The Next Gen Digital Transformation: Cloud-Native Data Platforms
Yaron Haviv | August 2, 2016
The software world is rapidly transitioning to agile development using micro-services and cloud-native architectures. And there’s no turning back for companies that want to be competitive in the new digital transformation.
Evolution in the application space has a significant impact on the way we build and manage infrastructure. Cloud-native applications in particular require shared cloud-native data services.
The Old Apps and Storage
To better understand this new approach, let’s take a quick look back.
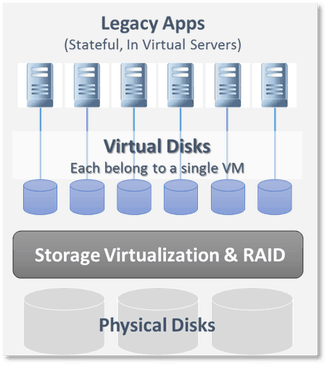
With legacy applications, servers had disk volumes that held the application data. As the markets matured and services changed, things shifted to clouds and infrastructure-as-a-service (IaaS) which meant virtualized servers (virtual machines, or VMs) were mapped to disk partitions (vDisks) in a 1:1 relationship. Storage vendors took pools of disks from one or more nodes, added redundancy, and provisioned them as virtual logical unit numbers (LUNs).
Then came Hyper-Converged. This technology wave enhanced the process and pooled disks from multiple nodes. Real security wasn’t required; rather this solution relied on isolation to ensure only the relevant server talked to its designated LUN. The process is also known as zoning.
The New Apps and Data
As the evolution continues, the new phase is platform-as-a-service (PaaS). Rather than managing virtual infrastructures such as virtual machines, apps are now managed. Rather than managing virtual disks, data is now managed. The applications don’t store any data or state internally because they are elastic and distributed. The applications use a set of persistent and shared data services to store data objects, streams, logs, and records.
These new data services and NoSQL technologies do not require legacy storage stacks since the resiliency, compression, and data layouts are built into the data services. What that means is that, for example, traditional redundant arrays of independent disks (RAID) and deduplication features are useless and, in some cases, potentially harmful.

This new model must address the data sharing challenge since many apps access the same data – and from far-flung places, such as mobile devices or remote sensors. In addressing this new reality, here are some important aspects for consideration:
- Security must evolve from isolation to tighter management of who is allowed to access what and how; it must have the capability for guaranteeing the identity of remote devices or container applications; and it must include the means for automatically detecting breaches.
- When different apps or devices access the same data, guaranteeing data consistency and integrity without significant performance degradation is critical.
- Understanding how searched data will be found among potentially billions of items is crucial.
- Different applications may have different access patterns to the data; today they use purpose-optimized data services. To support the case where different apps with different access requirements access the same data, we need to enable broad APIs and access variety, or we will end up creating copies or doing ETL
Today, the industry is seemingly focusing its efforts on cloud-native application platforms while using a fragmented set of data services or legacy storage approaches. That’s led some vendors to quickly rebrand their legacy storage technologies as “Cloud-Native”.
In reality, as we move from IaaS to PaaS we need to think about “data containers” rather than storage – similarly to how we now focus on application containers rather than the underlying VMs.
Interestingly enough, the large cloud providers took the opposite approach and are now focusing their efforts on building fully managed and self-service cloud-native data platforms to serve as ideal home and storage for the new apps. It is a ploy to lock in customers? Probably. They realize data has gravity, and that once it lands in their cloud platform, the apps will follow and the customers will be captive for a long time.
But here’s something worth considering. In parallel to the many new and noteworthy commercial cloud-native application platforms from companies like Docker Inc., Mesophere, and others, the industry also needs commercial-grade cloud-native data platforms that address the difficult challenges in managing and sharing huge amount of diverse data items and deliver data-as-a-service on-premises.
There is no reason why, with a bit of innovation, on-prem data platforms cannot be faster, cheaper, and simpler to use than those in the public cloud. After all, the public cloud is a decade old and not much of its technology has changed. With some forward thinking and more modern technology, on-prem data platforms may be the next big thing. Think “modern architecture meets tomorrow’s challenges.” read www.iguaz.io.

