintain quality, but faced challenges:
- Efficient data processing methods (compute and orchestration) while handling petabytes of real-time data
- Long manufacturing cycles, with 40% of time spent on measurement
- Sampling, logistics and time limitations
With Iguazio, they were able to transition from a manual inspection process via microscope to fully automated deep learning and computer vision inspection.
By leveraging fully managed data engineering and automation, they were able to:
- Doubled first-pass wafer yield and eliminated contamination by automating measurement and implementing deep learning visual inspection steps
- Reduced manufacturing steps by 40%, thereby reducing capital costs by modularizing and streamlining data engineering processes.
- Improved cloud usage efficiency by 6x.
Business Background
Seagate is the world’s leading data storage solution. Together with Iguazio, Seagate is able to manage data engineering at scale while harnessing petabytes of data, efficiently utilize resources, bridge the gap between data engineering and data science and create one production-ready environment with enterprise capabilities.
In this new webinar, Vamsi Paladugu, Sr. Director of Lyve Cloud Analytics at Seagate explains about Seagate’s partnership with Iguazio, shares how Iguazio helped them overcome business and technical challenges and dives into a real-life use case where Iguazio helped leverage ML to improve productivity and cut costs.
Watch the webinar here.
About Seagate
Seagate is the data storage industry leader, powering the storage infrastructure for most of the world’s data. In its 40 years of existence Seagate has shipped more than three zettabytes of data. It employs more than 40,000 employees and its annual revenue is more than $11 billion.
Seagate operates across seven global manufacturing sites: in the US, the UK, China, Malaysia, Singapore and Thailand (which has two sites). Each site is equipped with nano precision technology and AI and practices smart manufacturing.
Seagate’s AI enables its factories to generate 50 terabytes of data per day, across sensor, parametric and image data. This data is analyzed and learned by descriptive and predictive algorithms that autonomously monitor the entire datasphere for use cases like anomaly detection, fault detection and sophisticated control systems.
How Seagate Manages Data Engineering at Scale Harnessing Petabytes of Data
With its expertise in data storage Seagate recently launched a live cloud, aptly named ‘Lyve Cloud’, which is a simple, trusted and efficient cloud storage platform designed for frictionless mass capacity storage. Their cloud is scalable, S3 compliant, always on, employs security best practices and complements other clouds. There are no egress, API fees or vendor lock-ins, either.
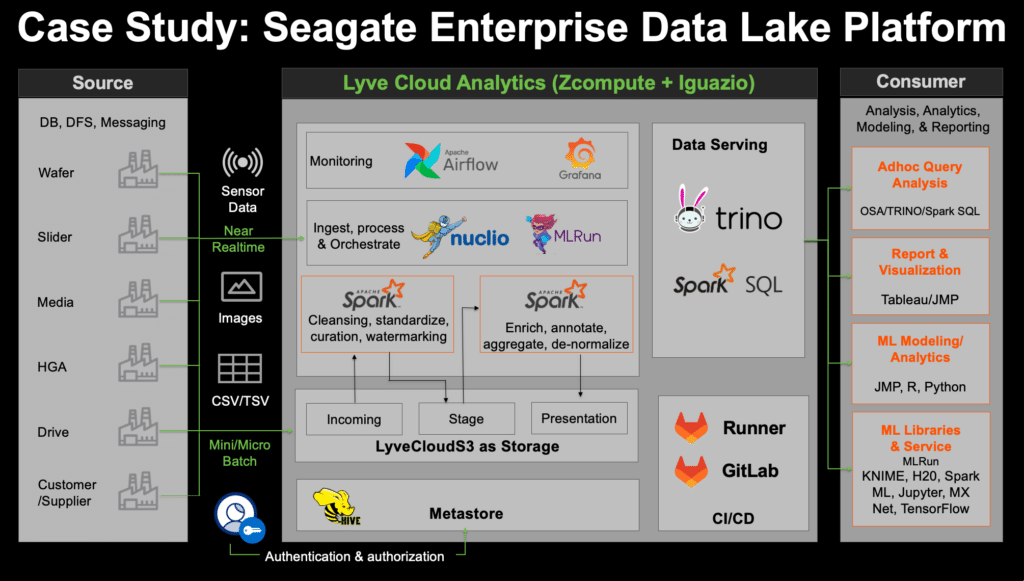
To address the complexities of big data processing and analytics, Seagate provides ‘Lyve Cloud Analytics’, a platform that is a combination of the infinitely scalable S3 together with a fully managed data engineering and automation MLOps platform, powered by Iguazio.
The resulting solution is a unified open data lake platform that provides data visualization and analytics. It is built up by industry-leading open source frameworks:
- For DataOps, i.e data servicing, data processing and data ingestion, Lyve Cloud Analytics leverages Nuclio, Apache Spark (provided as a managed service), Trino (provided as a managed platform) and Dask.
- For MLOps, it leverages Jupyter, MLRun, PyTorch, TensorFlow, Dask and Horovod. These tools provide end-to-end automation of machine learning processes, including experiment tracking, artifact governance and monitoring. This ensures reproducibility, reusability and seamless transition between development and production.
- For pre-built analytics accelerators, the solution utilizes time-series models, image analytics and tabular data analysis.
- The platform itself provides data storage, compute and orchestration, logging and monitoring and security and governance, through Kubernetes, Prometheus and Grafana.

The Seagate Enterprise Data Lake
Seagate ingests more than 50%-60% of the data coming from their factories as well as data that arrives from their customers and suppliers, into an enterprise data lake. They ingest data in batch or in real-time. The data lake is leveraged by various organizations across Seagate to help improve product quality, gain business insights and drive innovation.
To ingest data into their Lyve Cloud Analytics platform, powered by Lyve Cloud, Seagate uses various pub/sub tools. The tool of choice depends on the required scenarios. For real-time ingestion they use Kafka, for mini and micro batch ingestion they use Apache NiFi and internally built pub/sub models.
To process data at scale, Seagate uses Spark for ETL processing and data transformation. They also built frameworks and templates as best practices for scaling orchestration. As a result, they are able to process approximately 1500 tables of data, including data from sensors, parametric data and image analytics data. Approximately 70%-80% of use cases are batch and 20%-30% are real-time processing scenarios.
Seagate processes its data within a few minutes to a few hours, depending on the scenario and the factory. Some factories, like their Drive factories, generate huge volumes of data. In these cases, data latency is a little high because data consumption can wait for a few hours. Wafer factories, on the other hand, need real-time data for decision making.
Airflow is used for orchestrating and running DAGs, which continuously run as part of the process with various dependencies embedded. MLRun is used to trigger the integrations between the various processes. Users can build their own ETLs and querying engines to consume the data. This gives them freedom to create their own processes.
For data serving, Seagate uses Trino and Spark SQL. Trino is used for 80%-90% of use cases, since Trino provides them with 5x better performance than Spark SQL. Yet, Trino is less resilient, which impacts distributed queries. This is unlike Spark, which retries and continues to the next process, even if a query fails.
Seagate runs different types of analytics on the platform, including descriptive analytics and predictive analytics. Tools like Tableau and JMP are used for BI visualization.
ML solutions are used to accelerate the ML process to enable easy scaling for development to production. These include H20, SparkML, MLRun, and more. Deep learning solutions are used for projects like image analytics.
When it needs to run upgrades, Seagate has a pipeline based on Iguazio that upgrades the platform in a way that is completely seamless to the customer or the business users. When refactoring ETL frameworks, Seagate has a data governance process in place that enables them to coordinate between the different impacted teams.
The data platform leverages AWS S3, supporting both ORC and Parquet formats.
Case Study: Seagate Wafer Manufacturing
An example of a scenario that leveraged Iguazio’s AI and MLOps capabilities to improve product efficiency and quality is wafer manufacturing.
The Challenge: Reducing Measurement Steps
Seagate was dealing with a business challenge: out of the 2,500 steps required to produce one wafer, 1,000 are measurements steps. This means approximately 40% of the time is spent on measurement. This significantly increases cycle times and manufacturing costs.
Seagate’s objective was to reduce the number of measurement steps, as a way to decrease cycle time and capital cost, while maintaining product quality.
Some of the challenges with the process included:
- Traditional sampling does not capture multivariate complex wafers.
- There are only 30 seconds to select samples, with a requirement of <20 meters in downstream factories.
- Scaling the sample selection with over 4PB of AIOps is difficult.
The Solution: Smart-Sampling with Lyve Cloud and Iguazio
By leveraging Lyve Cloud and Iguazio, Seagate was able to:
- Understand their data and gain coherent data access and availability across multiple factories for scaling to 200 million sliders per quarter.
- Unravel their complexities and seamlessly deploy and integrate ML models across millions of diverse process configurations. Seagate uses automated feature engineering to identify features and seamlessly transition between different environments and versions and between development and production. Iguazio and Nuclio enable them to seamlessly deploy and scale across multiple operations with a few lines of code, while getting the inference from the models.
- Drive value through an open source framework that provides flexibility and freedom to move and utilize data between factories with no vendor lock-ins and egress costs. It also reduces technical debt. This helped reduce 40% of cycle times, increase efficiency and reduce TCO.
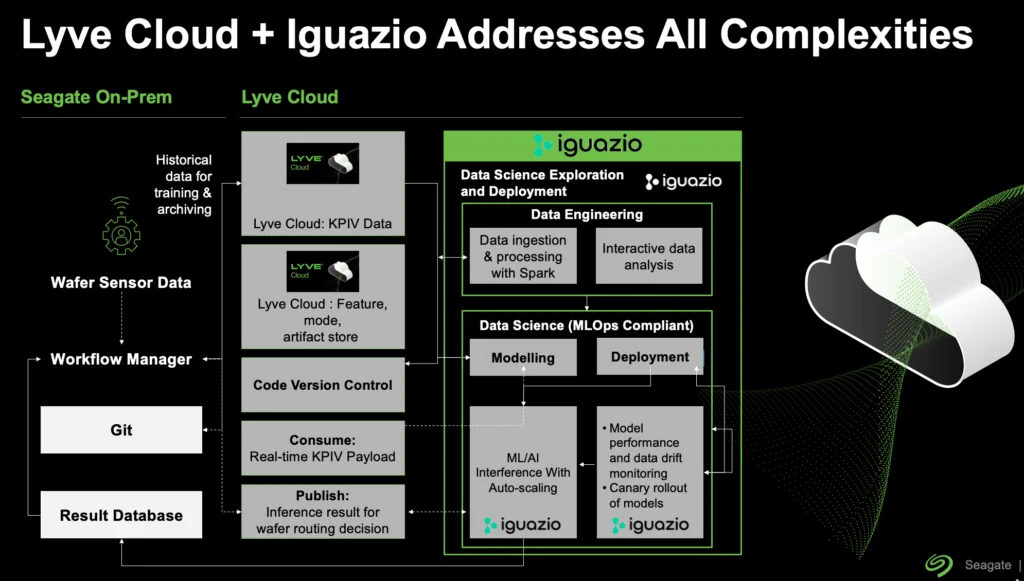
Spotlight: Lyve Cloud and Iguazio Address All Complexities
With Iguazio, Seagate was able to implement smart sampling. Sensor data coming out of wafer factories was ingested into the Lyve Cloud storage. Iguazio integrated with Seagate’s on-prem and cloud environments and governed the following processes:
- Data Engineering: Data ingestion and processing with Spark and interactive data analysis
- Data Science: Modeling, deployment, ML/AI interference with auto-scaling, model performance and data drift monitoring and canary rollout of models.
You can watch the entire webinar here.

