How to Build a Smart GenAI Call Center App
Alexandra Quinn | November 12, 2023
Building a smart call center app based on generative AI is a promising solution for improving the customer experience and call center efficiency. But developing this app requires overcoming challenges like scalability, costs and audio quality. By building and orchestrating an ML pipeline with MLRun, which includes steps like transcription, masking PII and analysis, data science teams can use LLMs to analyze audio calls from their call centers. In this blog post, we explain how.
The Benefits of Generative AI for Customer Support
The number of calls to call centers is increasing, creating a need for improving call center efficiency. AI solutions can help improve operational efficiency by automating processes, streamlining workflows and providing real-time insights. This can help organizations reduce costs, improve customer service and make better decisions.
For example, AI solutions can reduce customer frustrations by documenting call details, providing contextual recommendations and analyzing the sentiment of calls. This data can then be leveraged by downstream applications that improve the customer experience, like live agent support, customer profiles, auto-generated content, tailored recommendations, customized offers and more.
Challenges of Developing a Call Center Generative AI App
Developing a generative AI call center application can improve call center performance, but development comes with its own set of challenges. These include:
- LLMs for Non-English Languages - LLM performance for non-English languages is usually considered poor. If the call center accepts calls in non-English languages, there needs to be a technological solution to address the gap.
- Audio Quality - The audio quality of customer calls varies significantly. Some calls might include heavy background noise, overlap, or volume issues. Data processing is required to clean up audio files.
- Performance vs. Cost - LLMs are compute-heavy. The data science team needs to find a balance between performance accuracy and GPU cost efficiency. This includes that ability to support GPU sharing, running multiple jobs on a single GPU and automatically scaling up the workload, while minimizing costs.
- Data Privacy - Customers share private and sensitive data on calls, like their financial information. The team needs to find a way to safeguard this data and meet compliance requirements.
The Solution: How to Use Generative AI to Extract and Analyze Data
To build a generative AI application for a call center, data professionals need to build an AI workflow that can record and analyze the call. This workflow should be automated, have the ability to scale resources and be able to log and parse values between the steps.
To do so, we’ll use MLRun, an open source ML orchestration framework for building and managing continuous ML applications across their lifecycle. MLRun is ideal for this type of task because it will allow us to use (and easily swap out) any optimized open source LLM model and elastic scaling, which helps control costs. We can also leverage built-in functions from the MLRun hub, which will speed up development times.
In addition, MLRun is a flexible solution that is easy to customize and extend on demand, while supporting automation, CI/CD, observability and other production-readiness capabilities. Finally, MLRun is easy to use, and can be operated by data scientists with no expertise in infra like K8s, Docker, etc. Essentially, MLRun allows a lean team to quickly build and manage AI applications.
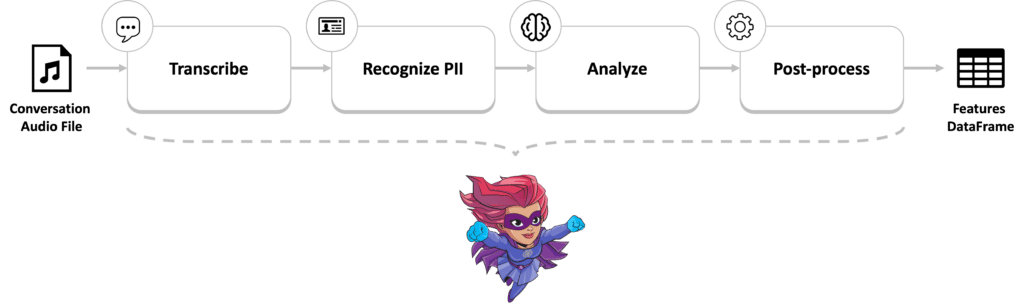
The call center genAI pipeline will include four steps:
- Transcribing the call: Using an OpenAI register model to transcribe the audio files into text files.
- Recognizing PII: Anonymizing the text files by recognizing and masking private identifiable information (PII). Learn more here.
- Analyzing: Using an LLM to answer questions. In the example below, we use LLM Falcon 40B. Example queries could include:
- Classify the customer issue in up to four words.
- Write a summary of the call.
- Was the customer issue fixed? Respond with ‘yes’ or ‘no’.
- Was the customer’s tone positive, negative, or neutral?
- Was the agent’s tone positive, negative, or neutral?
- Post-processing: Post-processing to get raw features from the conversation and extracting them to a DataFrame. This step was added after the initial LLM didn’t perform as well as expected in the demo.
To generate calls for training, we used OpenAI for the transcript and a text-to-speech service to generate a speaking voice. Then, the files were saved to an MP3 format.
Here’s what the pipeline looks like:
In the future, the pipeline will include additions like MySQL as a relational DB, Milvus as a vector DB, a data analysis workflow, and more.
Call Center Generative AI App Results
In a similar project run by Iguazio, the results were:
- 85% summarization success rate
- 70% intent prediction success rate
- 3 seconds average time to summarization
To watch a demo of how to build and use this pipeline, click here for GitHub.

