Architecting BigData for Real Time Analytics
Yaron Haviv | March 17, 2015
BigData is quite new, yet when we examine the common solutions and deployment practices it seems like we are going backwards in time. Manual processes, patches of glue logic and partial solutions, wasted resources and more … are we back in the 90’s?
Can we build it more efficiently to address real-world business challenges?
Some Background First
It all began more than a decade ago, a few folks at Google wanted to rank the internet pages, and came with a solution based on GFS (Google File System) and a MapReduce batch processing concept. This concept was adopted by people at Yahoo who formed the Hadoop open source project. Hadoop key components are the same, a distributed file system (HDFS) and MapReduce. Over time more packages were added to the Hadoop and Apache family (some that are promoted by competing vendors, have significant overlap). Due to the limitations of HDFS a new pluggable file system API called HCFS (Hadoop Compatible File System) was introduced. It allows running Hadoop over file or object storage solutions (e.g. Amazon S3, CephFS, etc.), and the performance limitations of MapReduce led to alternative solutions like Apache Spark for processing and YARN for scheduling, those changes are quite substantial given HDFS and MapReduce were the Hadoop foundations. The original assumptions and requirements from Hadoop environments were quite modest not to say naïve;
- Data was uploaded to the system for batch processing – so no need to support data modification
- The entire data was scanned – so no need in incremental processing
- Data access was mostly sequential with very large files – no small random IOPs
- Job scheduling assumed jobs run for a limited time and finish
- When the name node failed, rebooting it wasn’t a big deal
- There was no need to secure the data – it was all internal
- Only one small group of analysts was running analytics – there was no need to manage access to the data
Well …things are quite different today
- Data needs to be extracted/ingested from variety of sources in real time
- Processing must be incremental … you don’t want to go over a petabyte on every update
- We deal with billions of data objects and some are pretty small
- We want to run over clouds or containers, not to be restricted just to dedicated hardware and disks
- It’s not all batch, Some jobs are running constantly and need to provide real-time updates
- High-availability and security are quite important – this data is becoming more and more critical for enterprises
So is Hadoop obsolete? How should we deploy it to overcome the challenges? Will get to it in a minute ..
If you wonder what about those Google guys, are they still using this technology? Well, not really, for the same reasons above they came up with a different solution called Percolator to calculate page ranking in an incremental and transactional way, and use a transactional database called Spanner for the Ad business, Seems like transaction semantics are inevitable.
How does Hadoop work?
The basic operation of Hadoop is reading large files (found on local file system or HDFS), manipulating them (map, filter, sort, shuffle, reduce, ..) in a distributed fashion, and generating new derived files with the results. In many cases there are multiple iterations of such read -> process -> write cycles until you get to the final results.

Typical Hadoop and MapReduce Flow
This means we read the ENTIRE dataset which can consist of terabytes of data. Maybe even repeat this a few times and only then generate a result. While it can deal with large volumes of data, use relatively low-cost disks due to the sequential IO nature, and can live with the limitations of HDFS (like no updates to files, performance hiccups, no full HA for name nodes, ..), this process can take quite some time to run. It is also rather inefficient when we have incremental data updates, or when we want to see results in real-time. There are partial SQL solutions that exist like Hive for analysis and HBase for key/value, but those are also quite slow due to the fundamental Hadoop architecture limitations, and are not fully transactional.
One way which was developed to ease the intermediate disk read/write overhead was the introduction of Tachyon memory cache file system solution infront of HDFS, but this only deals with the intermediate results. It’s not persistent and uses expensive memory resources. How do we deal with data stored on other systems? Well, in exactly the same way – we extract lots of data from the original database to a temporary CSV file, transform it to another decedent file, and load it up to Hadoop (HDFS). Every time we repeat this ETL process we generate more files, mostly repeating the same content just at different time snapshots, wasting quite a bit of time and disk space, and managing this manually or with ad-hoc scripts.
And how does this architecture deal with streams of data? Again using intermediate files – you run Flume which accepts streams or logs of data and converts them to files with a DD-MM-YY notation (on every new time range it generates a new file), and now we can start the same ritual of reading, processing and writing large files. Since Flume is not a real high-performance persistent messaging layer, we are forced to add yet another layer of Kafka to reliably store the flow of messages until they can be ingested into Flume, and from there to HDFS.
All that inefficiency just so we can process the incoming data in the Hadoop immutable files and MapReduce notation.
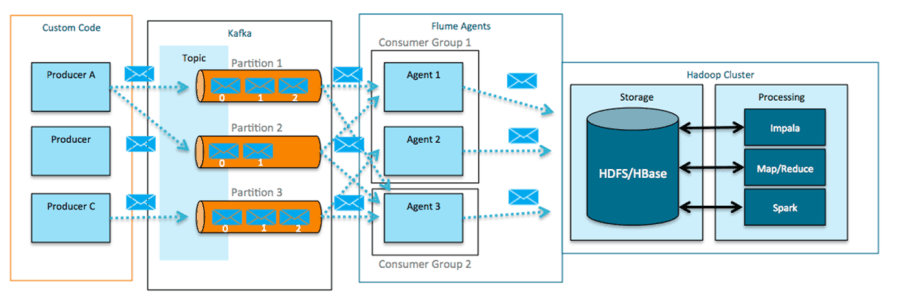
Example of Hadoop deployment with incoming data streams (source Cloudera)
So is Spark the alternative to MapReduce ?
Recently we see an uptake in a new and powerful in-memory processing solution called Apache Spark. It tackles the huge inefficiency of the iterative MapReduce process we covered above. The idea here is to load the ENTIRE dataset to memory and run the processing iterations in memory in a distributed and pipelined fashion. Data extracted from different sources like 3rd party databases or Twitter streams can be loaded directly into memory and avoid an intermediate disk read/write. Spark is capable of reading large datasets, filter, process, twist, and turn and generate a new derived dataset in seconds. This can be used to draw some nice charts in real-time or provide input datasets to other BigData tasks or tools.
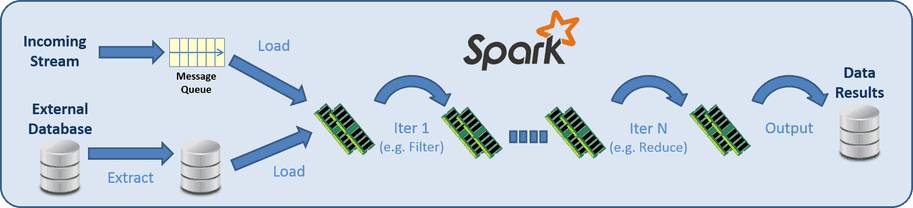
Data Analysis Flow with Spark
The way Spark works is that it remembers the order of execution (linage). On failures it can recalculate the missing parts instead of keeping a replica of the data and state. For long calculations it can checkpoint intermediate results – this way it doesn’t need to calculate everything from scratch in case of a failure. Spark provides an integrated SQL interface for analytics (doesn’t support updates) as a faster alternative to Hive, and built-in libraries for Machine-Learning, Streaming and Graphs.
The challenge with Spark is the need to store the entire dataset in memory, and run over all the data, as opposed to read and process only relevant data. This is a challenge since memory and additional servers are quite more expensive than disk or even flash. Spark also lacks key database semantics like record updates, indexing, and transactions, so it is mostly applicable to analyzing medium sized datasets as a whole, or iterative machine learning, not for incremental updates to stored data records or for processing data in the tens of terabytes or more.
Combination of Spark in-memory processing with batch oriented jobs for digesting large data, and with a transactional record storage for storing intermediate results and doing random updates can help addressing a broader set of applications. As an example Google Percolator addresses the problem of continuous and real-time updates to a very large dataset by processing the incremental changes in a given time period and merging it with a very large existing dataset through the use of update transactions to indexed data. Such an approach to real-time analytics can be implemented by combining Spark with a persistent and transactional key/value storage.
Summary, what should be the key BigData solution elements?
It seems like today we cannot use a single product or strategy when building BigData solutions. We need to include several components, as illustrated in the following diagram
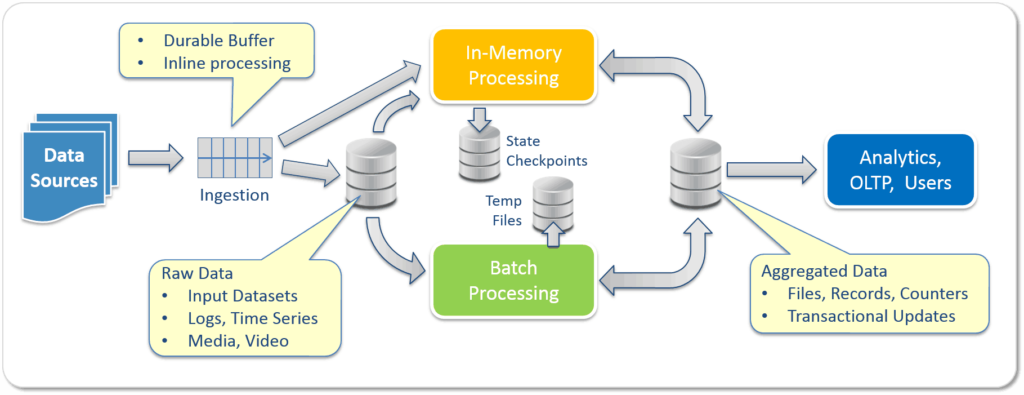
Common BigData Deployment Architecture
In a complete solution we need:
- Scalable and High-speed messaging layer for ingestion (e.g. Kafka)
- Stream or In-memory processing layer (e.g. Spark)
- Batch processing for crunching and digesting large datasets (e.g. MapReduce)
- Interactive Real-Time Analytics and SQL tools for presenting the data
A critical part in the solution is having a shared High-Volume and High-Velocity data repository which can store messages, files, objects, and data records consistently on different memory or storage tiers, provide transactions semantics, and address data security aspects. Unfortunately HDFS is not quite there yet, forcing us to build complex and inefficient solutions. For example a combination of Kafka + Flume + HDFS, or placing Tachyon over HDFS, or storing multiple copies of data to overcome HDFS’s limitations (limited velocity, no transactional updates and versioning support, etc.), today’s data copy & paste approach is in the way of real-time analytics, and we need to move to a real-time data sharing model.
Another key issue to address is data access control in each step and transformation along the data analysis path, and making sure users or applications can’t read or manipulate data they are not supposed to access – but this topic deserves a separate post. Stay tuned for the next one.

