Build an AI App in Under 20 Minutes
Nick Schenone and John Crupi | July 19, 2022
What is an AI App?
Machine learning is more accessible than ever, with datasets available online and Jupyter notebooks providing an easy way to explore and train models with minimal expertise. But when building a model, it's easy to forget that its real value lies in being incorporated into a live application that will provide value to the user. Therefore, we wanted to demonstrate how we can very easily leverage the models we build into a full application, with minimal engineering.
In this blog, we'll demonstrate how quickly and easily you can create what we’re calling an AI App in Under 20 minutes. The idea is to create a set of simple AI applications that leverage a machine learning model and allow you to interact with a UI to visualize the results of their predictions. We will show that you don't have to build the whole pipeline from scratch to deploy and interact with these models.
Along with interactive UIs, these AI apps will also contain Behind The Scenes code snippets showing how the models were deployed and how the application interacts with them.
How Do We Embed AI into an Application?
The tool that makes this all possible is MLRun - an end-to-end, open-source MLOps orchestration framework that includes experiment tracking, job orchestration, model deployment, feature store, and much more.
Our focus in this blog will be on MLRun's model deployment capabilities. In machine learning, deployment refers to the process of making a model available for use. As a result, users, developers, or systems can take advantage of the model's predictions, and interact with their applications based on data.
To build the application, we created a Streamlit application with multiple pages containing our simple AI apps. You can access the application using the hosted version on Heroku or clone the source code from the GitHub repo and host it yourself via docker-compose.
Streamlit is a great tool for creating interactive dashboards, data visualizations, machine learning apps, and much more, by writing simple Python scripts. It handles much of the boilerplate code associated with web development, so using it for these lightweight apps will help us save a lot of engineering work.
We will showcase the capabilities of MLRun through the lens of two AI apps that build off each other:
- Iris AI App: Simple Model Serving
- Heart Health AI App: Complex Model Serving Graph + Real-Time Feature Engineering
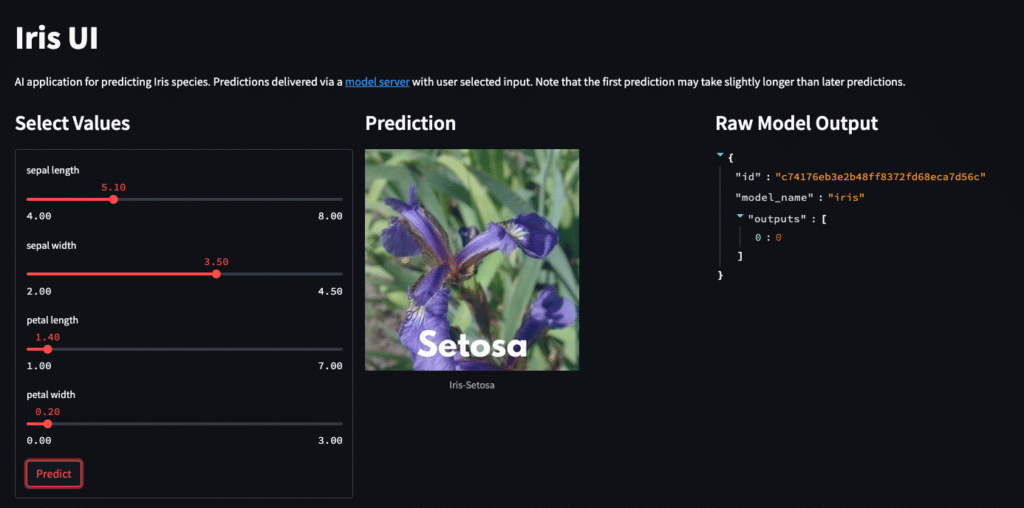
Iris AI App: Simple Model Serving
The goal of this AI app is to show how to serve a machine learning model using four lines of code. The focus is not so much on the model itself, but rather on how it was deployed and integrated into the application.
Here's a short video where we take you through this app:
The model itself was trained on the classic Iris dataset which contains four features representing the dimensions of an Iris flower petal. The model will take these dimensions and predict which of the 3 species the flower belongs to. These features map nicely to 4 sliders in our application that can be used to generate data to send to the model.
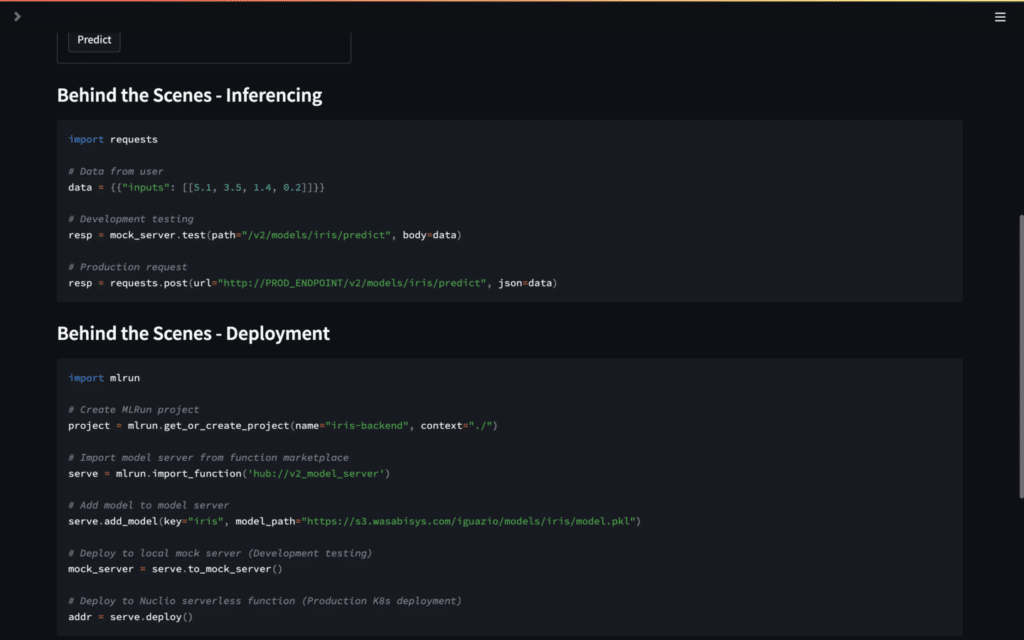
While the UI itself is fun to play with, the most important part is the Behind The Scenes section that showcases the model deployment in 4 lines. This shows the power and accessibility of MLRun when serving simple models. For more information on what is being used, check out the MLRun documentation on a simple model serving router.
Once the model is deployed, it must be invoked by some sort of trigger. MLRun supports a variety of triggers for model deployments, however we are using the default HTTP endpoint in this case. The Behind The Scenes section on inferencing shows how the model is being used within the application - essentially just a POST request to the HTTP endpoint.

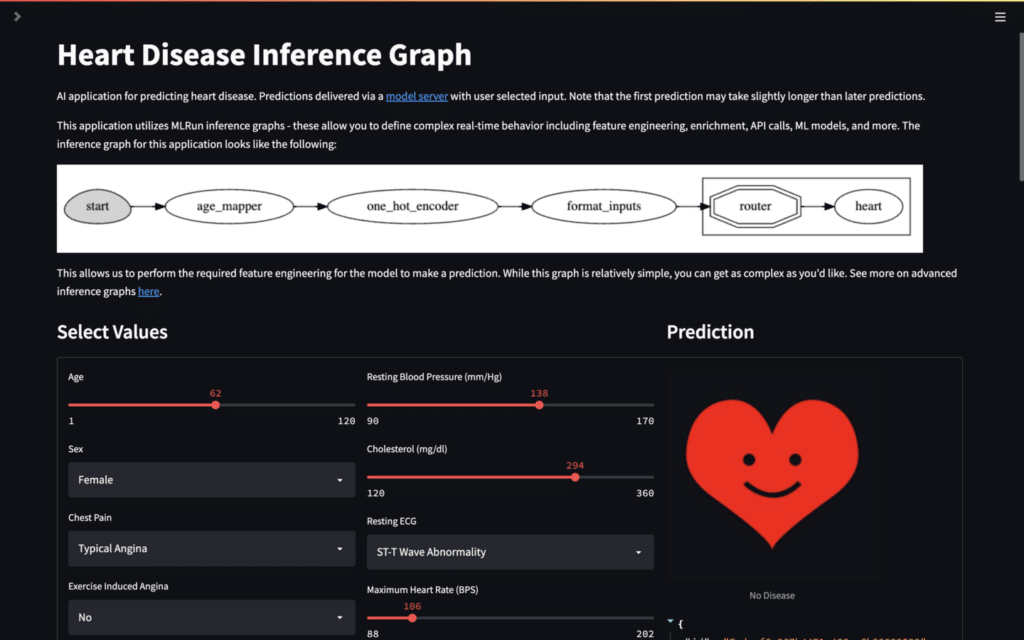
Heart Health AI App: Complex Model Serving Graph + Real-Time Feature Engineering
The goal of this AI App is to build off of the previous and add functionality. Before, we deployed a model that simply took in 4 numerical features that required no pre-processing. However, most models require feature engineering to format the data properly such that the model can understand it and make a prediction.
The model used in the Heart Health AI App uses the classic Heart Disease Dataset to predict heart disease in patients. The dataset contains 13 features that require transformations such as bucketing and one hot encoding. This means our simple model serving approach from the previous AI App will not work in this case.
Enter MLRun’s real-time inferencing graph - a Directed Acyclic Graph (DAG) of steps that happen in real-time. These graphs are an incredibly powerful and flexible tool that allow you to set up any kind of complex real-time flow.
Here's a short video where we take you through this app:
In our application, the graph contains several steps:
age_mapper: Convert the numerical age feature into several buckets (i.e. child, adult, elder, etc.)one_hot_encoder: Convert the categorical features into 1’s and 0’s that the model can understandformat_inputs: Convert the data into a format that the model server is expecting (much like the first AI App)router: Model router that sends the data to our heart disease classifier model
This allows us to easily deploy our application like before with all of the graph steps and configuration baked in. Like before, our graph is exposed via the default HTTP trigger and is invoked from the application using a POST request.
The most important part of this AI app is the Behind The Scenes section on deployment. It shows how the graph was created, how configuration was passed in, and how the whole thing was deployed. There are less than 15 lines of actual code, but they are punching far above their weight for the complexity of what they do.
Additionally, there is a Behind The Scenes section for the Raw Model Output. By expanding this section, you can see exactly what the payload is for each step of the graph and how each of the transformations is affecting it. This is not normal behavior for the graph to return each of these steps like this, however it was built this way for learning purposes.
Your Turn
At the time of posting this blog, there are only the two AI apps that we covered. However, there is plenty of space for additional apps to showcase novel use cases and functionality of the MLRun framework.
Please feel free to clone the GitHub repo, create your own AI app, and submit a pull request so that we can include it in the hosted version on Heroku (NB: the hosted version takes a few moments to spin up) and the source code!


