Paving the Data Science Dirt Road
Baila Sherbin | June 3, 2019
Reimagine the Data Pipeline and Focus on Creating Intelligent Applications
Guest blog by Charles Araujo, Principal Analyst, Intellyx
Bump. Clank. Slosh.
Moving around a city or town in the early 1800s was a bit of a slow, messy slog. But nobody knew any better.
Then, in 1824, the city of Paris covered the Champs-Elysees with asphalt creating the first paved road, and kicked off a new movement that would transform cities around the world. By the late 1800s, cities around the globe were in the throes of a massive effort to pave their roads — and the impact to commerce and the quality of life was phenomenal.
But paving didn’t just transform the roads – it also transformed the nature of transportation itself as a paved road opened the door to a wholesale reenvisioning of how cities worked.
It may be shocking given the futuristic images it conjures, but when it comes to data science and the creation of intelligent, data-driven applications, we are all living in our own dirt-road world.
And like the people happily, but slowly slogging along in the 1800s, we don't know any better.
That’s all about to change. It must.
Data has now become a vital business asset. Those organizations that can unleash its potential, rapidly and at scale, will have a tremendous advantage in a world in which data drives competitive value.
But to do so, companies must re-envision how they approach data, transform their static and slow-moving data pipelines into dynamic and real-time data science pipelines, and start creating a new class of intelligent applications. It’s time to start paving some roads.

The Bane of the Data Scientist: Data & Data Complexity
I love the term, data scientist.
For me, it conjures up images of smart people, wearing white lab coats, with beakers full of ones and zeroes gleefully experimenting and coming up with all new ways to apply data to solve business problems. If only it were so glamorous.
If my conjuring were more realistic, I would see a frazzle-haired person running from room to room, collecting armfuls of data, none of which matched, dropping some along the way as they darted from place-to-place, then heaving it all on the floor in a giant pile of ridiculousness.
And before they could even begin to think about how they would use their data to create this new class of data-driven applications, continuously streaming sets of new data would come crashing down on their head.
This is the real world for a data scientist. And if you are one or manage them, you live this reality every day.
Several years ago, the New York Times estimated, based on interviews and expert estimates, that data scientists spend up to 80% of their time on "‘data wrangling,' ‘data munging' and ‘data janitor work.'"
And as disheartening as that is, it’s not even the worst of it. The ever-growing complexity of enterprise data infrastructures, the increasing rate of change, and the continuously flowing data streams means that it’s taking longer and longer to get models into production – so long, in fact, that a significant percentage of data science projects never get into production at all.
This collective, wasted effort represents a huge challenge for organizations that must now create value from data and via intelligent apps — and in an environment in which every moment not spent on creating value could be the difference between leading the market, and being a laggard.
For anyone working in data science, the reasons for this effort misalignment are no mystery.
Traditional data pipelines, built for an era of static data and retrospective analysis, are not sufficient to build a data science capability that can operationalize data and convert it into business value.
The question that those responsible for data science within the enterprise must address, therefore, is how to reimagine the data pipeline and transform it into a data science pipeline to finally shift the balance of effort for their data science teams.
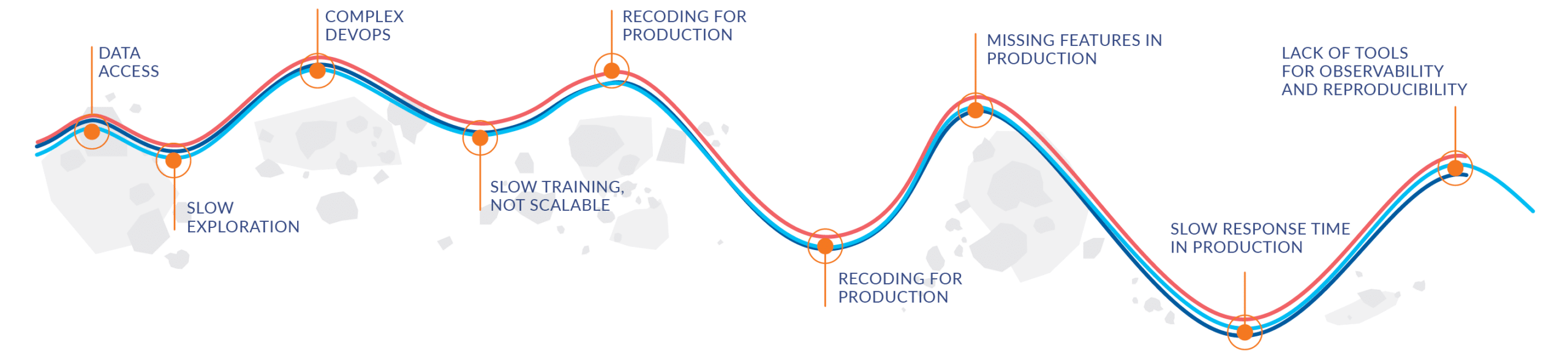
From a Data Pipeline to a Data Science Pipeline Transformation
Organizations began to realize the importance and competitive potential of data some time ago.
In response, they rushed to create data lakes, which, at the time, sounded like a good idea: collect all of your data in one place and sort it out later, as needed.
But data lakes may have made the situation worse — or at a minimum, they haven't helped. Getting all of the data in one place, but in a form that was often rigid and offered poor performance, changed the data pipeline, but did little to improve it.
Most importantly, organizations built these data lakes for a different time and a different purpose, making them less-than-optimal in meeting the new needs of data scientists.
As a result, most have resorted to dumping data into delimited text files (or similar form) and importing it into notebooks, where they can begin prepping data for the real data science work of data exploration, modeling and deployment.
In addition to being inefficient and introducing governance issues, the dumping of partial data sets into this sort of ad-hoc data science pipeline also fails to solve the real issues facing data scientists: the need to create a streamlined pipeline that enables them to collaborate, scale their efforts, and rapidly move data science projects from inception to production.
Creating this type of streamlined data science pipeline requires, however, that organizations reimagine their data infrastructure for a data-driven world.

Data Science is Getting Harder When It Should Be Getting Faster
While data scientists struggle with creating a modern and streamlined data science pipeline, the growing importance of data within the enterprise – and, therefore, the number of stakeholders vying for control of it – has made doing so more challenging.
Within the enterprise, there are now countless teams that are responsible for data in some way. Various groups are accountable for things like data governance, data security, and privacy – and while data scientists (and the business value they create) demand speed and agility, these stakeholders often see only risks.
At the same time, the number of data consumers has increased rapidly, creating contention within the enterprise as teams jockey for control, priority, and access.
The net result for data science teams is that while the volume and complexity of data are increasing, and while demand for these data-driven, intelligent applications grows, it is getting harder for them to overcome the overhead and rigidity this contention creates.
This situation has reduced many data science teams to using data subsets when building their models — both to overcome the weight of data wrangling activities, and to cope with governance and access restrictions.
While this data subset approach helps teams deal with their present-day issues, it puts them at risk when it matters most: as their models go into production.
Using data subsets, models are more likely to suffer from deficiencies or not be adequately optimized for performance. It's just too difficult to deliver the results that organizations now need to drive competitive value in the market when data science teams have one hand tied behind their backs.
This perfect storm of complexities and challenges leads to an obvious conclusion: organizations need to transform traditional data pipelines into modern data science pipelines that balance the need for data governance and control with the speed, agility, and end-to-end integration that data scientists seek to create the data-driven applications that are now the engine of business value.

A New Generation of Data Platforms Closing the Gap
Thankfully for enterprises, the challenges data science teams face in creating this type of end-to-end data science pipeline have not gone unnoticed.
Next generation data science platforms, such as Iguazio, are emerging, entirely reimagining the data science workflow.
These new platforms help organizations create data science pipelines that simultaneously streamline the entire process, while adhering to data governance and privacy policies. These platforms take a radically different approach to data management and integrate the end-to-end process to help data scientists shift their efforts away from data cleansing, wrangling activities, and environment management, and instead focus the majority of their energy on exploration and model development.
Central to this reimagining is the ability to leave data in native platforms and continually pull it directly into work environments, while dynamically cleaning and tagging it. Avoiding the slow and laborious ETL process, which inherently creates aged data (and which is endemic to traditional data pipelines), is essential in a world in which data is changing rapidly and continuously.
Platforms like Iguazio are achieving this shift using a combination of streaming data capabilities and serverless technologies (such as its open source Nuclio solution), that enable organizations to access data in real-time, including timeseries data, which can dramatically impact model development in certain circumstances.
Beyond simplifying access to data and making that access continuous and realtime, however, data platforms like Iguazio are also changing the dynamics of the workflow itself.
The ability to directly integrate all elements of the workflow into the model creation process is essential to the reimagining of the data pipeline. For instance, Iguazio directly integrates Jupyter, Spark, TensorFlow and other data science toolsets into its central management module as part of its managed offering. This enables data scientists to remain focused on their craft rather than on data and environment management mechanics.
But while this reimagining of the data pipeline dramatically improves the workflow for data scientists and helps to refocus their time and energy more productively, the greater value may come from how this new data science pipeline enables substantial improvements in exploration, model training and performance, and the deployment of models into production.
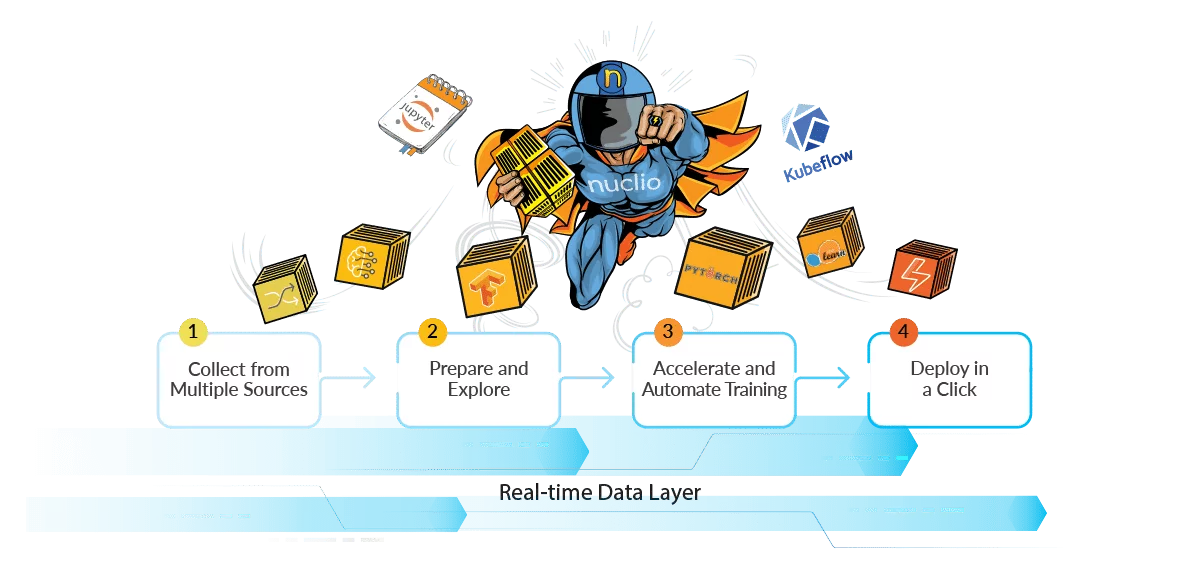
How Iguazio Delivers a Continuous Data Science Pipeline and Speeds the Creation of Intelligent Applications
As organizations grapple with the complexity and challenges of developing a data science capability, it is easy to lose sight of the fact that developing that capability is the means, but not the ultimate objective.
The entire reason data science teams exist is to help organizations leverage data to create some form of competitive advantage. Generally, that requires that they leverage their data to create intelligent, data-driven applications.
Here too, the emergence of next-generation data platforms like Iguazio can be an essential enabler as organizations seek to develop models and deploy them into production within these intelligent apps at an ever-increasing rate.
As organizations look to decrease the time it takes to develop and deploy this new type of data-driven application, they are often hindered by long-training times, the need to retrain models continuously, and the difficulty of monitoring and updating models in production as business drivers and the data landscape continuously change.
The integrated and streamlined data science pipelines that Iguazio provides enables benefits like distributed model training across multiple tools, including Spark, Presto, and Python Dask. This is a particularly potent capability when that distributed training can occur across various configurations, including GPU acceleration, such as is possible with Iguazio's approach.
This integrated, yet distributed method enables organizations to improve training performance. But it’s not the only way that these new approaches help organizations speed time-to-delivery of these applications.
The ability to use continuously updated data during model training helps organizations avoid one of the most significant deployment bottlenecks: the need to continually retrain models because training data does not match production data.
Beyond model development and training, however, organizations are increasingly focusing their attention on the deployment and monitoring of models in production, particularly as they begin implementing intelligent applications at-scale. Using data-centric platforms, such as Iguazio, helps organizations reorient their management paradigm away from the pipeline and to the data itself.
In practice, that means that these platforms become the central hub from which data scientists convert models into production, collaborate on development, and dynamically monitor and update deployed models. Key to these capabilities is Iguazio's serverless functions, which enable the platform to seamlessly bridge the gap between development and production.
The Intellyx Take: Getting Out of the Data and Environment Management Business
The data science function is now a critical enterprise capability. To maximize its value to the organization, however, data science leaders must be bold, must transform traditional data pipelines into continuous data science pipelines, and must relentlessly focus their efforts on the ability to rapidly create and sustain the intelligent, data driven applications that the modern organization now needs to compete. To do so, those responsible for the data science function within enterprises must focus on one thing: getting their data scientists out of the data and environment management business. Every moment that a data scientist spends finding data, massaging it, getting it where it needs to be, waiting for training to occur, retraining models because they had incomplete or inaccurate data, or managing the environments they need to perform these actions, is time wasted — and time that is not creating value for the organization. It is now clear that incremental adaptions of existing data pipelines will not be sufficient to help organizations free their data scientists to spend the majority of their time on those activities that create value. Instead, organizations should be looking to next-generation platforms, like Iguazio, that will allow them to create new data science pipelines, and reorient their data scientists away from the functions of data and environment management, and towards the activation of data through intelligent applications. In short, they need to break free of the belief that the dirt road they are on is the only road possible and, instead, think about how they can pave it. It is only through this reimagining that organizations can bring everything together so that their data science teams can stop thinking about data, and instead put it to work.
Charles Araujo, Principal Analyst, Intellyx
Charles Araujo is an industry analyst, internationally recognized authority on the Digital Enterprise and author of The Quantum Age of IT: Why Everything You Know About IT is About to Change. As Principal Analyst with Intellyx, he writes, speaks and advises organizations on how to navigate through this time of disruption. He is also the founder of The Institute for Digital Transformation and a sought after keynote speaker. He is a regular contributor to CIO.com and has been quoted or published in Time, InformationWeek, CIO Insight, NetworkWorld Computerworld, USA Today, and Forbes.

