Continuous Analytics: Real-time Meets Cloud-Native
Yaron Haviv | March 15, 2017
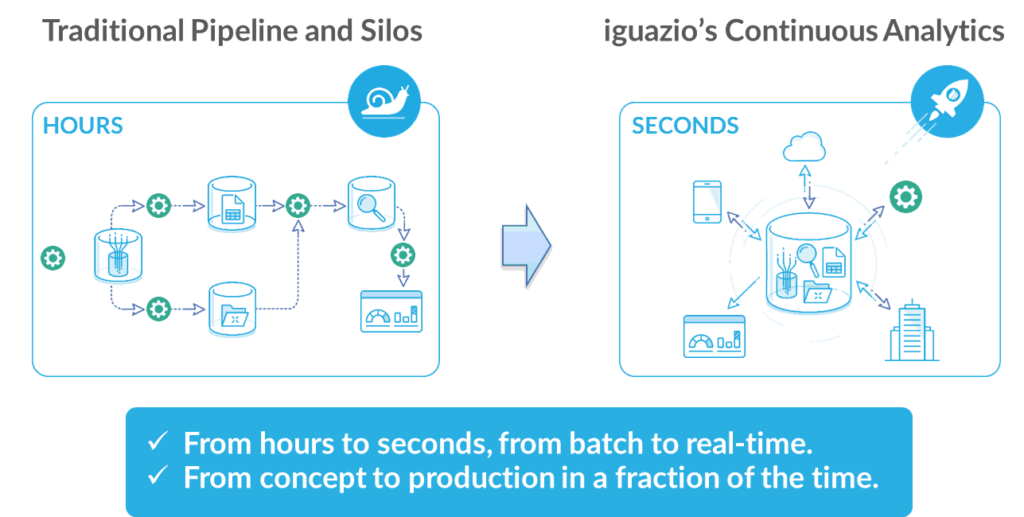
iguazio combines real-time analytics, concurrent processing and cloud-native agility. We started working on this completely new approach to data management after witnessing countless customers struggle with traditional big data and analytics solutions. As a result, we are seeing that iguazio’s platform leads to magnitudes faster time to insights, faster time to market, greater simplicity and robust security. This post provides information and details about one of the demos we are using this week at Strata + Hadoop World in San Jose.
Continuous Analytics in a Nutshell
Traditional big data solutions involve building complex data pipelines that have separate stages for collecting and preparing data, ingestion, analytics, etc. Pipelines are serialized: they involve many data transformations and copies, requiring different tools and data repositories for each stage. These solutions are complex to develop, require too much time to generate insights, are an operational nightmare and are vulnerable due to security gaps.
Continuous analytics is better. Data is ingested, enriched, analyzed and served simultaneously to/from the same data repository. Various micro-services and processing frameworks access the data concurrently, each making its own real-time adjustment. They add insights, or query in parallel and data doesn’t move. Results are always up to date.
Processing is 100% stateless and updates are atomic in continuous analytics. This means we can elastically scale processing, add new applications and change versions on the fly in an agile cloud-native manner, allowing for rapid development and continuous integration.
Since data doesn’t move, it is just enriched and enhanced. It’s also simpler to secure and audit all platform data access with fine-grained controls over any application or user, accessing any data fields.
Use Case: Real-Time Surveillance
The following use case, demonstrated live with our Strata+Hadoop demo, shows how images are collected in real-time from camera sources. Data is enriched and analyzed in real-time using an event driven approach and generated insights are explored interactively using Spark and Zeppelin. Insights are viewed using real-time dashboards. Actions are triggered automatically, based on changes to the data. For example, a (missing) person's record can be tagged to trigger a notification once updated.
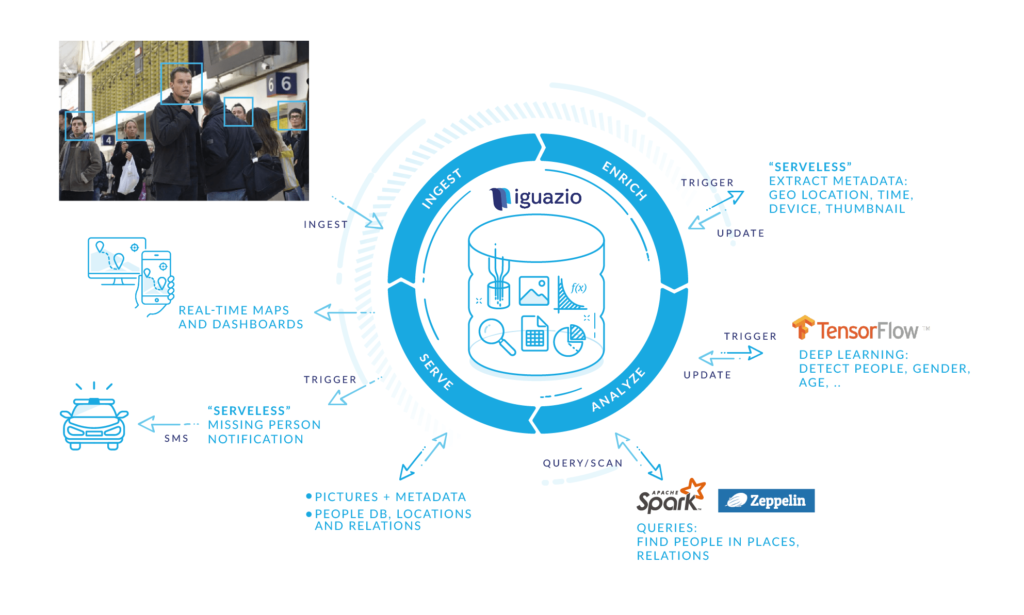 Data is semi-structured from the first step to simplify and accelerate analytics. Pictures contain auxiliary metadata which evolves with processing – for example, some apps extract geo location and simple image metadata and enrich it, while others form deep learning to extract information about the people, objects and relations in the pictures. Unlike the pipeline approach, processing steps run concurrently and each process updates specific fields/columns. Processes use atomic, transactional or conditional operators to guarantee they don’t conflict with other tasks. Processes add tags to data, indicating completion and guaranteeing the same task doesn’t run twice.
Data is semi-structured from the first step to simplify and accelerate analytics. Pictures contain auxiliary metadata which evolves with processing – for example, some apps extract geo location and simple image metadata and enrich it, while others form deep learning to extract information about the people, objects and relations in the pictures. Unlike the pipeline approach, processing steps run concurrently and each process updates specific fields/columns. Processes use atomic, transactional or conditional operators to guarantee they don’t conflict with other tasks. Processes add tags to data, indicating completion and guaranteeing the same task doesn’t run twice.
The atomic nature of updates enables stateless and elastic processing. We can add worker processes if we need to, upgrade to newer versions, or safely reboot an instance without interrupting the entire service.
Using Cloud-Native and Event-Driven (“Serverless”) Processing
Continuous analytics leverages cloud-native and agile CI/CD notions to simplify development and operations. Every micro-service or process is packaged in Docker containers which start or scale dynamically. Data or configuration is accessed using simple resource bindings and URLs making those containers lightweight and stateless. These micro-services are orchestrated dynamically using cluster managers such as Kubernetes.
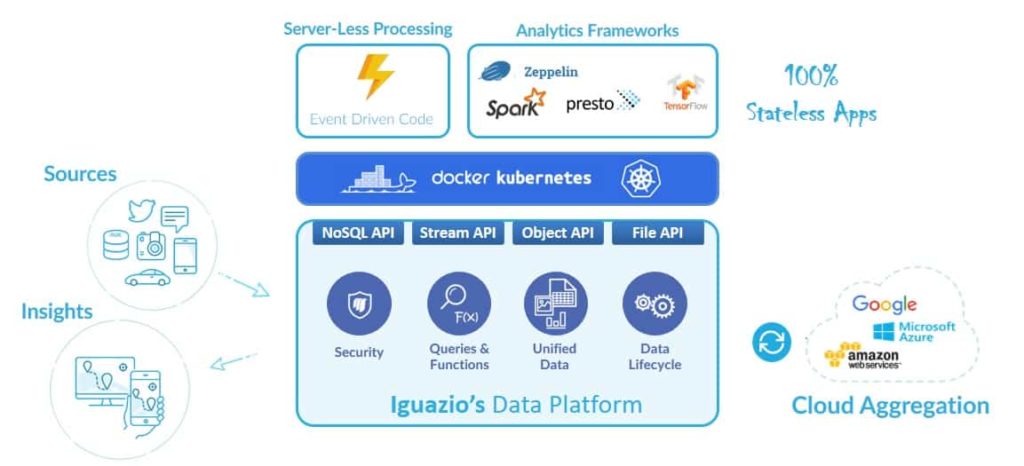
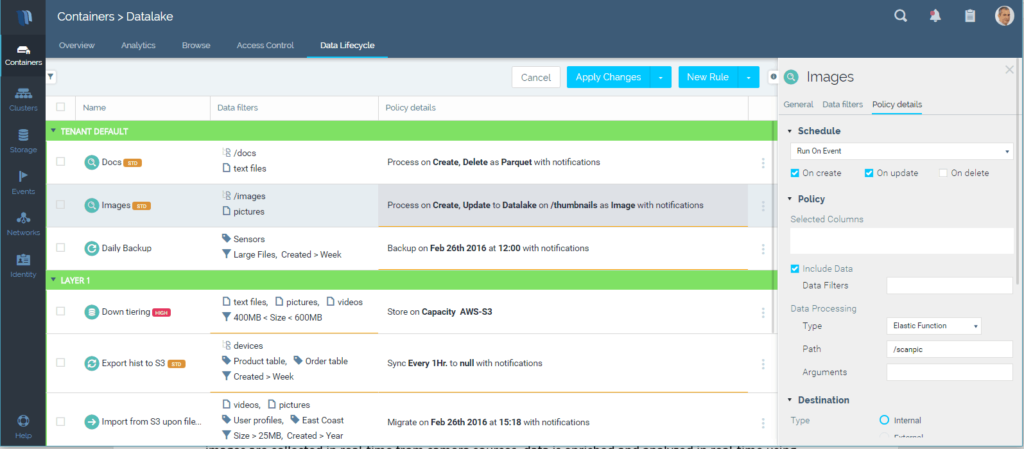
Some micro-services or functions are lightweight – all they need is to trigger on an event, run relevant processing and terminate. We elastically scale processing to multiple micro-service instances when several events happen concurrently. iguazio’s platform has built-in event-triggering and “serverless” functionality. Users define “data lifecycle” policies which automatically invoke micro-services or elastic-functions based on changes to the data, API calls or pre-defined schedules like Amazon Lambda. Selective data and metadata is pushed into the function in order to shorten latency. Those functions are used, for example, to trigger image processing or alert tasks. Data lifecycle rules track execution state and guarantee tasks only run once. They provide elasticity by leveraging built-in table and stream sharding capabilities (meaning events are distributed consistently across multiple worker instances).
Some processes are continuous, or micro-batch oriented like Spark. These run as Kubernetes jobs or “deployments,” which are scheduled dynamically on the cluster. Developers bundle multiple services in Helm packages (e.g. Spark master, workers and Zeppelin) and deploy an entire package in one operation. Cluster managers like Kubernetes have a clear advantage over the traditional Hadoop YARN scheduler since they are more generic and can manage any processing task. They are also designed taking modern cloud-native architecture into account.

Enabling Secure Data Sharing
Security is a major concern when data is shared among business units, applications and users. We must ensure that each role is exposed only to relevant data records and fields, and data access is audited. Granular security is only possible if data has structure and metadata, and when identity and security are enforced end to end. This is almost impossible with traditional approaches as they’re based on unstructured data, consisting of multiple silos and non-integrated stacks.
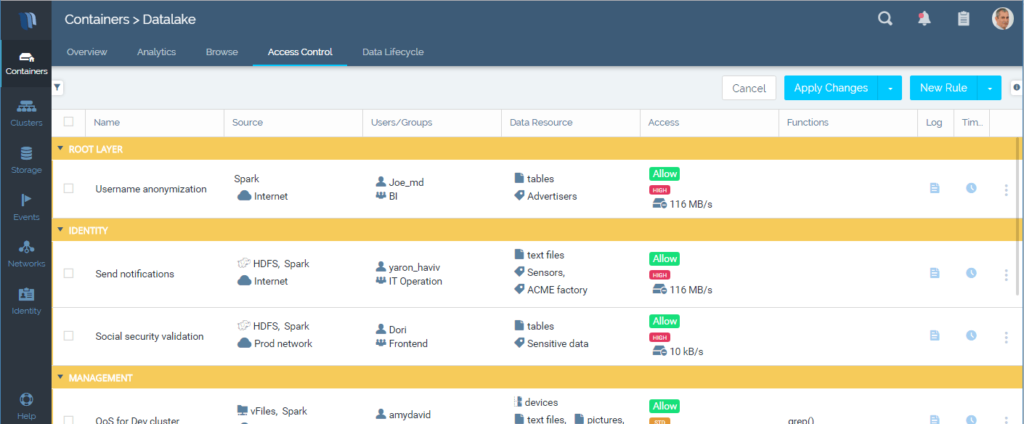
iguazio has a built-in, fine-grained data firewall that enforces policy based on role, context, fields and content. It works at a line rate of 100Gb/s and allows strong security without degrading performance so that organizations can safely share data and eliminate partial or redundant copies.

