We’ve all heard the expression “Garbage in, garbage out.” It expresses the simple truth that the quality of the output is inevitably dependent on the quality of the input.
In recent years, Machine Learning (ML) practitioners have fully embraced this concept, and data processing has rightfully converged towards being the central piece of ML modeling pipelines in production.
Data comes in various formats, and data processing consequently takes different shapes.
In this article, we’ll focus on image processing, i.e., data processing applied to images for computer vision tasks.
Computer vision (CV) is a subfield of machine learning that enables computer programs to derive meaningful information from visual inputs.
To understand how CV works, it’s useful to look at its most studied application: image classification.
Image classification aims to assign one or more labels to an image provided in the tensor format of its numerical pixel values. It most typically achieves this by using convolutional neural networks:
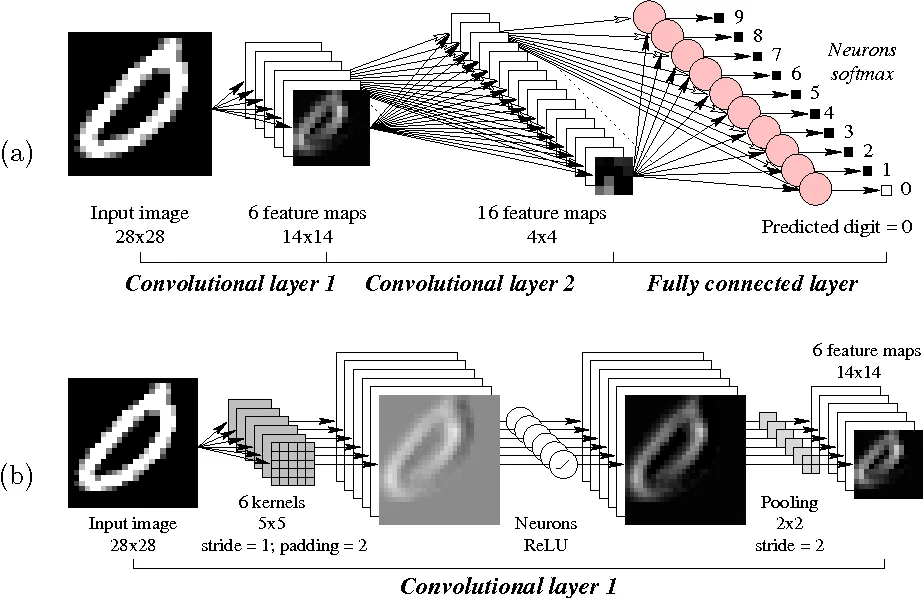
Figure 1: A convolutional neural network for MNIST (Source: Semantic Scholar)
This specific implementation of neural networks is designed so that the network is able to learn abstract features like edges and corners in the lower layers and more specialized features like the shape of an eye in the top layers. Of special interest is the next-to-last layer, which is a fully connected layer representing a condensed feature embedding of the original pixel image, and the last layer, which maps this embedding to each label.
Other CV applications are object detection, video tracking, and pose estimation.
We’ve already explored the concept of “Garbage in, garbage out” and how it exemplifies the importance of data processing.
In addition, image processing is particularly relevant for a few reasons.
Firstly, CV tasks require extremely large data, and training these extremely large models is tremendously expensive. It is common practice for companies creating these models, such as OpenAI, to open-source their architectures and trained parameters.
While it is possible to fine-tune these pre-trained models via transfer learning, i.e., replacing the last layer of the neural network with one or more use-case-specific layers, image processing is the real main point of development for real-world applications.
Images can also be confusing even to the human eye:

Figure 2: Is this a cat or a croissant? (Source: Nina Barzgaran)
Being able to select, standardize, and augment images with processing techniques is fundamental in making such complex tasks more tractable in an automated way.
Last but not least, it is important to note that the input to CV models always includes an image; in fact, sequences of images are used for video-based applications.
Image processing is the series of operations aimed at improving the quality of images for computer vision tasks so they can be more predictive.
When it is aimed at improving the quantity of images, it is referred to as image or data augmentation.
The fundamental difference between the two processes is that image preprocessing is applied both at training and inference time, while data augmentation is only applied at training time and after image processing.
The input to these processes is a feature vector of raw pixel intensities in an HxWxC format, where H is the height in pixels, W is the width in pixels, and C is the number of color channels.
Image processing techniques focus on adjusting the pixel values and shape of the image to stabilize the mathematical problem for the model. These techniques are:
Image augmentation techniques are far more numerous, and the best way to understand the transformation that they apply is visually:

Figure 3: A visual overview of data augmentation techniques (Source: Barış Özmen)
The goal here is to enrich the training set with additional image scenarios so the model can better generalize to real-world image-capturing scenarios, such as different camera resolutions, lighting conditions, or shot angles.
Deciding which data augmentation techniques to apply should be part of the fine-tuning process, and you should try out a few different ones in various combinations.
The landscape of image processing frameworks for ML is broad, and deciding on which one to select can be confusing. These are the 10 most used image processing frameworks for ML:
While third-party solutions or even custom solutions may be needed for very unique ML use cases, the vast majority of CV applications adopt open-source frameworks for image processing.
All frameworks provide standard techniques for both image processing and augmentation, only rarely with a slightly different mathematical implementation.
For illustration purposes, we can look at OpenCV and TensorFlow for examples of how these techniques are implemented. Specifically, we will take an image and 1) convert it to grayscale, 2) flip it, and 3) center-crop it.
OpenCV:
import cv2 as cv img = cv.imread('example.jpeg') gray_img = cv.cvtColor(img, cv.COLOR_RGB2GRAY) flipped_img = cv.flip(img, 0) def crop_img(img, scale=1.0): center_x, center_y = img.shape[1] / 2, img.shape[0] / 2 width_scaled, height_scaled = img.shape[1] * scale, img.shape[0] * scale left_x, right_x = center_x - width_scaled / 2, center_x + width_scaled / 2 top_y, bottom_y = center_y - height_scaled / 2, center_y + height_scaled / 2 img_cropped = img[int(top_y):int(bottom_y), int(left_x):int(right_x)] return img_cropped cropped_img = crop_img(img, 0.7)
TensorFlow:
import tensorflow as tf img = tf.io.decode_jpeg( tf.io.read_file('example.jpeg'), channels=3, ) gray_img = tf.image.rgb_to_grayscale(img) flipped_img = tf.image.flip_up_down(img) cropped_img = tf.image.central_crop(img, 0.7)
When looking at the output from applying these transformations on the example image, we would expect the same result to be obtained with both solutions:

Figure 5: Image transformations applied with OpenCV (on the left) and TensorFlow (on the right)
Indeed, the two frameworks provide identical outputs.
This simple example shows how we can safely select any of the most popular frameworks for image processing and be confident that it will typically cover our requirements or, at worst, that it will be seamless to switch to a different one.




