How to Run Workloads on Spark Operator with Dynamic Allocation Using MLRun
Xingsheng Qian | October 11, 2022
With the Apache Spark 3.1 release in early 2021, the Spark on Kubernetes project has been production-ready for a few years. Spark on Kubernetes has become the new standard for deploying Spark. In the Iguazio MLOps platform, we built the Spark Operator into the platform to make the deployment of Spark Operator much simpler.
This blog post will cover the benefits of running your workload on Spark Operator, and how to run the workloads on Spark Operator with dynamic allocation of executors with MLRun, Iguazio’s open source MLOps orchestration framework.

Spark Operator Concept
Here is a quick introduction to how Spark Operator works. For more details, you can refer to the Spark Documentation
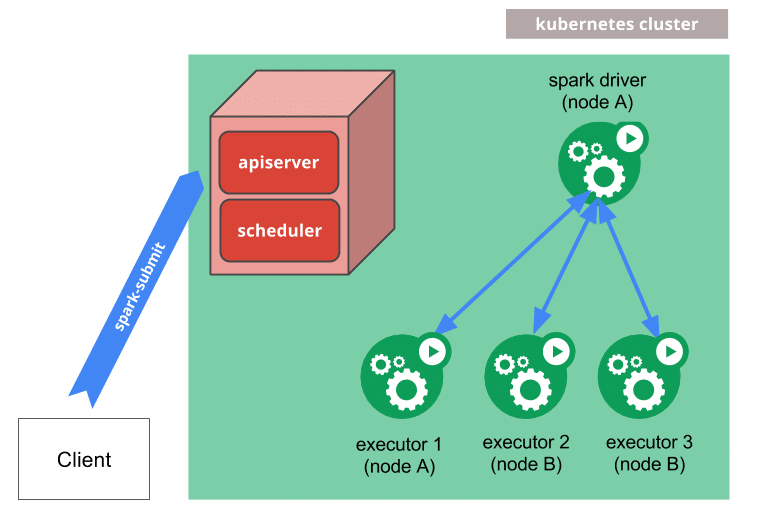
- Spark creates a Spark driver running within a Kubernetes pod.
- The driver creates executors which are also running within Kubernetes pods and connects to them, and executes application code.
- When the application is complete, the executor pods terminate and are cleaned up, but the driver pod persists logs and remains in “completed” state in the Kubernetes API until it is eventually garbage collected or manually cleaned up.
Note that in the completed state, the driver pod does not use any computational or memory resources.
The driver and executor pod scheduling are handled by Kubernetes. Communication to the Kubernetes API is done via fabric8. It is possible to schedule the driver and executor pods on a subset of available nodes through a node selector using the configuration property for it. It will be possible to use more advanced scheduling hints like node/pod affinities in a future release.
MLRun Spark Operator Runtime
Iguazio’s open-source MLOps orchestration framework, MLRun, integrates and automates the different layers in the data science, data engineering, and MLOps stack to deliver faster results with fewer resources. The MLRun framework abstracts away the low-level implementation of Spark on Kubernetes from end users and simplifies the implementation of running Spark workloads in Kubernetes.
The spark-on-k8s-operator allows Spark applications to be defined in a declarative manner and supports one-time Spark applications with SparkApplication and cron-scheduled applications with ScheduledSparkApplication.
When sending a request with MLRun to the Spark operator the request contains your full application configuration including the code and dependencies to run (packaged as a docker image or specified via URIs), the infrastructure parameters, (e.g., the memory, CPU, and storage volume specs to allocate to each Spark executor), and the Spark configuration.
Kubernetes takes this request and starts the Spark driver in a Kubernetes pod (a k8s abstraction, just a docker container in this case). The Spark driver can then directly talk back to the Kubernetes master to request executor pods, scaling them up and down at runtime according to the load if the dynamic allocation is enabled. Kubernetes takes care of the bin-packing of the pods onto Kubernetes nodes (the physical VMs) and will dynamically scale the various node pools to meet the requirements.
When using the Spark operator, the resources will be allocated per task, which means scale down to zero when the task is done.
Why Dynamic Executors?
Dynamic Allocation of Executors can lead to valuable savings on computing resources. With Spark Operator, you can also take advantage of the spot instances which result in extra savings on the computing cost.
Dynamic Allocation (of Executors) (aka Elastic Scaling) is a Spark feature that allows for adding or removing Spark executors dynamically to match the workload.
Unlike in the "traditional" static allocation where a Spark application reserves CPU and memory resources upfront irrespective of how much it really uses at a time, in dynamic allocation you get as much as needed and no more. It allows you to scale the number of executors up and down based on workload, i.e., idle executors are removed, and if you need more executors for pending tasks, you simply request them.
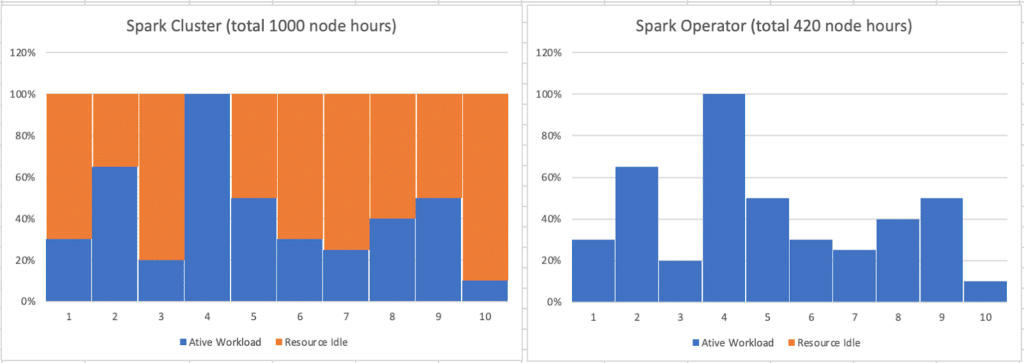
As a simplified example for comparison, let’s say in a “traditional” static allocation, the peak workload needs 100 nodes for the parallel processing, assuming the whole workload takes about 10 hours to complete, it needs a total of 1000 node hours to complete the tasks. In dynamic allocation, the nodes can be scaled up and down according to the actual workloads, it will only take 420 node hours to complete the tasks. This is a whopping 58% savings on computing resources.
All the major cloud providers offer spot instance for the computing nodes. Spot instance lets you take advantage of unused computing capacity. Spot instances are available at up to a 90% discount compared to on-demand prices. Spark workloads can work on spot instances for the executors since Spark can recover from losing executors if the spot instance is interrupted by the cloud provider. To run the spot nodes in Kubernetes, you can create multiple node groups and use node-selectors to configure the executors to run on spot instances.
In the next section, I will walk through how we can run a Spark workload with dynamic allocation of the executors and how to specify the executors to run on the spot node groups.
How to Run Spark Operator with MLRun
MLRun simplifies the implementation of running Spark workload with Spark Operator and Dynamic Allocation. Assuming we have an MLRun cluster configured with a couple of node groups for different workloads. There is one on-demand node group spark-ng-ondemand and there is one spot instance node group spark-ng-spot.
Here is the code snippet to set up a spark job, where new_function() creates a new MLRun function:
from mlrun.run import new_function
import os
spark_filepath = os.path.join(os.path.abspath('.'), 'spark-job.py')
sj = new_function(kind='spark', command=spark_filepath, name='spark-function-name')
sj.with_driver_limits(cpu=4)
sj.with_driver_requests(cpu=2, mem="4G")
sj.with_executor_limits(cpu=3)
sj.with_executor_requests(cpu=2, mem="8G")
# Dynamic Allocation
sj.with_dynamic_allocation(min_executors=2, max_executors=10, initial_executors=2)
sj.spec.spark_conf['spark.eventLog.enabled'] = True
# configure the spark history server log path
sj.spec.spark_conf['spark.eventLog.dir'] = "file:///v3io/users/spark_history_server_logs"
# configre the drive on ondemand node group
sj.with_driver_node_selection(node_selector={'app.iguazio.com/node-group': 'spark-ng-ondemand'})
# configre the executors on spot instance node group sj.with_executor_node_selection(node_selector={'app.iguazio.com/node-group': 'spark-ng-spot'})
# with spot instance, need to allow preemption_mode
sj.with_executor_preemption_mode("allow") A simple spark-job.py is shown below:
from pyspark.sql import SparkSession
from mlrun import get_or_create_ctx
context = get_or_create_ctx("spark-function")
# build spark session
spark = SparkSession.builder.appName("Spark job").getOrCreate()
# read csv
df = spark.read.load('iris.csv', format="csv", sep=",", header="true")
# sample for logging
df_to_log = df.describe().toPandas()
# log final report
context.log_dataset("df_sample", df=df_to_log, format="csv")
spark.stop() In the above snippet, it is self-explanatory, the case is we are running a Spark job on MLRun with Spark Operator, with the driver running on an on-demand node group and minimum of 2 and a maximum of 10 executors on spot instances.
In this cluster (on AWS EKS for our example), once we submit the Spark job, the cluster node groups look like the below:
The Spark driver will be scheduled on an on-demand node and the executors will be scheduled on 2 spot instances.
| CLUSTER | NODEGROUP | MIN SIZE | MAX SIZE | DESIRED | ASG NAME |
| us-350 | spark-ng-ondemand | 0 | 2 | 1 | eksctl-us-350-nodegroup-spark-ng-ondemand-NodeGroup-E695UDUF5YIA |
| us-350 | spark-ng-spot | 0 | 2 | 2 | eksctl-us-350-nodegroup-spark-ng-spot-NodeGroup-13N5NSF8CL56T |
| us-350 | initial | 2 | 2 | 2 | eksctl-us-350-nodegroup-initial-NodeGroup-QQ5DEJUGN4YK |
Note that due to the resource limit on the two spot instances, there is only 8 out of the 10 executors are scheduled for the workloads. Two other executors are still in the pending state waiting for the available resource. Even though two of the executors are in a pending state, in this case, the Spark job is executed on the other 8 available executors. In general, when you create a Spark job and assign the maximum executors, always keep in mind the physical limits of your computing resources.
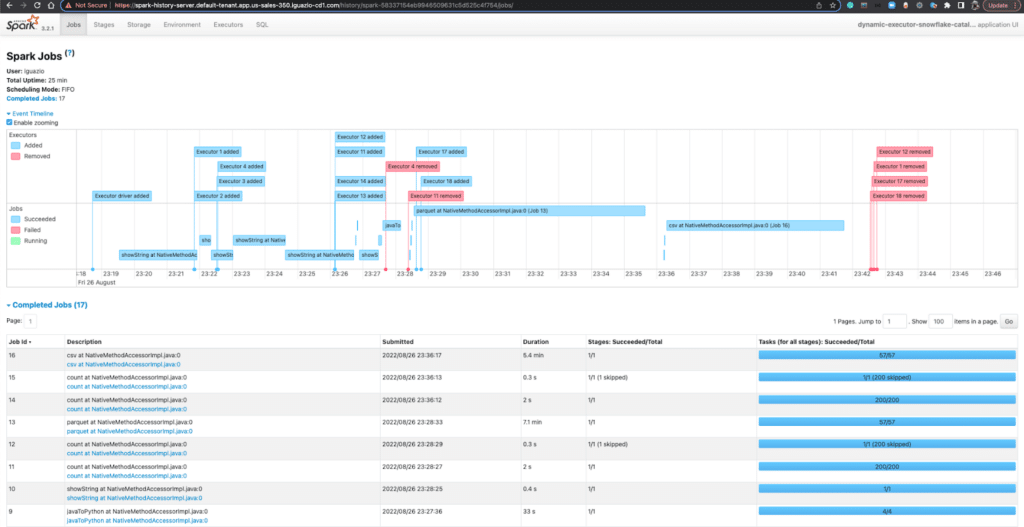
With MLRun, you can get to the Spark UI when you run a Spark operator job on the cluster. The UI will show all the details of a typical Spark UI. You can access Spark Jobs, Stages, Tasks, Storage, Environment, Executors, and SQL. Here is a screenshot from the MLRun cluster UI.
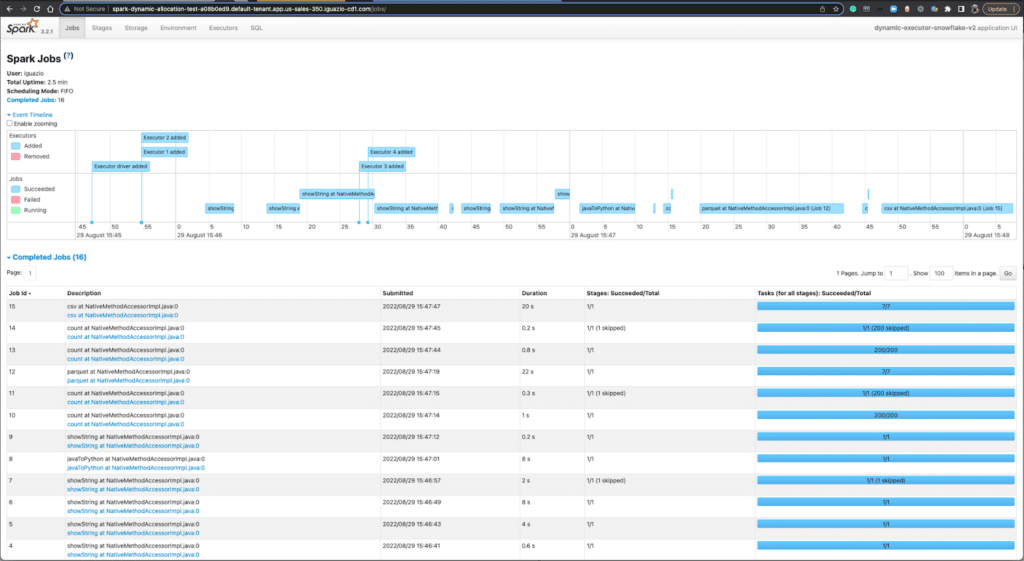
You may also configure the spark history service on an MLRun cluster. Even after your Spark job is completed, you can access the Spark History Server to view all the running info of a particular Spark job. The following screenshot gave a quick illustration on how the executors are added and removed for a Spark job dynamically.
What’s Next?
In this blog post we went over the benefits of running your workload on Spark Operator and briefly touched on how to run the workloads on Spark Operator with dynamic allocation with MLRun. In upcoming posts, we will discuss some best practices, tuning tips on setting up the Spark operator node groups and sizing of the nodes, sizing of the drivers and executors, and dynamic scheduling of executors.
MLRun is an integral part of the Iguazio platform. Iguazio is an enterprise-ready automated MLOps platform that provides features such as feature store, real-time model serving pipeline, model monitoring & re-training, CI/CD for ML, data pipeline with Spark Operator, DASK, etc.
For a trial version of the enterprise MLOps platform, check out the free trial.
Want to learn more about running Spark Operator on the MLRun platform? Book a Live Demo Today
Latest Posts

Integrating LLMs with Traditional ML: How, Why & Use Cases
April 24, 2024
Building and Scaling Gen AI Applications with Simplicity, Performance and Risk Mitigation in Mind Using Iguazio and MongoDB
July 22, 2024
RAG vs Fine-Tuning: Navigating the Path to Enhanced LLMs
July 8, 2024