Serverless: Can It Simplify Data Science Projects?
Yaron Haviv | April 25, 2019
How much time do you think data scientists spend on developing and testing models? Only 10%, according to this post by Google’s Josh Cogan. Most of their time is spent on data collection, building infrastructure, devops and integration. When you finally build a model, how long and complex is the process of delivering it into production (assuming you managed to get that far)? And when you finally incorporate the models into some useful business applications, how do you reproduce or explain its results? Do you monitor its accuracy? And what about continuous application and model upgrades?
One way to simplify data science development and accelerate time to production is to adopt a serverless architecture for data collection, exploration, model training and serving.
This post will explain serverless and its limitations, and provide a hands-on example of using serverless to solve data science challenges.
Serverless Overview
The term “serverless” was coined a few years ago by Amazon to describe its Lambda functions, a service where developers write some code and specification and click “deploy.” Lambda automatically builds a containerized application, deploys it on a production cluster, and provides automated monitoring, logging, scaling and rolling upgrades. Other benefits of serverless are a lower cost pay-per-use model and its native integration with platform resources and events.
Overall, serverless addresses three main data science challenges:
- It reduces the overhead and complexity of developing, deploying and monitoring code. Serverless leads to a faster time to production and allows both data scientists and developers to focus on business logic instead of instrumentation and infrastructure-related tasks.
- It provides a well-defined and versioned runtime which incorporates the code, software package dependencies, ML models, environment variables, and data sources and run-time configuration. This can guarantee consistent and reproduceable results.
- Serverelss allows mobilizing, scaling and duplicating functions to multiple enforcement points. A good example we see at Iguazio relates to developing and testing functions in the cloud and then running them in edge gateways or multiple regions, or just scaling them to meet growing traffic.
Serverless has gotten a lot of buzz and wide adoption among app and front-end developers. We see it being used opportunistically in some data science pockets, but it has yet to reach wide adoption among data scientists.
Serverless can address many of the data science challenges outlined above, so I’m surprised that Amazon, the inventor of “serverless,” is not using Lambda in SageMaker, Amazon’s own data science platform. Have you wondered why?
The reasons are simple! The first wave of serverless functions, such as Amazon Lambda, aren’t a good fit for data science because:
- They are stateless and data science is usually about lots of data (state).
- They are slow and single threaded, while data processing requires parallelism.
- They limit the function image size and ML models tend to be large (larger than Lambda’s maximum image size limit).
- They don’t support GPUs and GPUs can be quite efficient in AI/ML applications.
- There is no native integration between data science tools/frameworks and serverless.
But all the above limitations are associated with cloud vendor specific serverless implementations, not serverless in general. Other implementations do provide serverless benefits while addressing data science needs.
Nuclio, Serverless Optimized for Data Science
Nuclio was designed from inception as an open source project that addresses data science applications and eliminates the complexity of development and operations. Nuclio provides extreme performance, supports stateful and data intensive workloads, supports and maximizes the efficiency of GPUs, and doesn’t come with any “baggage” holding it back.
Nuclio runs over the widely adopted Kubernetes orchestration layer and is integrated with various data-science and analytics frameworks.
Nuclio uses a high-performance concurrent execution engine (supporting up to 400,000 events per process). It is currently the only serverless framework with GPU support and fast file access, which enables accelerating the performance of machine learning code and maximizing the utilization of CPUs and GPUs (using a resource pooling model) so that code runs faster on Nuclio.
One of Nuclio’s coolest features is its integration with Jupyter, the most widely used data science workbench. This allows developers to automatically turn data science code and notebooks into scalable real-time functions, which provide data integration, versioning, logging, monitoring, security and out-of-the-box scalability without requiring any additional coding.
Nuclio is used in wide variety of data science tasks:
- Data collectors, ETL, stream processing
- Data preparation and analysis
- Hyper parameter model training
- Real-time model serving
- Feature vector assembly (real-time data preparation)
The following example demonstrate how to develop, test, and deploy functions from a notebook. The source, more detailed documentation and variety of examples are available in the Nuclio-Jupyter git.
Implementing a Natural Language Processing Function
See the full notebook in this Github link.
The first step is to deploy Nuclio on Docker or Kubernetes. See instructions on how, or just use the hosted version.
Now install the python and Jupyter SDK in your notebook using:
!pip install nuclio-jupyter
We write and test our code inside a notebook like any other data science code when working with Nuclio-Jupyter. We add some “magical” commands to describe additional configurations such as which packages to install, how the code will get triggered (http, cron, stream), environment variables, additional files we want to bundle (e.g. ML model, libraries), versioning, etc.
We use the deploy command or API to automatically convert the notebook to code, and then deploy it in a containerized function. Code cells we want to exclude from the function are marked with a “# nuclio: ignore” comment.
The following section demonstrates the import of a Nuclio library (in an “ignored” cell), followed by the specification of the packages to install, setting of environment variables and building configuration (e.g. indicating the base Docker image).
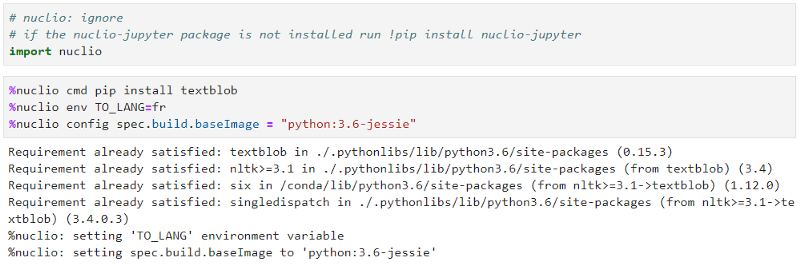
The next section is implementing our code which accepts some text from the trigger (e.g. HTTP POST request) and uses the “TextBlob” library to correct, analyze sentiments and respond with the text translated to another language (language is specified by the environment variable).

Once we implemented our code, we test it inside the notebook using a mocked context and event objects. Note that our code was instrumented with logs which are also displayed while debugging.
The next step is to deploy the function onto our cluster and serve real user requests — using a single “deploy” command. Once the deploy process is complete, it will also provide a URL allocation for the function, which we can then use to test our fresh function.
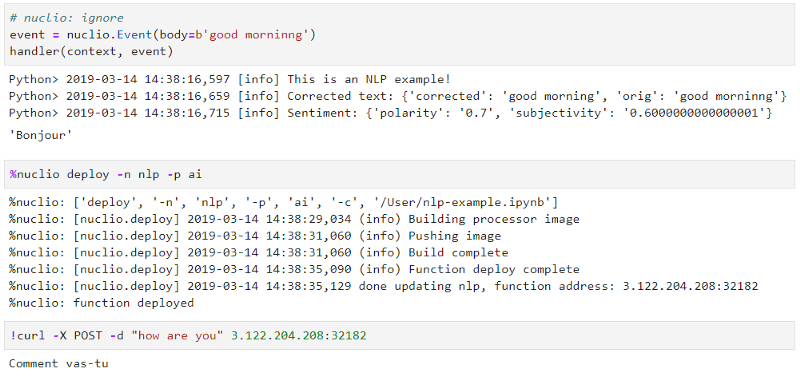
The example demonstrates how to create code in a familiar data science environment. We used a few magic decorations to specify our production requirements (package dependencies, environment and configuration) and we deployed it to a production cluster without thinking about the underlying infrastructure.
This was a simple example. More advanced function examples can be found in the following repository, including implementations of Twitter and stock data collection and analysis, image recognition and predictive infrastructure monitoring.
Nuclio is not limited to Python code. It supports 8 coding languages and allows us to choose the right and most familiar tool for the job. See this example for how to turn a bash script into an interactive serverless function with a few trivial steps and without any knowledge of Docker.
Summary
Serverless allows us to focus on data science logic! It makes our code production ready. Functions are instrumented with structured logging. They are hardened for security and they provide automated scale-out and scale-up to maximize performance and resource efficiency. Given that functions are containerized artifacts, we can develop and test them in one place and later deploy them to one or more other locations (e.g. on edge devices or regional clusters). More on that in another post.
Try it out and go to Nuclio’s community Slack channel if you stumble into any issues.
(This post was originally published on Towards Data Science.)

