LLM Validation and Evaluation
Alexandra Quinn | May 21, 2024
LLM evaluation is the process of assessing the performance and capabilities of LLMs. This helps determine how well the model understands and generates language, ensuring that it meets the specific needs of applications. There are multiple ways to perform LLM evaluation, each with different advantages. In this blog post, we explain the role of LLM evaluation in AI lifecycles and the different types of LLM evaluation methods. In the end, we show a demo of a chatbot that was developed with crowdsourcing.
This blog post is based on a webinar with Ehud Barnea, PhD, Head of AI at Tasq. AI, Yaron Haviv, co-founder and CTO of Iguazio (acquired by McKinsey) and Guy Lecker, ML Engineer Team Lead at Iguazio, which you can watch here.
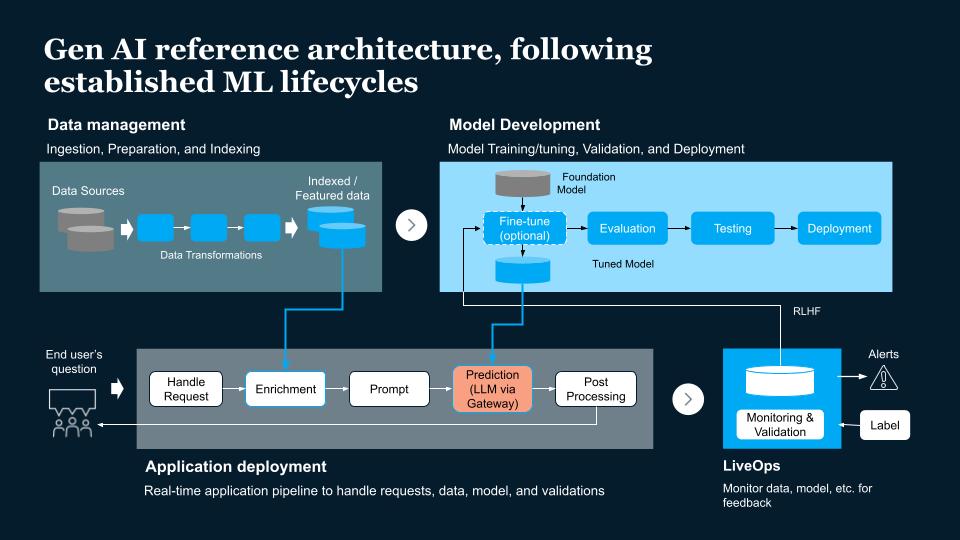
Gen AI Reference Architecture Following Established ML Lifecycles
Building generative AI applications requires four main elements:
- Data management - Ingesting, preparing and indexing the data.
- Model development - Taking the existing baseline model, training and tuning if required with additional data gathered from data processing or through a feedback loop, evaluating, testing and deployment.
- Application deployment - Receiving the prompt engineering requests, running through LLMs and post-processing.
- LiveOps - Monitoring and validation of information from the application pipeline onto monitoring frameworks, labeling, filtering and sending to fine-tuning if required.
To build accurate and risk-free models, improve performance and implement governance, it’s important to place data and model controls in gen AI apps. This requires controls in the pipelines, in multiple places. This includes:
- Cleaning and preparing data during pre-processing, before it is sent to the model.
- Testing the model with different prompts and verifying outputs and behavior during model application testing.
- Checking incoming user requests and prompts in real-time.
- Monitoring LLM usage by use case and user and logging activities.
- Verifying compliance and quality of results in real-time before they are sent to the users.
- Monitoring application logs for compliance, accuracy and quality of results.
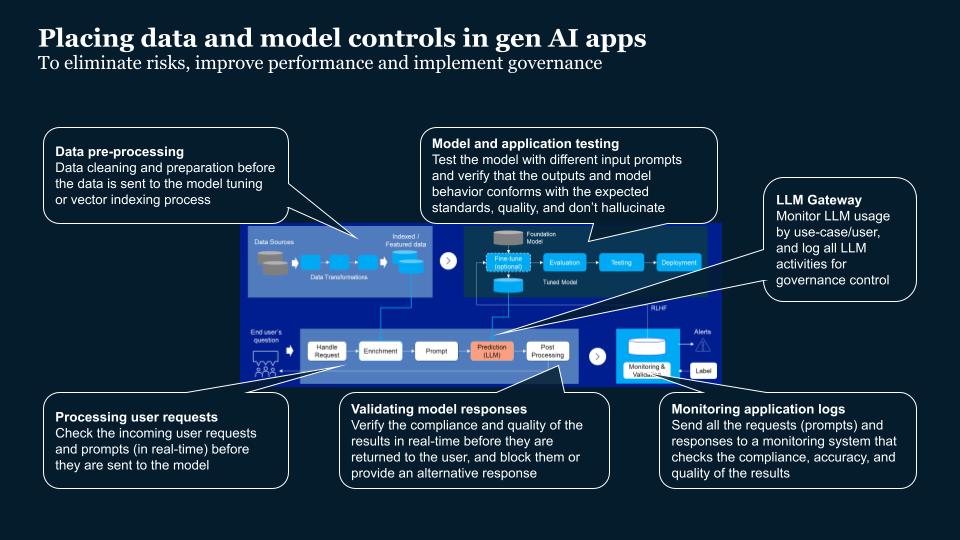
This is where LLM evaluation fits in.
Solving the LLM Evaluation Production Hurdle
According to Ehud Barnea, PhD, Head of AI at Tasq. AI, it seems like every time a new open source LLM model becomes publicly available, the data science community gets hyped and excited about its qualities. The potential of its accuracy, security, quality, and other features make it seem like a good option for corporate use cases.
However, when trying to use them, reality sets in and they tend to discover that performance isn’t as good as they expected. This is because standard benchmarks don’t reflect reality.
It's not that the tipping point hasn't been reached. Open-source models like Mistral AI and Claude can perform just as well as GPT. But with visibility still lacking, it’s difficult for companies to know if these models can be helpful for their own data and use cases. When deploying to production, results might be unexpected and even have significant business implications. Model evaluation can help determine the model's fit.
When is Evaluation Needed?
There are three places evaluation is needed:
- Deployment and CI/CD - Before the model reaches production.
- Production monitoring - After production to ensure accuracy.
- During development - Training iterations to improve results. This is more challenging with generative AI.
Evaluation Methods
There are two main types of LLM evaluation methods: algorithmic and human:
- Algorithmic Methods -
- “Classic” methods, like BLEU, ROUGE, BertScore, etc. These methods are based on similarity with reference answers. They are not suitable for LLMs since there is no single right answer for LLMs.
- LLM Judges - Using LLMs to evaluate LLMs. This method is suitable for LLMs. However, it is less accurate and biased. For example, many models prefer responses from their own model.
- Human Preference Methods
- Internal Employees- Using employees, mainly R&D, to evaluate generated responses. However, this method is costly and unscalable.
- Hiring Annotators - Hiring a team to provide feedback. However, this is not scalable and requires managerial efforts.
- User Feedback (Data Flywheel) - When users provide feedback about the response. However, this is biased and limited, since users do not want to share feedback all the time. It is also only relevant for models in production.
- Global Crowd - Asking people from around the world. This is scalable and unbiased, since it leverages people from different countries, cultures and languages. However, it is much harder to set up.
Today, many companies use a combination of these evaluation methods.
Evaluating LLMs with a Global Crowd: Mistral vs. ChatGPT
Let's look at an example of a global crowd evaluation in action: Mistral and ChatGPT were prompted to rewrite an angry X Tweet in a positive mindset while telling the same story.
- The original Tweet: I feel like my go to emotion is angry.
- ChatGPT: I believe that my default emotion is passion.
- Mistral: Despite feeling angry at times, I believe there’s room for growth and improvement in managing my emotions.
Both models were able to generate content with a positive mindset, but only Mistral kept the same story.
To evaluate the qualities of these outputs, human guidance was used. A global crowd was defined from English-speaking countries. They were asked which sentence is more positive. Mistral was found by the crowd to be 87% more positive and also wrote nicer texts.
However, when Mistral was limited to writing the same length of text as ChatGPT, it was only 58% more positive, and ChatGPT was found to be 57% more closer in meaning.
Demo: Developing a Chatbot with LLM Evaluation Crowdsourcing
In this demo, we are going to develop a chatbot for a fashion company and show how to use crowdsourcing for evaluation, using MLRun.
The chatbot should:
- Recommend website items based on the customer’s preferences.
- Offer fashion tips according to the website styling.
- Answer questions about website policies, like shipping and returns.
- Be polite and follow the company’s code of conduct.
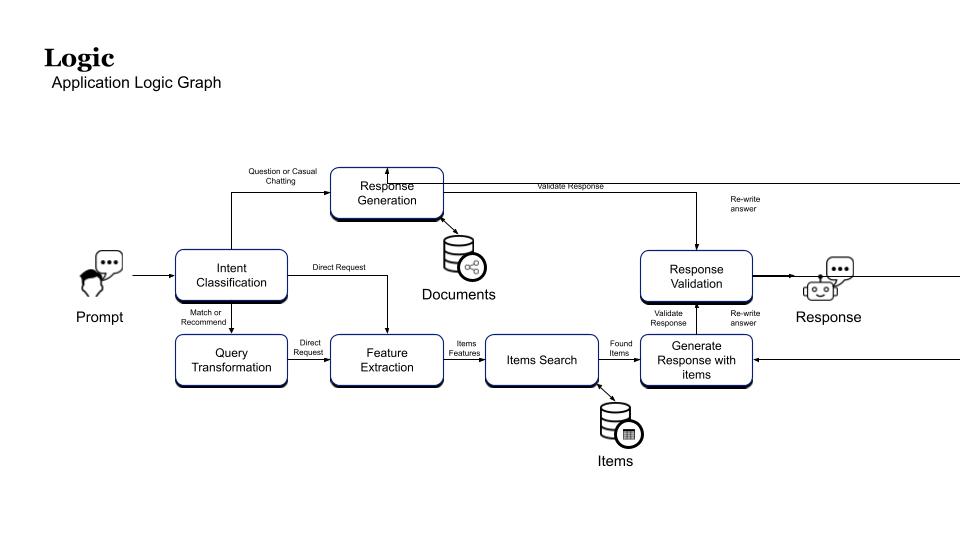
The production serving pipeline steps:
- Prompt
- Session loading
- Query refinement
- Subject classification
- Toxicity filter
- Application logic
- History saving
- Response
In addition, subject classification and toxicity filtering can also go directly to history saving.
Model servers (LLM, CNN, etc.) collect inputs from query refinement, subject classification and toxicity filtering to inference the LLM and fine-tuning.
It looks like this:
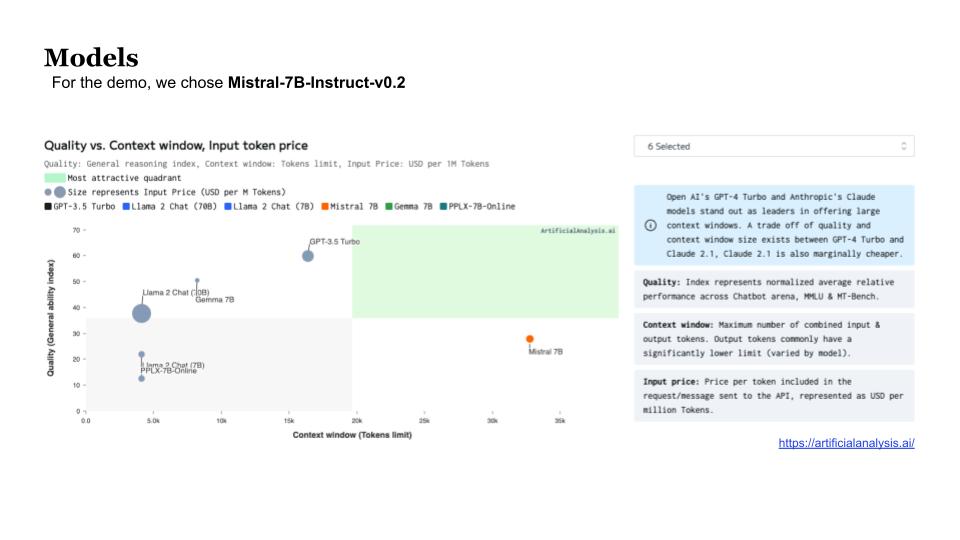
For this demo, we chose the LLM Mistral-7b-Instruct-v0.2. This is because it has a good context window, cost to serve is fairly low and response quality is high.
To improve the LLM, we used RLHF (Reinforcement Learning from Human Feedback). Using MLRun’s model server, we collected the input and output prompts for various nodes within the application graph.
Then, we wanted to achieve the following:
- Reduce prompt size - Using fashion tips RAG increased each clothing matching prompt. So we removed the fashion tips and inferred Mistral with its “default taste” in fashion so the model adjusts itself to the crowd’s taste.
- Insert guardrails - Adding another layer of defense to the model. So we added ~30 samples of input prompts and the expected outputs. Then we inferred them with Mistral.
- Improve Responses - Responses were not always fitting and friendly. So we prompt engineered guidelines and a code of conduct and inferred the model again.
We then used crowdsourcing to determine which output, the original or the newly inferred one, was more engaging and fun, helpful and useful, and offensive, rude, or toxic. The option with the better score was marked as “chosen”.
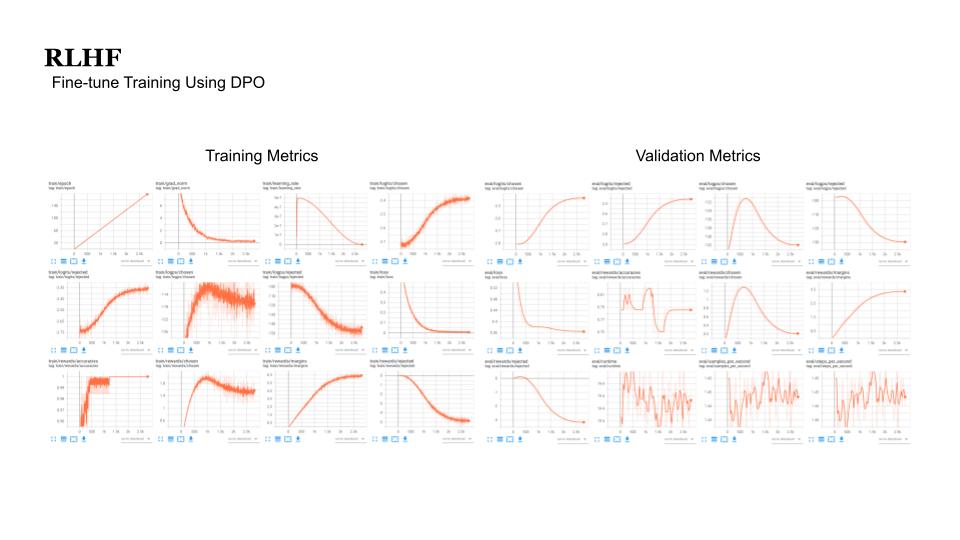
The model was then fine-tuned with DPO. Here are some of the metrics as can be seen in MLRun:
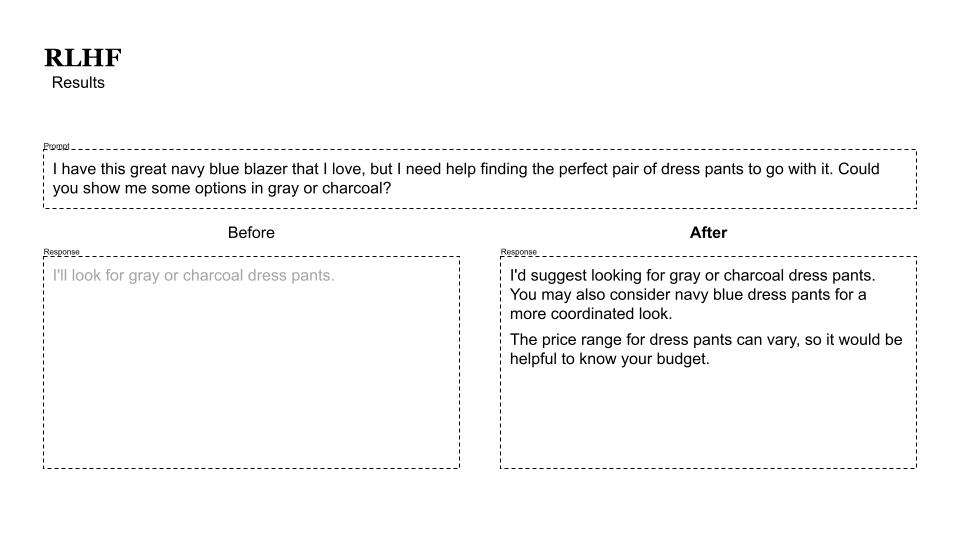
Here are some sample results.
Example 1:

Example 2:
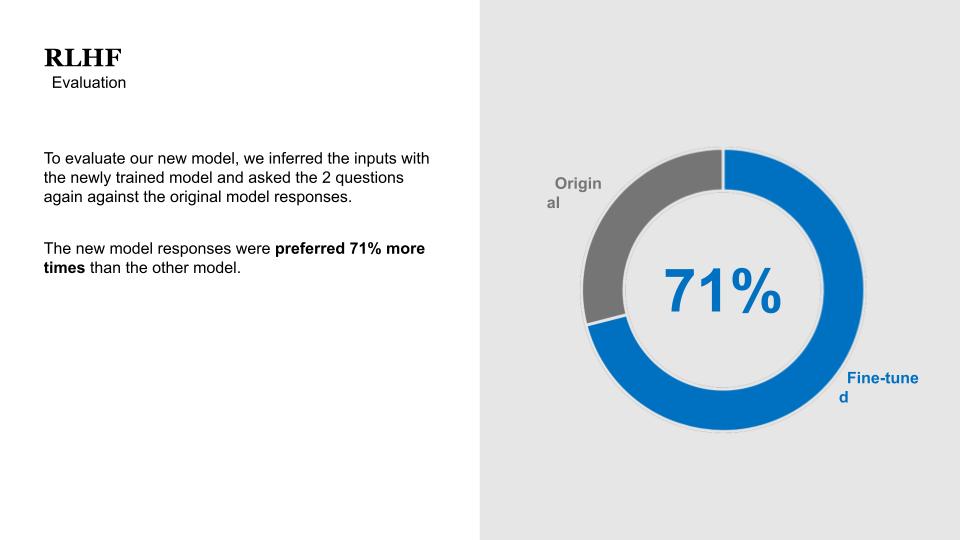
Overall, 71% of crowdsourced uses preferred the new, fine-tuned model.
Conclusion
LLM evaluation enhances model reliability and efficiency while also ensuring it meets ethical standards and is free of biases. There are multiple ways to perform LLM evaluation, and they can be automated and streamlined through a gen AI architecture. This helps overcome the LLM production hurdle and operationalize generative AI applications so they bring business value.
To see the entire webinar and watch a demo of the chatbot in action, watch the full webinar recording here.
For personalized consultation services regarding AI implementation, let’s talk.
FAQs
What is LLM evaluation and why is it important?
LLM evaluation is the process of assessing the performance and capabilities of large language models. It ensures that the model understands and generates results effectively, meeting the specific needs of various applications. Proper evaluation helps improve model accuracy, reliability, ability to meet business needs and adherence to ethical standards and compliance regulations.
Where in the AI lifecycle is LLM evaluation needed?
Evaluation is required throughout the AI lifecycle and especially at three key points. First, during development, to improve results through training iterations. Second, before deployment, as part of CI/CD to ensure readiness for production. Finally, after deployment, for ongoing monitoring and accuracy checks in production).
What are the main methods for evaluating LLMs?
There are two main categories. First, algorithmic methods. This includes traditional metrics (BLEU, ROUGE, BertScore, etc. ) and LLM judges (using LLMs to evaluate other LLMs). Second, human preference methods. This includes internal employee reviews, hiring annotators, collecting user feedback and leveraging a global crowd.
Why are standard algorithmic benchmarks often insufficient for LLM evaluation?
Standard benchmarks typically rely on similarity to reference answers, but LLMs can generate many valid responses to a prompt. This makes these benchmarks less suitable for evaluating LLMs, as there is rarely a single “correct” answer.
What are the advantages and challenges of using a global crowd for LLM evaluation?
A global crowd provides scalable and unbiased feedback, drawing on diverse perspectives from different countries and cultures. However, setting up such a system can be complex and resource-intensive.
How can LLM evaluation improve chatbot development?
By integrating crowdsourcing and human feedback into the development pipeline, chatbot responses can be refined to be more engaging, helpful and aligned with company guidelines. This also helps de-risk toxicity and bias.
What tools or frameworks can assist with LLM validation and evaluation?
MLRun is one example of a tool that can manage the evaluation process, collect feedback and support reinforcement learning from human feedback (RLHF) and fine-tuning with methods like DPO (Direct Preference Optimization).
How can bias be minimized when using global crowds for model evaluation?
Diversify the crowd geographically and demographically, including language, culture, education level and lived experiences. Standardize task instructions and provide calibration tasks to reduce annotator interpretation variance. Use inter-annotator agreement metrics to spot inconsistencies or outliers. Apply statistical debiasing techniques during analysis, such as re-weighting votes based on demographic sampling. Finally, audit outputs with subject matter experts to catch biases missed by general crowd workers.
What role does reinforcement learning from human feedback (RLHF) play in improving LLM performance?
RLHF fine-tunes models to align with human preferences by teaching models to prefer helpful, harmless and honest responses, correcting undesirable tendencies such as verbosity, hallucination, or bias and enabling alignment with specific organizational or cultural values.
How often should LLMs be re-evaluated after deployment to ensure continued quality?
Every quarter, at minimum. Continuous evaluation (weekly/daily) is recommended for models integrated into dynamic products (e.g., chatbots, search). In addition, it’s recommended to evaluate after model updates or retraining, changes in data pipelines, or shifts in user behavior or complaints.
What are the best practices for designing prompts that effectively test LLM capabilities?
Use clear, unambiguous instructions. Design prompts to target specific abilities (e.g., reasoning, summarization, translation). Include edge cases, adversarial phrasing and real-world complexity. Incorporate structured response formats to ease evaluation (e.g., JSON outputs). Finally, pilot test prompts with multiple models and humans to check for reliability.
What legal or ethical considerations should be taken into account during LLM evaluation?
- Privacy - Avoid using or generating PII or confidential info during testing.
- Fairness - Test for differential performance across groups (gender, race, language).
- Transparency - Document evaluation methods, metrics and known limitations.
- Accountability - Ensure humans-in-the-loop can override or flag harmful outputs.
- Judicial - Ensure outputs adhere to local and global laws and regulations.
How can feedback from end-users be systematically integrated into the evaluation process?
Build an automated closed feedback loop, where real-world feedback triggers tuning and re-evaluation in the AI pipeline.

