Managing data for machine learning in general and feature engineering specifically are extremely resource intensive and costly endeavors for an organization, involving multiple team members in various roles that are often spread across different business units. This complexity is one of the biggest obstacles confronting organizations that want to operationalize machine learning, and deploy AI applications in a repeatable and consistent way that creates real, ongoing business value for the organization.
Feature stores to the rescue.
Feature stores are a central place to build, manage and share features across different teams in the organization.
They help organizations save time and resources on rebuilding the same features, and ensure consistency and better accuracy across the organization. Perfect for scaling AI.
But a feature store for ML is much more than simply a repository for features, it’s a system that:
An ML feature store is a single pane of glass where you can manage all your features. Everyone–data scientists, ML engineers, DevOps, data engineers–can search for features, reuse them in new applications, and see statistics on them (including which features have been used, where they’ve been used, and what impact they’ve had on models).
The feature store is also a robust data transformation service, where practitioners can easily do aggregations, joins, filtering, and data manipulation. A simple Python SDK simplifies and abstracts the feature engineering and runs it under the hood, leveraging Spark or Dask in a distributed way, so that feature engineering can be done at scale. When a feature is ready, it can be immediately available for production.
A feature is an input variable to a predictive model. In ML, a ‘feature’ refers to the whole data set, and a ‘feature value’ refers to a single value from the data set. For example, a feature in a product recommender might be “number of transactions in the past month”, and a feature value within that set would be “7”.
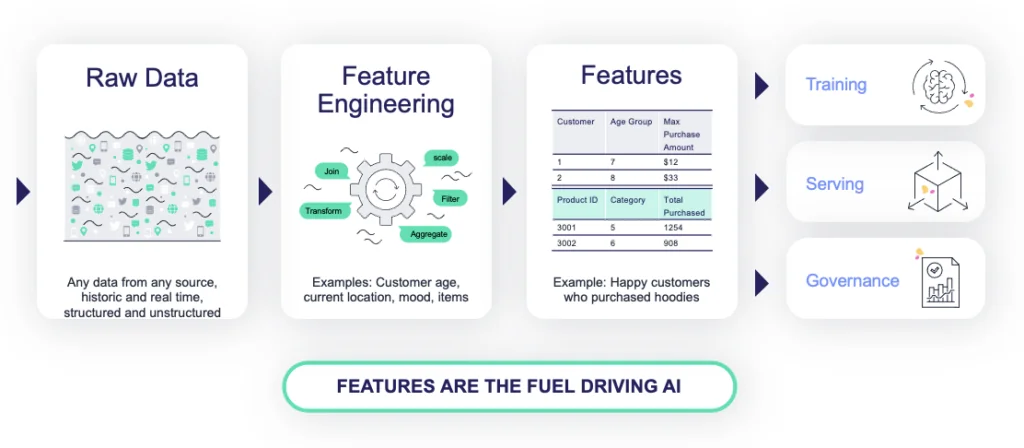
There are two kinds of ML features.
Offline features: These are static, historic features that don’t change much, and are processed in batch. Usually, offline features are calculated via frameworks such as Spark or by simply running SQL queries against a given database and then using a batch inference process. These features can be properties like patient age, a transaction location, or an IP address.
Online features: These features are dynamic and require a processing engine to calculate, sometimes in near-real time. They often need to be served in ultra-low latency. For example, calculating a z-score for real-time fraud detection. In this case, the pipeline is built by calculating the mean and the standard deviation over a sliding window in real time. These calculations are much more challenging, requiring fast computation as well as fast access to the data. The data can be stored in memory or in a very fast key-value database. The process itself can be performed on various services in the cloud or on an MLOps platform.
An even more complicated type of feature is engineered by using an ML process to generate the feature from a data set. An example of this might be to create a “contains a positive product review” feature by using NLP to identify tweets discussing a product in a positive manner.
As organizations are starting to heavily invest in machine learning, ML teams are facing huge operational challenges, and most of them are around data.
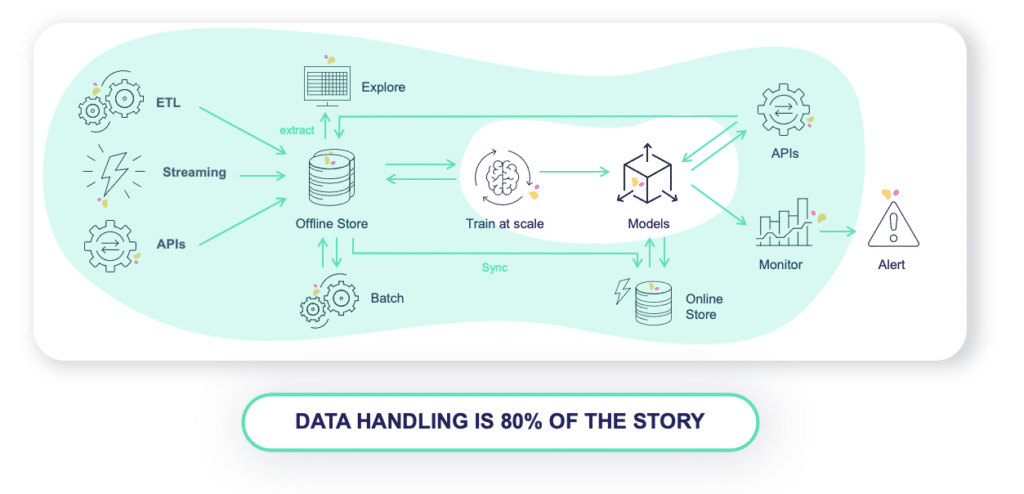
Data engineers, data scientists, and MLOps engineers typically work on different platforms with different tools, which causes significant duplicative work and prevents collaboration. With so many new business services relying on ML, the number of features and projects quickly becomes unmanageable without an intentional strategy. ML teams need a good comprehensive overview of the features available, since there are just so many. Instead of developing in silos, the feature store allows us to share our features along with their meta data with our peers. Unfortunately, it’s common for teams in the same organization to develop similar solutions, simply because they are unaware of each other’s tasks. Feature stores bridge that gap and enable everyone to share their work and avoid duplication.
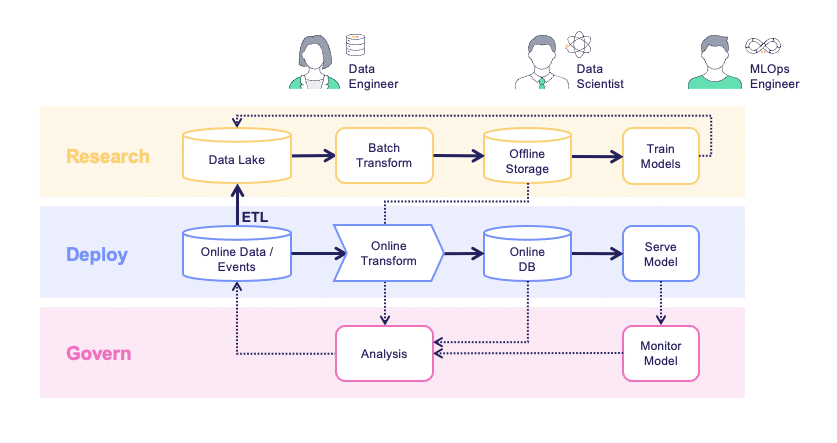
The concept of a feature store is to abstract away the engineering layers and provide easy access to everyone for reading and writing features.
A data scientist looking for a feature can use a simple API for retrieving the data that he needs, rather than writing engineering code. It could be simple as running the following:
df = feature_store.get(“transaction_volume”).filter_by (transaction_id)
Once a feature is in the repository, it can be reused in any application, immediately. This ‘build it once’ approach saves significant development time, especially as investment in ML projects grows and the number of teams and models across the organization increases.
There are a couple of ways that feature stores can improve model accuracy.
First, in addition to the actual features, the feature store keeps additional metadata for each feature. When selecting features for a new model, data scientists can inform their choices by analyzing the features’ impact on similar existing models.
Second, feature stores maintain a consistent feature set between the training and serving layer, so that the trained model more accurately reflects the model in production. Having different implementations for training and deployment can significantly impact model performance. Feature stores provide all users with access to a consistent library of features across projects, teams, and environments.
Compliance is a critical requirement for any enterprise feature store. In order to meet guidelines and regulations, especially in verticals with sensitive data like Healthcare, Financial Services and Security, the lineage of algorithms being developed must be tracked. A feature store keeps the data lineage of a feature, providing the necessary tracking information that captures how the feature was generated and provides the insight and the reports needed for regulatory compliance.
Tech companies that use ML as a core part of their offering like Twitter, Netflix and Uber have famously built their own feature stores in-house. This approach is extremely time consuming and costly, which may make sense in the long run for a large company with deep resources. For the rest of the industry, using an off-the-shelf feature store is an inexpensive solution that will save massive time and effort, and will enable even small teams to deploy AI to production much more efficiently.


