Concept Drift in machine learning is a situation where the statistical properties of the target variable (what the model is trying to predict) change over time. In other words, the meaning of the input data that the model was trained on has significantly changed over time, but that the model in production doesn’t know about the change and therefore can no longer make accurate predictions.
Concept Drift vs. Data Drift
The term “concept drift” refers specifically to the accuracy of the model. Data drift is a phenomenon where the data underlying the model has changed significantly. Most data science practitioners lump virtual drift—sometimes called data drift—together with concept drift. Both concept and data drift cause a decay in model accuracy, but they need to be addressed separately.
Concept drift can, and does, occur in many use cases. A classic example is spam detection. Email content and design change constantly, an example of data drift. Because the training set of email data changes constantly, the feature space representing the collection changes. Also, email users themselves sometimes change their interests, and can start or stop considering some emails to be spam, which is an example of concept drift.
What does concept drift look like?
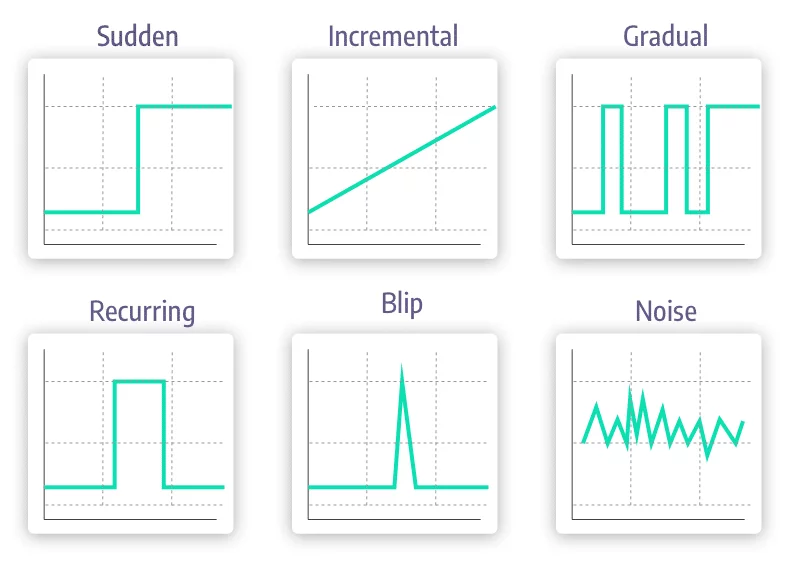
Concept drift changes can be: Sudden: The shift between one concept to a new one happens suddenly.
An obvious example of this is the start of the public COVID-19 lockdowns in March 2020, which abruptly changed population behaviors all over the world. Incremental / Gradual: The transition between concepts occurs over time, as the new concept emerges and develops. The yearly shift from summer to winter is an example of gradual drift. Recurring / Seasonal: The changes re-occur after the first observed occurrence. An example of this type of drift is the annual seasonal weather shift, that prompts consumers to buy warm coats in colder months, then halts demand once temperatures rise in spring, and then begins again in the fall.
The way in which drift occurs in a specific use case can have a lot of influence over how it should be handled. If sudden drifts in a particular use case can be reasonably expected, a concept drift detection system for a rapid change in our features or predictions should be implemented as a key part of the entire pipeline. However, if the same detectors in a gradual drift use case were to be implemented, it would almost certainly fail to detect the drift at all, and system performance would start to deteriorate.
What is a Drift-Aware System?
Simply deploying models to production without any monitoring system risks model performance deterioration over time due to concept drift. But monitoring isn’t enough. Once drift has been detected, ML teams need to decide how the system should respond.
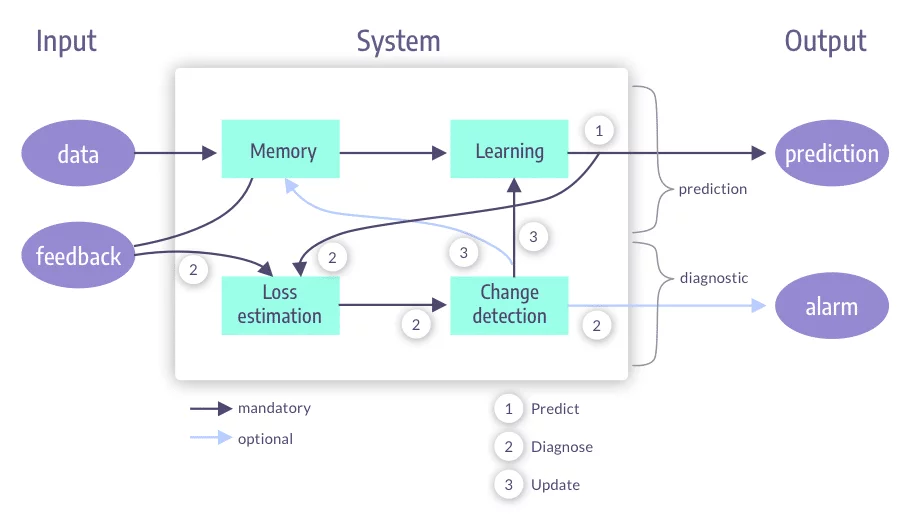
There are four main parts of a drift-aware system:
Change detection
Memory
Learning
Loss estimation
Change Detection
When a model is live, and concept drift in production is detected by the model monitoring system, an alarm can be triggered for any type of relevant change, which in turn triggers a learning or memory process.
Memory
When new data for prediction comes in, ML teams must consider how it will be used to train the model later on. Online learning can update the algorithm’s knowledge for every sample it encounters, coupled with a forgetting mechanism to adapt to the latest concept changes. Essentially, the model can learn to adapt to changes over time, and forget what is no longer relevant.
Models can also be trained in batch, as is done in the majority of cases, in which case the model should be updated periodically (also known as re-training).
Learning
Once datasets for the models have been created, the next step is to combine learning components to generalize from the examples and update the predictive model from the evolving dataset.
Loss estimation
Loss is an indicator of a bad prediction, and is expressed as a number that measures how bad the model’s prediction was on a single example. The goal of the model is to minimize the errors across every prediction it makes. Over time, the drift-aware system learns to reduce errors in prediction.
Deploying a Concept Drift Aware ML System
Concept drift is a natural part of an ML system. To ensure that models deliver value over the long term, ML teams need to consider some core components to deploy an ML system to production easily and safely.
Some use cases require the real-time collection of data, so the monitoring solutions should include incoming online features, model predictions and the relevant monitoring metrics produced in the process.
Any monitoring solution will require dashboards, and it helps if they’re pre-configured to track data and concept drift, and enable customized alerts.
The deployment and orchestration of complex data and prediction pipelines is a big task for any size team, especially once there are several models to manage. To decrease manual work and automatically keep models up to date, ML teams can use automatic retraining, which triggers the entire training pipeline to produce a production-ready challenger model.