LLM Evaluation and Testing for Reliable AI Apps
Alexandra Quinn | August 5, 2025
As LLMs become central to AI-driven products like copilots and customer support chatbots, data science teams need to ensure the LLM performs well for the use case. The process of LLM evaluation ensures reliability, safety and performance in production AI systems. In this guide, we explore how to approach evaluations across development and production lifecycles, what frameworks to use, and how the integration between open-source MLRun and Evidently AI enables more scalable, structured testing.
To dive deep into the examples and details and see a live demo of the integration in action, you can watch the webinar with Elena Samuylova, CEO and co-founder of Evidently AI, and Jonathan Daniel, Senior Software Engineer at Iguazio which this article is based on.
What are LLM Evaluations?
LLM evaluations refer to the processes and methods used to assess the performance, capabilities, quality, limitations and safety of LLMs. Unlike LLM benchmarks that compare LLMs across global parameters, LLM evaluations assess the model for your specific use cases and your products. By evaluating LLMs, organizations can understand how well an LLM performs across various tasks and whether it meets the needs of their specific applications.
Evaluating LLMs doesn’t mean running a specific tool or task. Rather LLM evaluation is the process of validating the LLM and how it answers questions across different workflows.
Example LLM evaluation techniques include:
- Comparative Experiments - Testing various combinations of system design, like prompts, search strategies, or models.
- Stress Testing - Testing negative scenarios and edge cases, like harmful content, competition, prompt leakage, and more, to find breaking points.
- Production Observability - Evaluating system quality for users. For example, the user experience, how users use the system, failing points, etc.
- Regression Testing - Evaluating the impact of changes in production to ensure they don’t break behaviors. For example, when fixing a bug. Updating models and prompts, etc.
Each type of testing requires different workflows (see more below).
Why are LLM Evaluations Hard to Implement?
LLMs are non-deterministic by nature. This means that the exact same input can result in various, diverse outputs. For example, for the prompt “Can I get the product for free?”, the responses “I am afraid not,” “Here is our pricing:..,” and “Sure, to get the free product..” are all feasible.
Therefore, LLM evaluation should focus on a range of possible outputs. This requires determining quality criteria per use case. (A financial advisor chatbot would have different criteria compared to a document processor tool). There are also universal quality criteria, like “helpfulness”, “tone of voice” and “professionalism”. Naturally, this is not a simple feat.
LLM Risks and How LLM Evaluation Can Help
There are two main risks that LLM evaluation solves:
- AI quality risks - Is the LLM solving the problem it should be solving?
- AI safety and security risks - Can the LLM do harm? How do we handle such a situation?
Example Risks:
- Hallucinations - Factually incorrect responses, potentially misleading users and creating legal and compliance issues.
- Jailbreaks - Prompt manipulation to bypass an LLM’s safety filters, causing it to output harmful, offensive, or policy-violating content.
- Brand risks - When LLMs generate outputs that damage brand credibility, trust and reputation.
- Data exposure - Unintended leakage of sensitive, proprietary, or personally identifiable information
See examples of the real-live impact of LLM risks in the webinar.
LLM Evaluations Methods
Since evaluating LLMs isn’t a tool or framework but rather a process, there are various ways to conduct this process. Some of the most popular methods include:
Vibe Evaluations - When users manually create example user questions for the applications and then review the responses.
The challenge: Not scalable or systematic.
Mostly used for: Popular cases, edge cases and adversarial attacks
Automated Evaluations - A systematic approach of evaluating with scripts, prompts and systems.
There are two types:
- Reference-based evaluations
- Overlap-based metrics - ROUGE, BLEU, etc.
- Deterministic matching
- Ranking metrics - NDCG, HitRate, MRR, precision, recall, etc.
- Classification metrics - Precision, recall, accuracy, F1 score, etc.
- Reference-free evaluations
- Deterministic validation
- Text statistics
- ML-based scoring - Pre-trained models for toxicity, sentiment, NLI, etc.
- Regular expressions - Trigger words, competitor mentions, etc.
Two additional methods are both reference-based and reference-free:
- LLM-as-a-Judge - Reference-based: Semantic matching, pairwise comparison; Reference-free: Direct scoring, context-based scoring, session-level evals
- Semantic similarity - Reference-based: Similarity to reference response; Reference-free: Similarity to input, context, or patterns
Spotlight: LLM-as-a-Judge
LLM-as-a-Judge is the use of LLMs to evaluate or assess various types of content, responses, or performances, including the performance of other AI models. This LLM-based evaluation is gaining traction because it allows for applying custom criteria without relying solely on pre-trained models. By passing model outputs back into an LLM with evaluation prompts, it allows mimicking human grading at scale. Note, however, that this often requires tuning the evaluator LLM, making it a small ML project in itself.
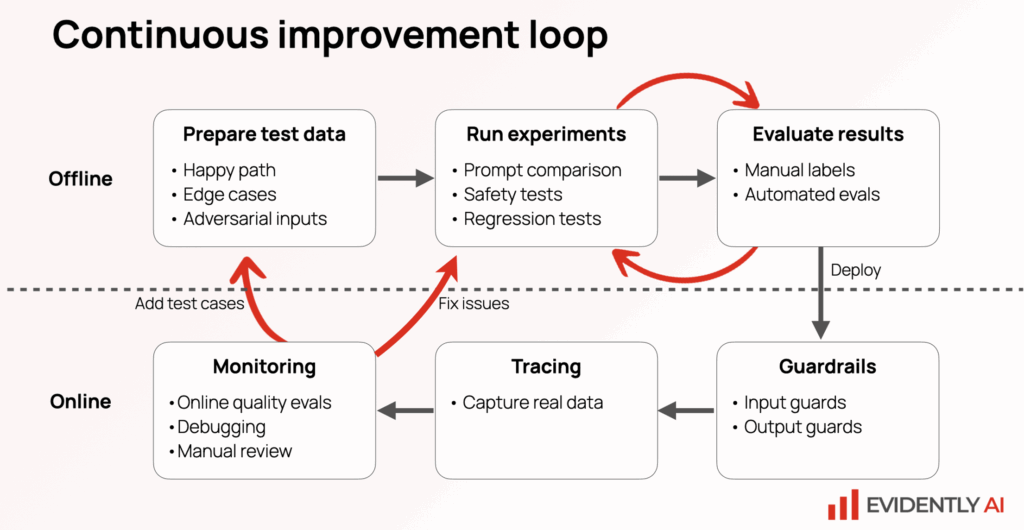
LLM Evaluations in the Continuous AI Workflow
LLM evaluations are part of a continuous AI workflow or pipeline:
- Building an evaluation system starts with test datasets. Datasets need to include all use cases, including edge cases. They also need to be comprehensive, accurate, consistent and high quality.
- Then evaluators run experiments and score outputs automatically based on the criteria inputted by the data science team.
- Once deployed, add guardrails, capture real data for tracing and monitor for performance.
- With these results, you can add more use cases to the evaluation, creating a continuous improvement loop.
Doing so allows for fast iterations, builds trust that the product is good enough and enables managing risks specific to the use case.
LLM Evaluation Best Practices
- Think through the risks that might apply to your application. Real world brings issues that don’t come up in demos.
- Determine who owns evaluations in your company. It can be a product manager or an engineer, but someone has to be accountable.
- Data is key
- Evaluations are a moat. All organizations have access to the same models, everyone has access to writing prompts. But good label data and evaluators can tune to your use case.
The MLRun and Evidently AI Integration for the LLM Evaluation Workflow
Open-source MLRun and Evidently AI can operate together to run a streamlined and scalable LLM Evaluation workflow.
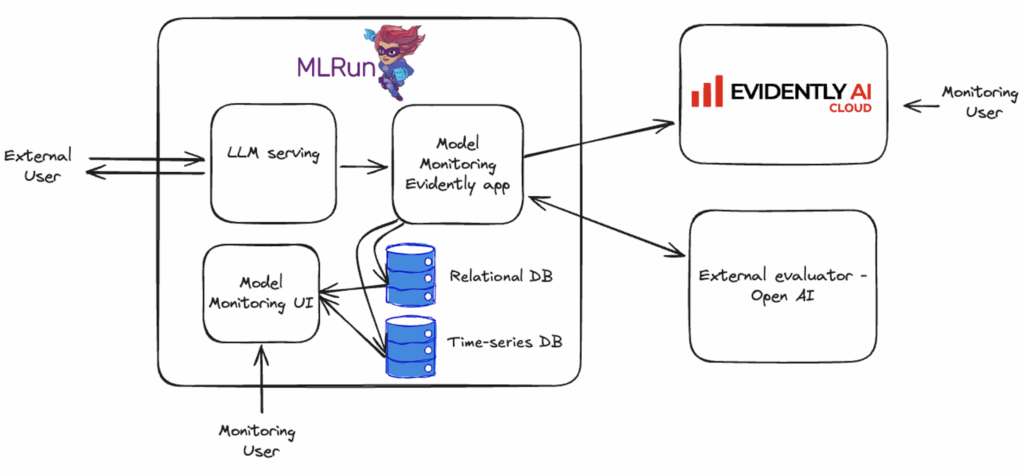
To evaluate the LLM’s performance, data is collected using MLRun, with the application built on top of Evidently AI. The evaluation process includes using the LLM-as-a-Judge approach, and the results are stored in both a relational database and a time-series database. These results are presented through MLRun and Evidently, with continuous performance monitoring in place. For more details, refer to the joint notebook.
You can also see a demo of the MLRun-Evidently integration in action in the webinar.

