Iguazio Releases Version 2.8 Including Enterprise-Grade Automated Pipeline Management, Model Monitoring & Drift Detection
Adi Hirschtein | June 2, 2020
Overview
We’re delighted to announce the release of the Iguazio Data Science Platform version 2.8. The new version takes another leap forward in solving the operational challenge of deploying machine and deep learning applications in real business environments. It provides a robust set of tools to streamline MLOps and a new set of features that address diverse MLOps challenges.
This version takes another step in making the transition from AI in the lab to AI in production much easier, faster and more cost-efficient. Version 2.8 also includes the enterprise-grade integration of our open source project for E2E pipeline automation, MLRun, as a built-in service providing a full-fledged solution for experiment tracking and pipeline automation. Note that this integration is still in its early stages and is currently being released as a tech preview.
Version Highlights:
Next Level ML Pipeline & Lifecycle Automation
The current trend in data science is to build “ML factories,” which, much like in agile software development, consists of building automated pipelines that take data and pre-process it, and then train, generate, deploy and monitor the models. Iguazio has embedded the Kubeflow pipeline 1.0 within the platform as part of its managed services.
Once you have a workflow, you can run it once, at scheduled intervals, or trigger it automatically. The pipelines, experiments and runs are managed, and their results are stored and versioned. Pipelines solve the major problem of reproducing and explaining the ML models. They also enable you to visually compare between runs and store-versioned input and output artifacts in various object or file repositories.
A major challenge is always running experiments and data processing at scale. Iguazio-managed pipelines orchestrate various horizontal-scaling and GPU-accelerated data and ML frameworks. A single logical pipeline step may run on a dozen parallel instances of TensorFlow, Spark or Nuclio functions.
Functions Marketplace
In an effort to streamline the process of creating a machine learning pipeline, version 2.8 includes a marketplace for functions. This marketplace enables you to easily search for components, which can then be added to a pipeline, much like LEGO bricks. In many pipelines, the same building blocks are required in various places, sometimes with slight tweaking alone. So having a one-stop shop for functions can make the process of building ML pipelines much easier and faster.
Version 2.8 includes a public functions marketplace, and we encourage our customers to start using this marketplace to save time and the duplication of efforts, as well as to contribute their own functions for the benefit of the community. Users who prefer to work on a private marketplace have the option of creating their own marketplace (essentially a Git repo) for added security and privacy.
Check out the public marketplace here: https://github.com/mlrun/functions
In addition, Iguazio simplifies the pipeline automation by making the Kubeflow pipeline a completely integrated service within the platform. You can create a complicated pipeline, running a variety of frameworks and functions in a way that eliminates any need for DevOps. Essentially, the pipeline comprises functions which can be either data engineering or machine learning functions. The integration of MLRun and Kubeflow pipelines enables you to take a function and easily run it on a scalable cluster and even convert Notebook code into a function in one line of code. This new approach dramatically accelerates the time to market for building new ML services.
An example of an automated pipeline
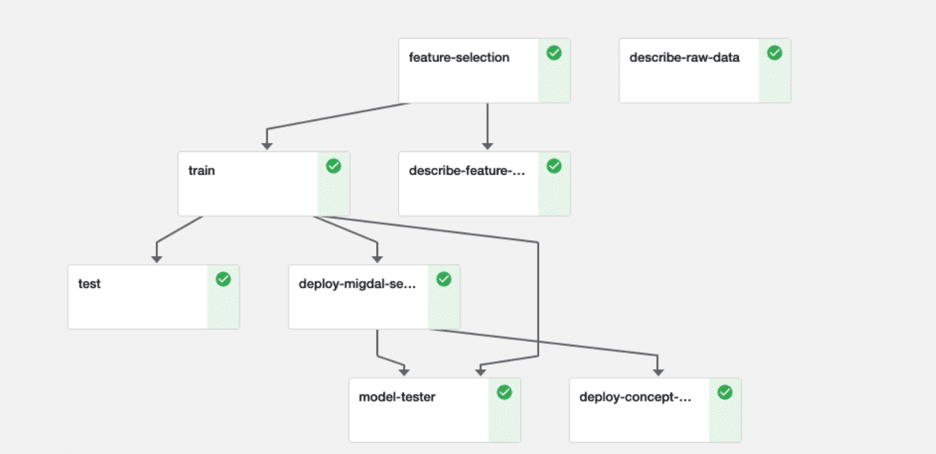
Running Python at Scale
One of the key operational challenges in a typical data science environment is how to take Python code that was written in the lab and make it ready to run on an operational cluster as a distributed process. Usually this requires significant DevOps time to accomplish. Version 2.8 gives users better performance at scale, in a simplified way. With version 2.8, you can easily convert your Python function to a job running as one or more pods in a Kubernetes cluster, with minimal coding.
The new enterprise-grade integration with MLRun enables this abstraction with just a few lines of code. We've done all the hard work of converting the code to a YAML and enabling it to run as a container with all the dependencies on a Kubernetes cluster, so you can focus on the code itself without worrying how and where it will be running.
MLRun is well integrated with other Iguazio services, and since Iguazio already has built-in distributed frameworks such as Dask and Horovod as a part of its solution, users can select a favorite framework for running functions. For example, you can run machine learning jobs as a distributed Python code or deep learning jobs by leveraging Tensorflow and Horovod. The platform also frees up resources once the jobs are done, reducing costs and making the process more efficient.
You can leverage those frameworks as part of your pipeline and run your jobs on a distributed cluster, thus, dramatically accelerating experiment time.
Transparent Model Rollout with Canary Code Deployment
This feature enables users to create a single endpoint that receives requests and routes them to one or more functions. It means that users can create an endpoint with a function running on a specific model and when a new model is ready they can assign a second (i.e. canary) function to the endpoint, set the rate of traffic that goes to that function, and gradually promote the second function to be the primary function as an online rolling upgrade operation without any application downtime.
Given that users can control the percentage of requests going to the primary and the canary functions, they can test the new model with minimal impact on production.
As part of creating the endpoint (AKA API gateway), users can also set an authentication layer for any endpoint, providing a security layer to it, meaning that only authorized users can then execute requests to those endpoints.
Detecting & Remediating Concept Drift in Production Automatically
At this point you’ll have a model, so the next steps would be to manage and monitor it in a real operational pipelines. Before deploying or operationalizing data science into real-world scenarios, AI and ML models need to train on mountains of raw data. However, there’s a catch — once these models are deployed, although they continue to learn and adapt, they are still based on the same logic they were originally built on. Models in production don’t account for variables and don’t factor in evolving trends in the real world.
Data scientists need to leverage MLOps automation to detect, understand and reduce the impact of concept drift on production models, and to automate as much of the process as possible.
MLOps enables data science teams to leverage change management strategies to either:
- Continuously update models once new data instances are received
- Update models once a concept or data drift is detected
With this, you can obtain new data to retrain and adjust models, even if the new data set is considerably smaller. Where possible, teams can create and engineer new data in a way that accounts for missing data.
Iguazio provides a mechanism to capture the input features that are sent to the model along with the model output and then compare it to the actual results in real time. Next, you’ll show it in a dashboard and capture the data over time for analytics stored on Parquet files. In this version, Iguazio leverages its core assets, such as streaming engine, fast time series data and Nuclio as its serverless framework, along with new concept drift functions that can be found in the Functions marketplace, for helping users to easily build a real-time concept drift detection without any data engineering!
Iguazio also provides the option to set thresholds for drifting and to receive alerts or slack messages upon drifting events.

End-to-End Tracking & Versioning Across Artifacts, Resources, Experiments, Data & Code
In this version we are introducing a new set of capabilities providing a single pane of glass for tracking all experiments along with the data, code and metadata per project. This is a full end-to-end tracking mechanism that enables users to have a holistic view of all their activities within a data science project for both research and serving.
Experiment Tracking
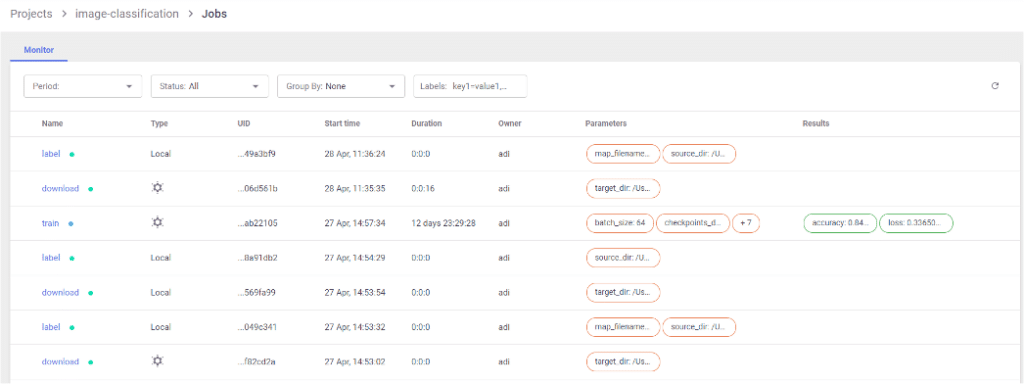
Version 2.8 includes a new mechanism for tracking experiments. This feature enables users to store all actions and results of every project. Users can track any job, whether it is a machine learning or an engineering job, along with useful information and metadata such as the job name, status, duration, parameters, labels, model accuracy, metric artifacts, etc.
It also provides a convenient way for comparing experiments to enable the user to easily find the best experiment for a given task.
When using experiment tracking, you don't have to worry about saving your work as you experiment with different models and various configurations. You can always compare the different results and choose the best strategy based on your current and your past experiments.
Experiments are also a great way to collaborate. Your colleagues can review the steps you took and test other scenarios on their own, while building on top of your work.
Finally, experiments are useful to show your work to any reviewer. This is useful to allow other people to review your work, and ensure you have not missed anything and that your models were built based on solid methods as well as verifying you have considered other options in your work.
Note that with Iguazio, users can run and manage not only typical machine learning jobs but also other jobs that are part of the operational pipeline. For example, data preparation and enrichment jobs would also be captured here.
Viewing jobs and pipelines
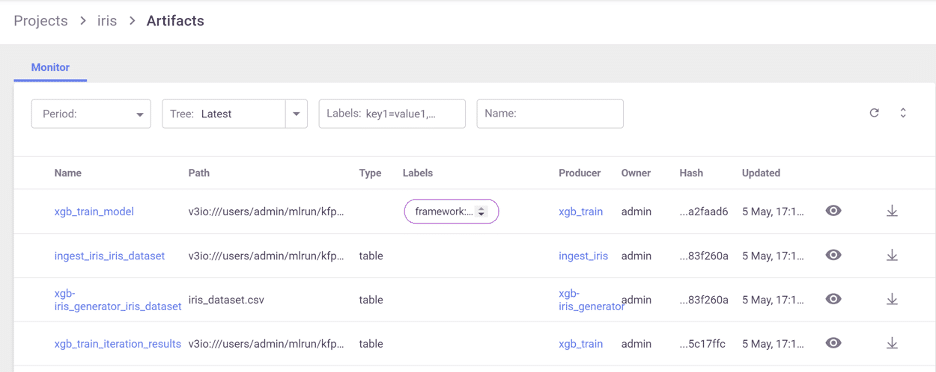
Artifact Management & Versioning
With version 2.8, teams have full visibility not only to all the jobs running in the system but also to all the artifacts in your projects. Users can now easily view and manage their dataset, models, plots and any other file that is a part of their project, in one place.
In addition to storing and tracking artifacts and their metadata, Iguazio’s Data Science Platform also manages versioning for code and dataset. This means that at any point of time users can view the exact version of the dataset they were using while running a certain training job. In AI, models and data are coupled together so the ability to know exactly which data was a part of a given experiment make it extremely valuable addressing one of the painful issues in data science operational practices. In addition, Iguazio has a built-in integration with Git so users can keep working with Git as their main version control tool and keep tracking the code usage per experiment.
Further Enhancement of Scale & Performance
In this version Iguazio introduces significant performance improvements around data ingestion and read operations from the platform streaming engine as well as its time series database. The performance improvements strengthen the Iguazio offering with a very compelling TCO (total cost of ownership) for demanding workloads. It enables customers to ingest and analyze millions of events in real time with much less resources than any other alternatives without compromising scale and flexibility. The platform enables users to work with the data format that is right for their job (e.g. key value, time series or columnar) and then run real-time predictive models on top of this data with very low latency response time.
We’ve started to see a significant performance improvement for demanding workloads in the serving layer for our v2.8 early adopters.
Additional Features:
Enhanced Resource Management When Working with Jupyter
We all understand the importance of managing our resources in an optimized and effective way. However, with Jupyter it’s a bit tricky as it’s a common scenario for users to spin up a Jupyter Notebook, consume resources and leave it up in the air, consuming resources even if nothing is running. With version 2.8 we are introducing a new option for users to automatically scale down their Jupyter resources after Jupyter has been idle for a period of time, as a part of the service setting. This keeps costs down and delivers a more efficient use of resources. It is prominent when working with GPUs as this is an expensive resource and customers are struggling to better utilize it. The scale to zero feature allows customers to free up those expensive GPUs once the Jupyter notebooks are idle.
Enhanced Troubleshooting with a New Set of Performance Monitoring Reports
In version 2.8, we've added a new set of performance monitoring reports to show the health of the Kubernetes cluster. For the cluster admin, we've added a complete and comprehensive set of reports showing statistics on the node level, pods, cluster capacity, server health, etc.
These reports are based on the Nvidia DeepOps library and provide a very comprehensive set of metrics and charts including GPU statistics. For the application users, we also added new charts improving the way users can monitor their services and Nuclio functions, Iguazio’s open-source serverless framework, in real time. GPU statistics are added as well.
Better Collaboration with the Introduction of Projects
In order to enable easier collaboration between teams and create a more methodological workflow, based on all of the features mentioned above, Iguazio is introducing “Projects”, a new way for users to organize all of their assets under a logical entity called Project. All the associated code, jobs, functions and artifacts are organized within the projects. The project is served as a workspace containing all the relevant objects of a given application. It provides an easy interface for collaboration and managing applications under a single pane of glass.
The new UI includes three main sections for each project:
- Jobs and pipelines: This view shows current and historical jobs and pipelines under your project. Jobs can be anything from complicated machine learning tasks to simple data engineering jobs. Pipelines consist of several steps running various tasks. A typical pipeline is comprised of data collection, preparation, feature selection, training and model testing, all the way down to model deployment and model drift detection.
- Artifacts: An artifact is any data output that is produced or consumed by functions in your project. Artifacts are versioned and enable you to compare different outputs of the executed Jobs. The platform supports various types of artifacts such as models, datasets, plots, etc.
Functions: A software package with one or more methods and runtime-specific attributes (such as an image, command, argument and environment). The code in your project is stored in functions. Functions can be new functions that were written as part of the project or functions that were imported from the functions marketplace.
Summary
Version 2.8 includes an exciting set of features that take building and managing operational machine learning pipelines to the next level. We’ve introduced a new set of functionalities around MLOps automation which assist in solving complex challenges in bringing AI to production. And this is only the beginning. Stay tuned for what’s coming next!
Want to try our new version? Click here for a free trial in the cloud.


