Commercial vs. Self-Hosted LLMs: A Cost Analysis & How to Choose the Right Ones for You
Guy Lecker | June 30, 2024
As can be inferred from their name, foundation models are the foundation upon which developers build AI applications for tasks like language translation, text summarization, sentiment analysis and more. Models such as OpenAI's GPT, Google's Gemini, Meta’s Llama and Anthropic’s Claude, are pre-trained on vast amounts of text data and have the capability to understand and generate human-like language. In addition to the hype surrounding these commercial models, there's also a rising interest in self-hosted open-source LLMs, like Mistral. As businesses and organizations increasingly rely on AI for various applications, the demand for advanced foundation models is expected to continue growing, driving further innovation and competition in the market.
In this blog post, we dive into the considerations to make when choosing a proprietary model* vs. self-hosting an open-source model. We also provide some example use cases that exemplify how to implement these requirements. Then, we show how these requirements are implemented in models, through Artificial Analysis’s website comparison. Finally, we provide a list of additional tools and capabilities that can help optimize LLMs even more.
(*Clarification: While in some cases commercial LLMs like Cohere and AI21 can be hosted in your own environments, this is not the common use case. Throughout the blog post, when referring to commercial LLMs we mean vendor-hosted models).
Commercial vs. Self-Hosted: How to Make the Choice
When deciding whether to choose commercial versus self-hosted models, several key factors should be considered. These will help determine the best fit for your particular use cases or organizational needs.
1. Privacy
The top and most important consideration is data privacy. Regulated industries or corporations that deal with sensitive information necessitate robust data privacy capabilities. While companies that offer commercial LLMs conveniently handle all the maintenance, updates and infrastructure, the company data is processed on the provider's servers. This might raise concerns regarding data privacy and security. Even though reputable providers implement robust security measures and comply with privacy regulations like GDPR or CCPA, there is still a reliance on external parties to protect sensitive information.
Self-hosted LLMs on the other hand, offer more control over data privacy since the models operate on the company’s own infrastructure. This setup reduces the risk of data breaches involving third-party vendors and allows implementing customized security protocols tailored to specific needs.
For maximum privacy, self-hosting is the preferable choice. This approach minimizes external access to sensitive data and gives full control over data management and security protocols. Therefore, if you need privacy, you can probably skip the rest of this section.
2. Expedited GTM
Enterprises that are expanding their line of business and smaller startups, often prioritize a fast go-to-market with an MVP over a well thought-out, fully-blown solution. For achieving the fastest go-to-market, commercial LLMs generally offer a significant advantage over self-hosted solutions.
Commercial LLMs remove the need for in-depth technical expertise in ML infrastructure. You can often integrate these models with your systems through APIs, which are designed to be straightforward and well-documented. In addition, there is no need to purchase, configure, or maintain hardware. Once you subscribe or register, you can start integrating and testing right away.
These models also come with vendor support. This means troubleshooting, updates and improvements are handled by the provider, ensuring the model remains state-of-the-art without additional effort from your team.
3. Accuracy
LLM accuracy directly impacts the accuracy of outputs and the reliability of how tasks are performed. Overall, larger LLMs will have a better potential for higher accuracies. In most cases, these LLMs are not self-hosted. On the other hand, fine-tuning can help a lot to increase the accuracy of self-hosted models. We should also not forget about RLHF, which can further maximize accuracy with human feedback. relevant for self-hosted models.
4. Speed
LLM speed directly influences user experience, scalability and operational efficiency. Higher throughput and lower latency are required for a good user experience. However, they require more GPUs, which are usually more expensive.
Therefore, the question of speed will depend on the capabilities, requirements and budget an organization has for developing and maintaining the infrastructure. Commercial providers typically use high-performance servers and optimized networking infrastructure to ensure low latency and fast response times. In addition, commercial services can dynamically allocate resources to handle varying loads efficiently, which helps in maintaining consistent performance even under heavy usage. Finally, the infrastructure is regularly maintained and updated by the provider to ensure optimal performance without any additional effort from the user.
Locally, the performance depends on the capabilities of your own hardware (see below - additional ways to improve accuracy and performance).
5. Cost
For most organizations, resource optimization is a top priority. Most commercial models operate on a pay-as-you-go or subscription basis. In addition, all maintenance, upgrades, and improvements are managed by the provider, eliminating additional costs for these activities. However, while initial costs are low, over time, the ongoing expenses can add up, especially if usage increases significantly.
For self-hosted, major costs are upfront, primarily for hardware and initial setup. If your usage is high, self-hosting can become cost-effective over time as ongoing operational costs can be lower than perpetual service fees. And, once you've covered the initial costs, you won't face additional fees based on the number of requests or compute time, which is beneficial for applications requiring heavy or continuous use of the model.
6. Customization
Customization enables organizations to ensure the LLMs are fit for their exact business and operations requirements. Commercial solutions often come with predefined customization options, offering ease of use and quick deployment. However, they may lack the flexibility to fully tailor the system to specific needs, which can be a limitation for organizations with unique workflows or specialized requirements.
While prompt engineering can be useful, this comes with a cost. Vendors calculate fees by token count. Extensive prompting for each task is a costly effort, especially compared to fine-tuning. Fine-tuning yields smaller prompts with faster inference and for only the cost of infrastructure.
Therefore, if you require an expert LLM for a specific task, you will need the ability to fully control and customize it. This includes adjusting it to human feedback, inserting guardrails, and implementing domain knowledge throughout training. Self-hosted solutions allow organizations to modify the software to their exact specifications, offering complete control over functionality and user experience.
Commercial vs. Self-Hosted LLMs: Key Comparison Points
| Commercial LLMs | Self-Hosted LLMs | |
| Privacy | Reliance on external parties | Complete control over data |
| Expedited GTM | Can be integrated into your pipeline ready to go through prompt engineering, guardrails, etc. | Requires setup and development of the model, infrastructure and application logic. |
| Accuracy | Higher accuracy across a broader scope of topics | Can be fine-tuned for specific domains |
| Speed | Uses high-performance servers and optimized infrastructure | Depends on your own systems and infrastructure |
| Cost | Initial costs are lower, costs accumulate over time | High upfront costs, cost-effective over time with continued use |
| Customization | Limited, prompt engineering is costly | Full LLM customization, including human feedback, inserting guardrails, and implementing domain knowledge |
Example Use Cases
To further help you determine which requirements to prioritize, below are some example use cases. Our underlying assumption is that if you have privacy requirements you’ll use self-hosted, regardless of the use case and if you need expedited GTM you’ll use commercial LLMs, regardless of the use case.
Use Case #1: Process Automation
Process automation can be used to improve activities like framing images or analyzing data. In these cases, accuracy cannot be compromised, especially in data analysis. At the same time, speed is required for handling large volumes of tasks efficiently. This means speed and accuracy are equally critical.
Use Case #2: Chatbots
Chatbots are customer-facing agents that can provide 24/7 support or support human agents as co-pilots. The importance of model accuracy, speed and cost in a chatbot use case depends on the specific application and user expectations.
- For customer service or complex inquiry handling, accuracy might be prioritized to ensure accurate and relevant responses and avoid hallucinations that could potentially impact the business.
- For casual conversation or high-traffic applications, speed could be more important to maintain user engagement.
- Cost becomes a primary consideration for businesses aiming for cost-efficiency or scaling operations.
Ideally, the chosen solution should offer a balanced compromise, tailored to the chatbot's primary function and the organization's budgetary constraints. Companies can mix and match different models for different tasks. For example, you can use OpenAI for a typical conversation. Then, once you need access to sensitive data you can use your own self hosted model. You can also use multiple self-hosted models of different sizes and training data or access GPT-3.5 for casual tasks and GPT-4 for heavy duty tasks.
Use Case #3: Feature Extraction
Feature extraction enables retrieving questions from a text file, helping with data analysis, research, ML model training and content creation. Accuracy is top priority here. The model needs to understand context, nuances and complex relationships within the text to accurately extract meaningful features. Speed and cost are also considerations but secondary to ensuring the extracted features are relevant and precise.

Comparing Commercial and Open-Source Models
Artificial Analysis is an online, comprehensive comparison of AI models across various metrics. It compares models from leading providers like OpenAI, Google, Meta, Anthropic and Mistral, highlighting the trade-offs between accuracy, speed and pricing. This provides insights into various models’ efficiency and cost-effectiveness, helping making informed decisions about when to choose each one.
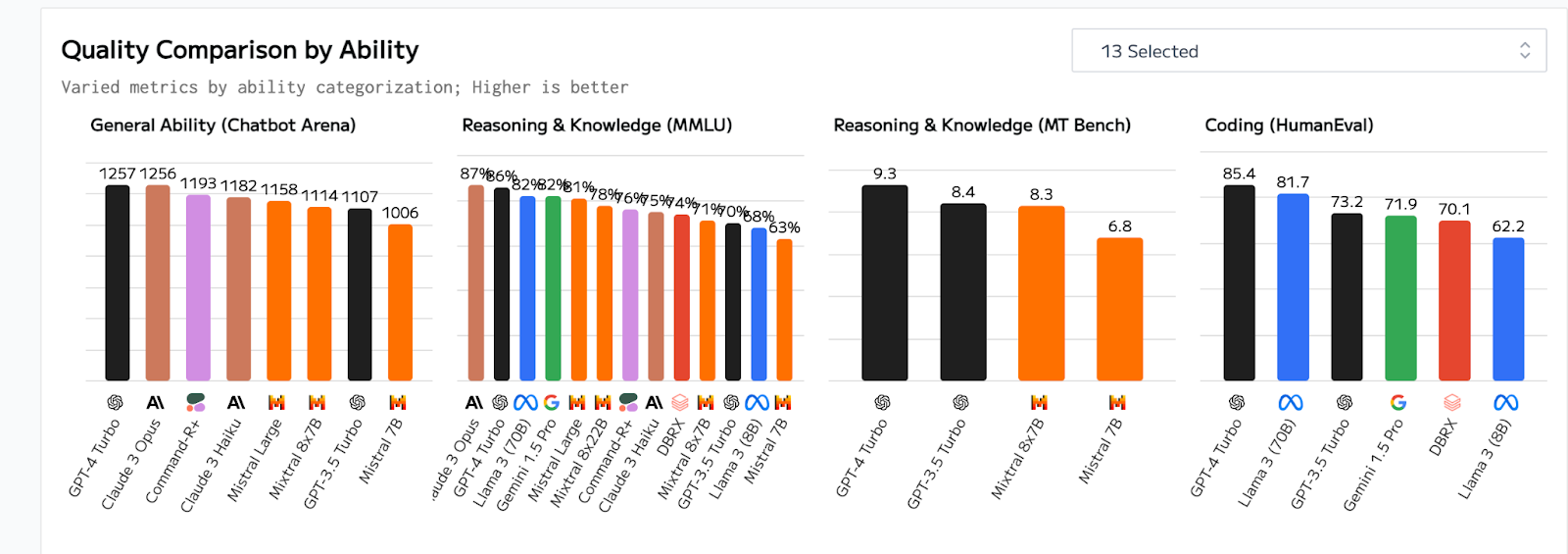
For example, in a sample comparison of a number of models:
- The accuracy of GPT-4 Turbo seems to be the highest, followed by Clause 3 Opus, Llama 3 and Gemini 1.5 Pro and Mistral Large. This means proprietary models are of higher accuracy, but open-source Mistral is ranked fairly high.
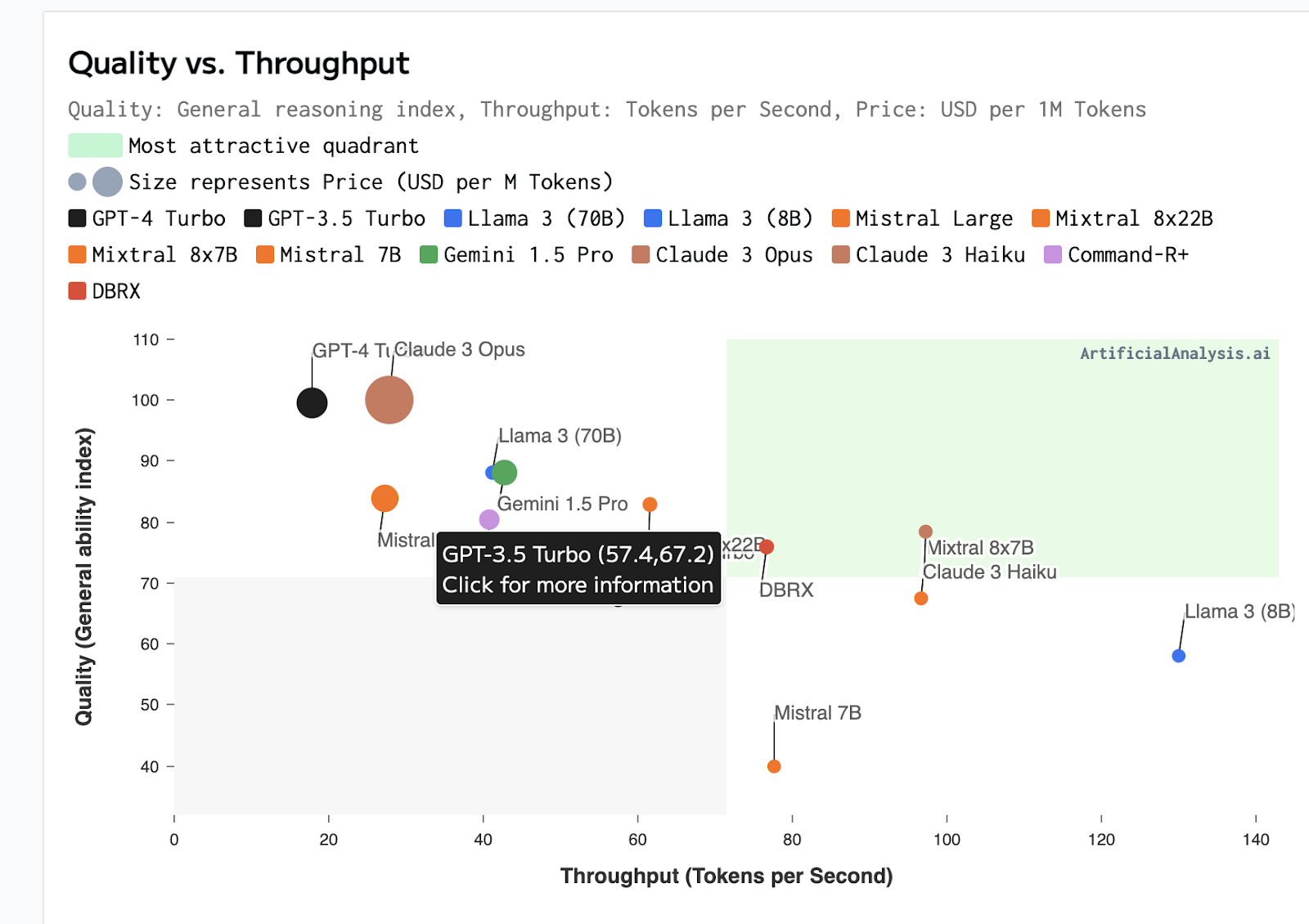
- When it comes to speed, Mistral is second only to Llama 3, meaning that both proprietary and open-source options are available for high-speed needs.
- When it comes to costs, Llama 3 is the lowest, followed closely by Mixtral8x78 and Claude 3 Haiku. Claude 3 Opius is by far the costliest option. Note that the comparison is per token, not against infrastructure, which is why open-source Mistral and Llama have a cost - they offer their models as a service just like OpenAI.

Artificial Analysis also includes drill downs into each criteria, for example, diving deeper into capabilities:
As well as grid charts comparing two criteria, like quality/accuracy vs. throughput:
Additional Ways to Enhance the Accuracy and Speed of Your Models
You can enhance the accuracy and speed of models that you are self-hosting with the following capabilities:
- GPU Provisioning - Enhance your existing GPU resources by automatically scale your existing resources up and down, based on your needs and without requiring additional hardware.
- Deci.ai (acquired by NVIDIA) offers an Automated Neural Architecture Construction (AutoNAC™) engine, which democratizes the use of Neural Architecture Search (NAS) to help teams rapidly generate deep learning models that are fast, accurate and efficient. This technology promises significant inference speedup (3-10x), maintaining or improving accuracy and it's designed with full awareness of both the data and the hardware being used.
- Prompt Shrinking - Using techniques to reduce token count. This allows increasing speed and reducing cost. Different models can also be used for different needs: more cost-effective models for easier tasks and pricer models for difficult tasks. This allows controlling the speed of the vendor models as well.
- Mosaic ML (acquired by Databricks) provides tools for easy training and deployment of these models, aiming to improve prediction accuracy, decrease costs, and save time.
- Qualcomm Cloud and NeuReality - Qualcomm Cloud is a cost-optimized solution for self-hosting models and NeuReality provides a managed cluster for hosting LLMs and other models. These make inference and deployment easier.
Conclusion
The choice between an open-source LLM and a commercial one will widely impact your operations. Self-hosting requires engineering resources and infrastructure, but provides unparalleled privacy, domain expertise and customization capabilities. As a result, It's important to invest in a robust and streamlined AI pipeline that will ensure models reach production and bring business value.
To learn more about how to operationalize and de-risk your gen AI applications, with either commercial or self-hosted LLMs, let’s talk.
FAQ
What is the difference between open-source LLM and commercial LLM?
Open-source LLMs are publicly available models whose code and often training data can be inspected, modified, and deployed without licensing restrictions beyond open-source terms. They offer transparency, flexibility and control, but require technical expertise and infrastructure to operate effectively. Commercial LLMs are proprietary solutions offered by vendors (e.g., OpenAI, Anthropic, Google) that are hosted and maintained by the provider. They typically come with SLAs, ongoing updates, optimized performance and integrated security/compliance measures, but the underlying code and training data are not accessible.
When is data privacy a critical factor in choosing an LLM solution?
When the LLM processes sensitive, regulated, or proprietary information, such as customer and employee data or industries like healthcare, finance, defense, or intellectual property-heavy industries. In such cases, a self-hosted open-source LLM or a commercial offering with strong on-premises or private cloud deployment options is required.
How do commercial and self-hosted LLMs compare in terms of speed and accuracy?
For accuracy, larger LLMs generally deliver higher accuracy, but they’re often not self-hosted. Self-hosted models can improve through fine-tuning and reinforcement learning with human feedback. For speed, fast, low-latency responses improve user experience and scalability but require costly GPU resources. Commercial providers typically offer optimized infrastructure, dynamic scaling, and regular updates to maintain high performance, while self-hosted performance depends heavily on the organization’s hardware and setup.
What are the cost implications of choosing between commercial and self-hosted LLMs?
Commercial models have low upfront costs and predictable subscription or pay-as-you-go pricing, with maintenance handled by the provider. However, long-term expenses can rise with heavy usage. Hosting LLMs require significant upfront investment in hardware and setup but can be more cost-effective over time for high-volume use, as ongoing costs are lower and not tied to usage levels.
How does customization capability differ between commercial and self-hosted LLMs?
Commercial LLMs offer predefined customization for quick deployment but may lack flexibility for specialized needs. Prompt engineering can adapt outputs but increases costs due to token-based pricing, while fine-tuning is more cost-efficient and improves speed. Self-hosted models provide full control, enabling deep customization, integration of domain knowledge, guardrails and human feedback for highly specialized tasks.
Are hybrid approaches combining both model types effective?
Many organizations use hybrid strategies to balance strengths and weaknesses. For example, they may use a commercial LLM for general-purpose reasoning and natural language fluency while deploying an open-source, self-hosted model for sensitive, domain-specific tasks. This can optimize costs, help maintain privacy and compliance, while expediting GTM and innovation.

