ML Workflows: What Can You Automate?
Alexandra Quinn | March 17, 2022
When businesses begin applying machine learning (ML) workflows to their use cases, it’s typically a manual and iterative process—each step in the ML workflow is executed until a suitably trained ML model is deployed to production.
In practice, the performance of ML models in the real world often degrades over time, as the workflows fail to adapt to changes in the dynamics and data that describe the environment and require frequent retraining with fresh data. Data science teams also need to experiment with new implementations of the ML workflow, such as feature engineering, model architecture, and hyperparameter optimization, to improve ML model performance. This requires experiments tracking to monitor changes in model accuracy that are caused by changes in the ML workflow.
In this article, you will learn about the challenges of managing ML workflows, as well as how automating various steps in the workflow using a MLOps approach can help data teams achieve faster deployment of ML models.
Understanding the ML Workflow
A typical ML workflow involves the following steps:
- Data ingestion: Data is extracted from various sources and integrated into an input dataset for the ML task.
- Data analysis: Data scientists and engineers perform exploratory data analysis to understand the data schema and characteristics, so that they can identify the data preparation and feature-engineering operations needed for building the ML model.
- Data preparation: Data is prepared from the input dataset for building the ML model. This involves data cleaning, performing train-validation-test splits on the data, and applying data transformations and feature engineering to each data split.
- Model training and experimentation: Data scientists and engineers train ML models by applying ML algorithms to the training set and performing hyperparameter tuning on the algorithms to optimize the performance of the ML model on the validation set. The trained ML model is then evaluated on the test set to assess the model quality, based on a set of performance metrics.
- Model serving: The validated ML model is deployed to production to serve predictions.
- Model monitoring for concept drift: The predictive performance of the deployed ML model is monitored for potential performance degradation that is indicative of concept drift.
Challenges of Managing ML Workflows
As ML workflows involve various complexities and uncertainties during each step of the process, managing them comes with unique challenges, including:
- Cleanliness of data: For dirty data with missing/null or invalid fields, additional data-cleaning steps are needed to transform the fields into the format required for the ML workflow.
- Availability and quality of ground-truth data for model evaluation: As ML models are usually trained to predict labels based on input data, the ground-truth data you use to train and evaluate ML model performance has to be high quality. This is so that the trained ML model can realistically predict labels accurately in production. However, labeling ground-truth data can be tedious and expensive, especially for more complex technical tasks.
- Training runtime and experiments tracking during model experimentation: The time you need to train one version of the ML model on a dataset determines the number of experiments that you can perform with different versions of the ML model. It is important to keep track of model accuracy and training runtime for each combination of model architectures, hyperparameters, and sample sizes, so that you can use the results to determine the tradeoffs between time and model accuracy when training ML models.
- Concept drift in production: Predictive models typically assume that the relationship between input and output variables remains static over time. As many ML models are built based on historical data, they do not account for possible changes in the underlying relationships in the data. These changes can result in predictions that no longer represent the statistical properties of the output variable in the production environment, requiring you to retrain the ML model on more recent historical data to capture the changes in the data’s dynamics.
Automating ML Workflows
Automating ML workflows allows you to reduce the time you spend manually experimenting with different data-preparation and model-training approaches, simplify the management of ML workflows, and deploy ML models faster. You can achieve this by applying automated ML frameworks to the workflows of machine learning.
What Is Automated ML?
Automated ML is the process of automating the iterative and time-consuming tasks in the ML workflow. It allows data scientists and developers to speed up the process of developing production-ready ML models with greater ease and efficiency by automating the complex and repetitive tasks in data preparation, model selection, hyperparameter tuning, model serving, and monitoring the steps involved in the ML workflow. This enables data scientists to iterate more rapidly during model experimentation and manage the end-to-end ML lifecycle for continuous training and deployment of ML models in production.
What Can You Automate?
The goal of automated ML is not to achieve full automation of the ML workflow, but to automate each step so that you can focus on applying ML models to business use cases. Automating the ML workflow involves a divide-and-conquer approach to breaking the workflow down into individual steps and managing each step in the workflow as functions that can be composed into a ML pipeline.
This section explains the steps in the ML workflow that you can automate using automation tools and frameworks.
Data Ingestion
Once you identify the data sources for the ML workflow, you can automate data ingestion by defining the ingestion steps as functions and scheduling the ingestion of more recent data. The ingestion can be triggered on a crontab or on a pipeline orchestrator, such as Airflow, Luigi, or MLRun by Iguazio.
Data Preparation
Data transformation logic used in the data-preparation and feature-engineering steps can be packaged as reusable functions, which, in turn, can be composed to create a data-preparation pipeline that transforms input data into a suitable format for model training.
Model Training and Experimentation
Model training and experimentation tend to be the most time-consuming steps in ML workflows, as they involve training multiple versions of ML models with different combinations of model architectures, hyperparameters, and features. While not all aspects of the ML workflow can be automated (e.g., data analysis), you can reliably automate these steps:
- Hyperparameter optimization: You can automate hyperparameter-optimization algorithms, such as grid search, random search, and Bayesian methods, to test combinations of model hyperparameters and find the most optimal combination based on predefined accuracy metrics.
- Model selection: The input dataset can be trained in parallel on multiple models with default hyperparameters to determine the optimal model architecture for the data.
- Feature selection: You can automate feature extraction using open-source frameworks, such as featuretools and tsfresh. The most relevant features can then be automatically selected based on the relationships between the features and the output variable.
- Experiments tracking: When you perform ML experiments by training on different combinations of model architectures, hyperparameters, and features, you can automate the storing of information about the training attributes, as well as the execution results and output models. This will ensure that the experiments are reproducible and help you keep track of the impact that the changes in training attributes have on model performance.
Model Serving
Once you’ve trained a suitable ML model, it can be automatically deployed to production, either as a serverless function or an HTTP endpoint. Automated pipeline orchestration using model-serving frameworks, such as Kubeflow Pipelines and TensorFlow Serving, simplifies the deployment of ML models—from data preparation to model serving in production.
Model Monitoring
The performance of ML models that are deployed in production often degrades over time due to concept drift.
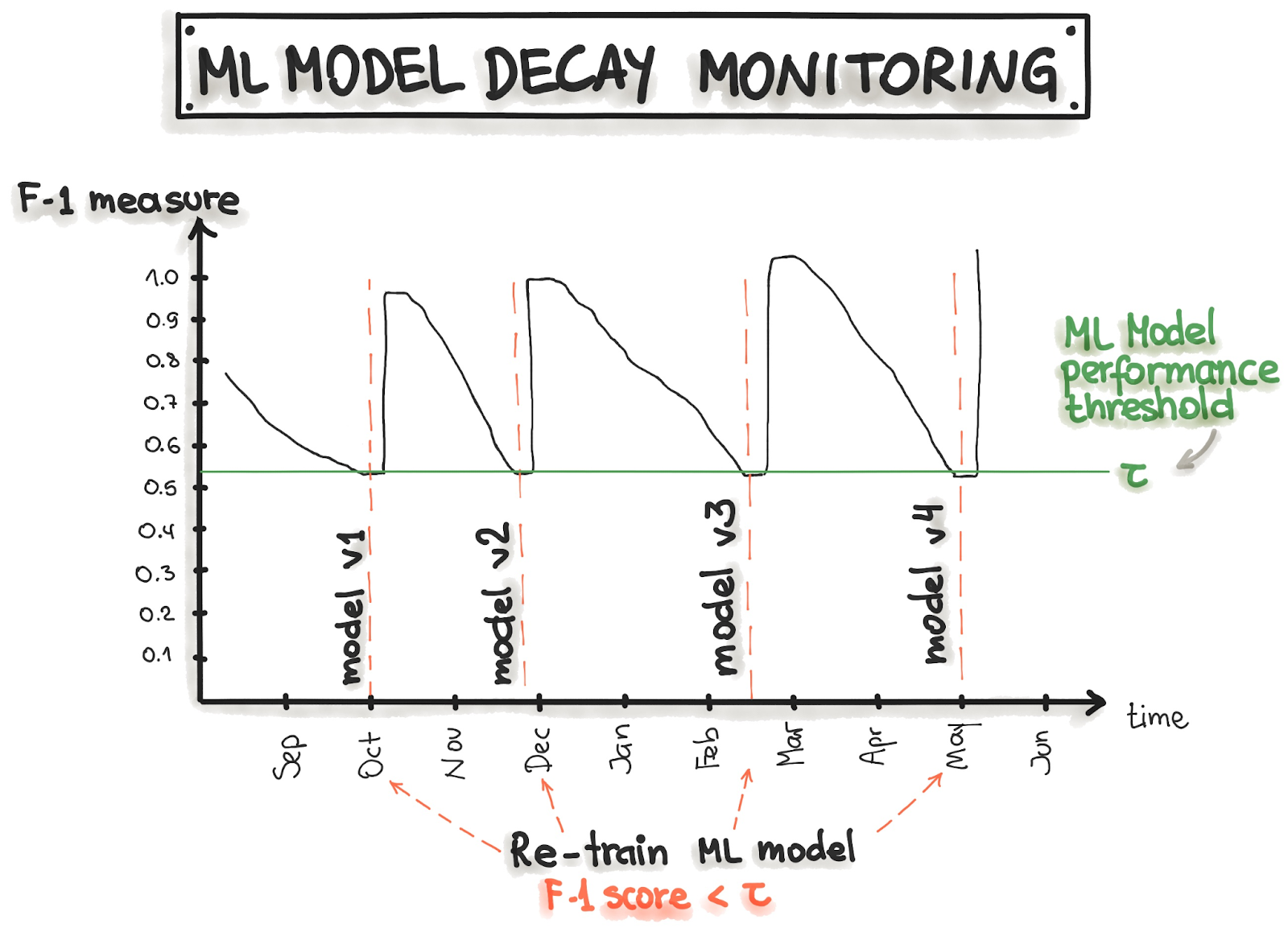
Concept drift detection enables you to monitor model performance over time and determine whether you need to retrain your ML model to ensure that it performs as expected in production. You can automate concept-drift detection by setting a performance threshold for the ML model in production and creating event triggers to retrain the ML model whenever model accuracy degrades significantly below the threshold.
Final Notes
Automating as many steps as possible in the ML workflow allows you to spend less time on the low-level details of model development and more on creating value for enterprises with machine learning. For data-science teams that rely on notebooks for data-science workflows, you can ease the automation process with MLRun, an end-to-end open-source framework for automating MLOps workflows.

