All machine learning (ML) models follow a lifecycle that is divided into two cyclical phases: model development and model deployment.
While model deployment is typically done in an interactive Jupyter notebook, as it is a highly experimental phase, putting models in production demands automation and scalability. Moving between these two phases is most typically where ML projects fail.
Building on top of well-established DevOps practices, MLOps processes and tools focus on combining development and operations to enable production-grade ML lifecycles.
Kubernetes, a DevOps tool open-sourced in 2014 and since adopted by over half of organizations worldwide, has similarly become the preferred MLOps tool to manage automated machine learning pipelines in a reproducible, safe, and scalable way.
Kubernetes is a container orchestration tool. So to understand what it is exactly, we need to understand what containers are and how they revolutionized the industry.
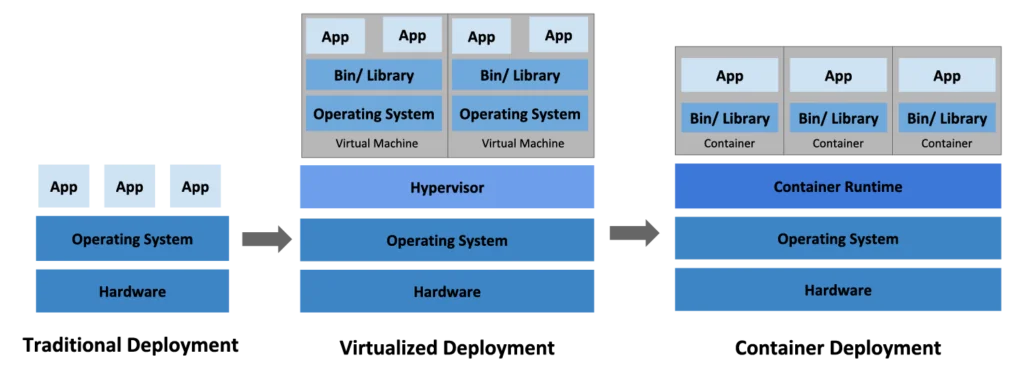
Figure 1: The history behind Kubernetes (Source: Kubernetes)
Originally, applications used to run on a dedicated server and were thus constrained by the hardware and OS available.
To speed up deployment and improve portability, virtualization was introduced, allowing for the abstraction of application code and environment in a virtual machine. Multiple virtual machines can run on the same hardware to reduce resource waste, with the hypervisor allocating processors, memory, and storage among them.
Still, virtualizing the physical hardware is a slow process. Containers successfully reduce deployment time to seconds by sharing the machine OS kernel so that each container hosts only the code, configurations, and packages that the application depends on.
Containers have the unique advantage of being lightweight and portable across on-premises and cloud systems.
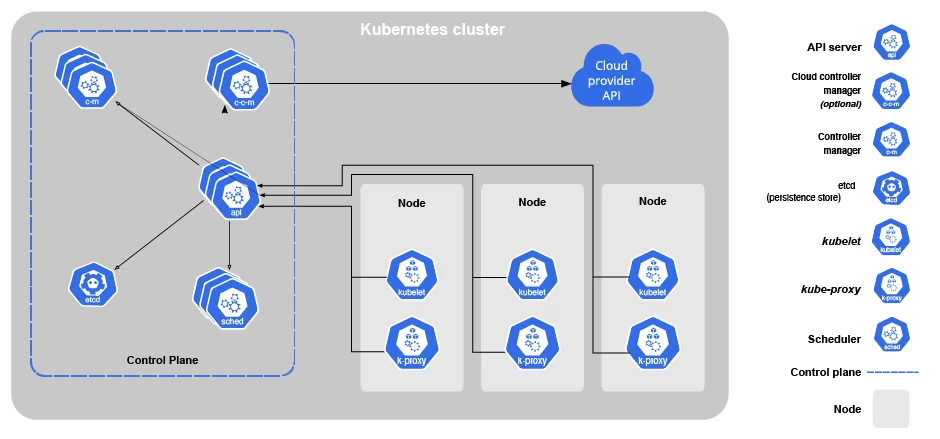
Figure 2: Architectural view of Kubernetes components (Source: Kubernetes)
As a container orchestration tool, Kubernetes lets you manage multiple running containers with zero downtime. It also features autoscaling, failovers, load balancing, and more—all of which would be near to impossible to achieve manually—plus well-defined deployment patterns and amazing community support.
The collection of installations, application code, and dependencies required to configure an application environment is defined in an “image.” Docker is the preferred tool to create images:

Figure 3: An example Dockerfile (Source: Docker)
Images are defined in a Dockerfile and organized in layers, where the lower in the hierarchy a layer is, the less it is expected to change over time. This is to optimize deployment efficiency, as layers are automatically cached after the first build. The example shown covers the typical steps for defining most images:
When the image is running, it is then called a “container” and managed by container orchestration tools such as Kubernetes.
To run an image on Kubernetes, we would typically have to define a series of YAML configuration files with a minimal setup containing the following files:
We can then use Kubernetes’ command-line tool, kubectl, to apply the configurations.
Kubeflow is Kubernetes for ML.
More specifically, it is an open-source machine learning platform built on top of Kubernetes that makes the development and deployment of ML workflows simple, portable, and scalable.
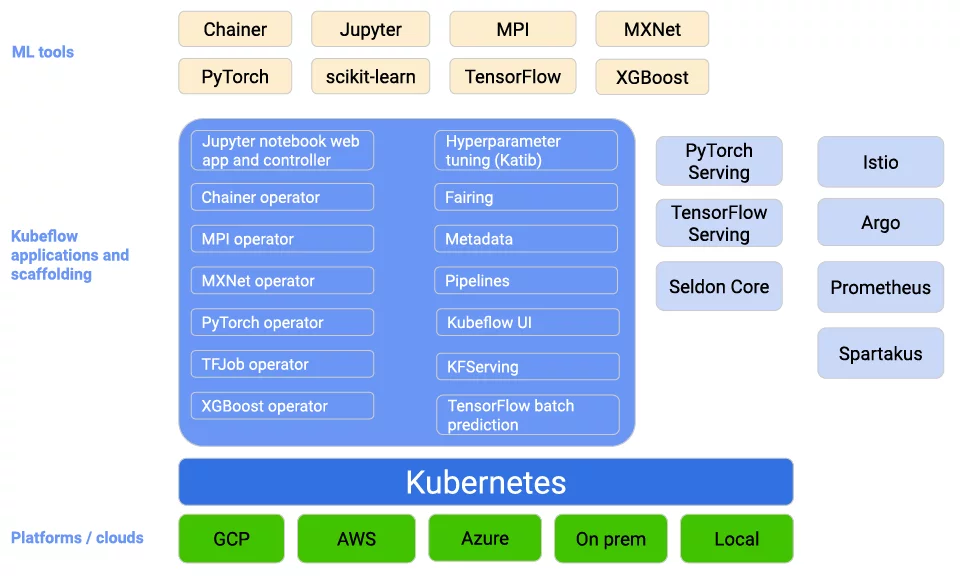
Figure 4: Architectural view of Kubeflow components (Source: Kubeflow)
While Kubeflow supports model deployment by providing direct integrations with model serving frameworks such as TFServing, KFServing, MLRun and Seldon, its main focus is model development.
There are three main Kubeflow components supporting model development:
Figure 5: Kubeflow’s central dashboard with a view of multiple tools on the left menu (Source: Kubeflow)
Last but not least, Kubeflow comes with a pre-built central user interface, which makes it easy and enjoyable for practitioners to adopt it.
As mentioned before, Kubernetes supports end-to-end production-grade ML lifecycles.
Automating training pipelines with Kubernetes is not a common practice because of its steep learning curve. While it is common for engineers to use Kubernetes for a broad set of applications, it is not a common skill required for data scientists.
Still, containerizing training pipelines is bound to become the new standard, as it leads to the well-known benefits of scalability, modularity, portability, and reproducibility.
In a Kubernetes-based training or batch inference pipeline, each task is a Dockerized container with well-defined inputs, logic, and outputs. A pipeline is composed of multiple tasks, each running with its own hardware and software specifications to optimize performance.
As previously mentioned, Kubeflow provides this capability with its Pipelines.
The most common application of Kubernetes is to deploy microservices, so real-time ML inference is the most natural application of Kubernetes for MLOps.
Not only is it easy to select and deploy any framework, but Kubernetes’ inherent scalability makes it easy to optimize real-time applications for latency and throughput.

Figure 6: A simple FastAPI app for model serving
Since Kubernetes abstracts container orchestration for us, model serving is as simple as creating an app like the one in the demo code above, creating a Docker image to deploy it from and running it on Kubernetes.
Kubernetes and Kubeflow are open-source systems, so it can be difficult to choose between self-managing or selecting one of their many managed solutions.
After all, most MLOps products are built on top of them.
Having said that, unless you demand extremely custom requirements, it is never recommended to opt for a self-managed solution. Managed Kubernetes and Kubeflow solutions such as Iguazio are the best option, as they minimize engineering overhead and maintenance while providing a set of well-established MLOps best practices to follow.




