Operationalizing Machine Learning for the Automotive Future
Alexandra Quinn | July 13, 2021
It’s no secret that global mobility ecosystems are changing rapidly. Like so many other industries, automakers are experiencing massive technology-driven shifts. The automobile itself drove radical societal changes in the 20th century, and current technological shifts are again quickly restructuring the way we think about transportation.
The rapid progress in AI/ML has propelled the emergence of new mobility application scenarios that were unthinkable just a few years ago. These complex use cases require some rigorous MLOps planning. What is the ideal way to process data efficiently and cost-effectively in a connected car world?
Recently, Iguazio CEO Asaf Somekh moderated a panel on this topic, with experts Ken Obuszewski, the General Manager for Automotive Vertical at NetApp; Norman Marks, the Global Senior Manager for the Automotive Industry at NVIDIA; and Roger Lanctot, Director of Global Automotive Practice at Strategy Analytics to discuss some of the core challenges of AI for smart mobility use cases.
What they discussed:
- New technologies are driving a fundamental shift in how cars are used on a product level
- Data locality is a critical factor for most connected-car use cases
- Many smart-mobility use cases pose some rather big, as-yet unanswered questions around data governance
- 5G may be a significant enabling technology for the low-latency requirements of connected cars
The Car of the Near Future: Sometimes Autonomous, Always Connected
The term “connected car” means that our cars will be networked with the outside world—to other cars, to the OEM or to transportation infrastructure, for example. That connectivity will be used by the automaker to push updated AI and DNNs that will improve the autonomous systems, making it safer over time. Whether the car is operated autonomously or by a human driver, the fact that it is connected means that the vehicle and its driver will leverage data inside the vehicle for a variety of safety, maintenance or infotainment functions.
Technology-Driven Industry Transformation
This connectivity is fundamentally changing how the car is consumed on a product level. Advancements in AI and the evolution of the cloud and in-car compute are shifting the role that the automobile can play in our lives. Where drivers once received limited information from the vehicle, in the form of dashboard signals and telemetrics, data from the connected car has become a multidirectional communication flow, with data being pushed back to the OEM, as well as sent from an external data center to the car.
Automakers are eager to develop new business models as they adapt to macroeconomic factors and the emergence of new mobility services. This multi-directional communication flow is extremely valuable to automakers, who will become more than just machinery manufacturers, but data service providers. Once a modem is embedded in the car, an expectation emerges on the part of the customer that the product—that is, the car—will be more “intelligent.” This is great news for automakers, who can leverage this expectation to grow new business models, much like the data-subscription service OnStar. They can also receive direct product feedback from user interactions in much the same way marketers can analyze website visitor behavior. Whereas currently users can use their mobile device for infotainment functions like AI-driven navigation or music, smart safety features like AI driver assistance can only function in a connected car. This, then, is the turning point where data becomes a dominant issue in automotive—how we manage it, how we collect it, and how we transmit it in real time.
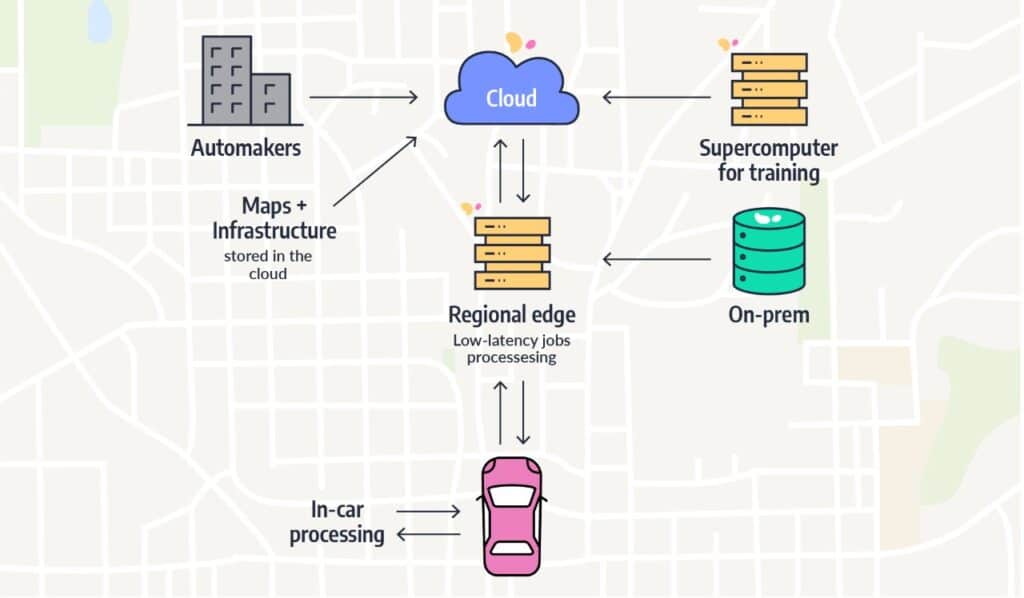
Data Locality
One of the key factors affecting the performance of any type of computing is data locality. In general, it is faster to move computation closer to the source, rather than moving the data. The need for ever greater performance, with real-time analytics and fast decisions, has meant that ML teams must find ways to avoid network congestion by optimizing data infrastructure. It is important to avoid slow-functioning components that will bring down the performance of the entire system. Fast decisions, required in applications like collision avoidance, don’t have time to go to the cloud and back, while the big data required for such decisions can’t be stored at the edge. There’s no magic formula for how to accomplish this. Thus, ML teams dealing with mobility use cases are tasked with deciding where the data will reside and where the computation will take place, based on each specific use case. The important thing is being able to choose where the data resides based on considerations pertaining to the use case, time constraints, cost and accuracy, and not because of software limitations.
The questions surrounding data locality are particularly complex for mobility use cases, because the data comes from so many disparate sources, overall latency is typically a critical factor, and the output is often sent to a moving object.
Some applications can be relatively straightforward, like lane-assist applications, which can be processed in-car, in a closed loop. Autonomous driving applications are at the other end of the spectrum of complexity. They can include geographical and traffic infrastructure data residing in the cloud, computer vision and radar data processed in-car, and still more data residing at the regional edge, all processed with ultra-low latency.
NetApp addresses these challenges with its data fabric approach, and a mature cloud product catalog, says Obuszewski. For mobility use cases—which often include a mix of unstructured, large, and ADAS data sets, and require hybrid and edge computing—data management is an extremely complex business. With NetApp, ML teams can manage data wherever is best: whether that’s the edge, or requires a move to the cloud for training, or if data is tiered and stored on-prem. Data can be generated in different geo locations, accessed by engineers across the globe. Whatever the use case demands, NetApp’s data fabric offers a holistic approach to managing data that is simple, secure, and efficient.
Closely related to data locality is the issue of data scale management. ML teams working on these challenges have to decide how to split heavy workloads between the cloud, on-prem, regional edge, in-car, and anywhere else data is residing. At the fleet level, the issues of scale are even more acute. A 50-car fleet, for example, generates two petabytes of data each day.
From a compute architecture standpoint, these large-scale use cases require three broad components, says Marks:
- A supercomputer for training
- In-car processing with the highest TOPS and lowest power possible (NVIDIA addresses this challenge with its AGX platform, including the NVIDIA DRIVE Orin system on a chip, delivering 254 TOPS)
- Strong computing sitting at the centralized edge or at regional data centers
To hear more from this conversation, watch the on-demand recording here.
Data Governance Questions
As automakers shift some of their investment from product ranges to software and service solutions, the industry will likely evolve more into selling a set of interactive experiences, rather than a performance machine, says Lanctot. It will be incumbent on automakers to sell the value of AI to end users, in order to convince them to share their data. Whether it’s satisfying the customer with Netflix-style recommendations or driver assistance apps, the automakers that deliver the best AI-powered interactions will win brand loyalty in a completely new product landscape.
Because these trends are still emerging, there are more questions than answers as brands and consumers navigate the data governance implications of this new ecosystem. In cases of accidents, how will data be turned over to insurance companies or legal entities? When cars move across borders, which government regulations will they be subject to? Will government regulations vary country to country, or will the industry come together to create standards?
Automotive dealers and manufacturers are becoming fleet operators, as the business model of car use changes. Ride-sharing applications may include data from the OEM, the fleet operator, insurance companies, and end users, and will raise tough questions regarding data management. Fleet operators will want to be able to analyze performance issues fleet-wide, and at the same time avoid annoying customers with false positives. In a sharing economy, fleets could be also private, with cars shared among smaller groups of neighbors or family members. If these data sources are managed in the cloud, and all those entities have access, then data access and privacy issues will also need to be addressed.
5G
With 143 commercial networks already live worldwide, 5G is the fastest growing mobile technology in history. 5G networks are 100x faster than 4G, making it a hugely impactful technology for connected car use cases where every millisecond is significant. Currently, many connected car applications are based on a combination of in-car processing on one end, and cloud processing on the other end. By the time the information gets to the cloud and the reaction is sent back to the car, the benefits of the application are lost in the overall latency of that back and forth due to sheer distance. For these types of low latency use cases, decisions need to be made closer to the data source (in this case, the car), so 5G will move many more workloads in the future. To make the most of 5G, enterprises need low-latency ML solutions that enable real-time performance.
Building the ML Tech Stack of the Mobile Future
No one can predict the future of the mobility sector with certainty, but it’s clear that connected-vehicle applications are driving a transformation in the way data is processed. Where previously processing was done in a centralized location, AV and connected car applications require a highly specialized combination of hybrid edge computing. Players in the market can make strategic investments now to shape the industry’s evolution. Sorting out the right technology stack and architecture now will help organizations stay competitive in a disruptive field.
To learn more about the Iguazio Data Science Platform, or to find out how we can help you bring your data science to life, contact our experts.

