Only 10% or less of the overall code of a machine learning (ML) production system is ML modeling code. A complete machine learning infrastructure famously involves a much wider variety of engineering and procedural components, including data management, serving infrastructure, resource and process management, observability, and monitoring.
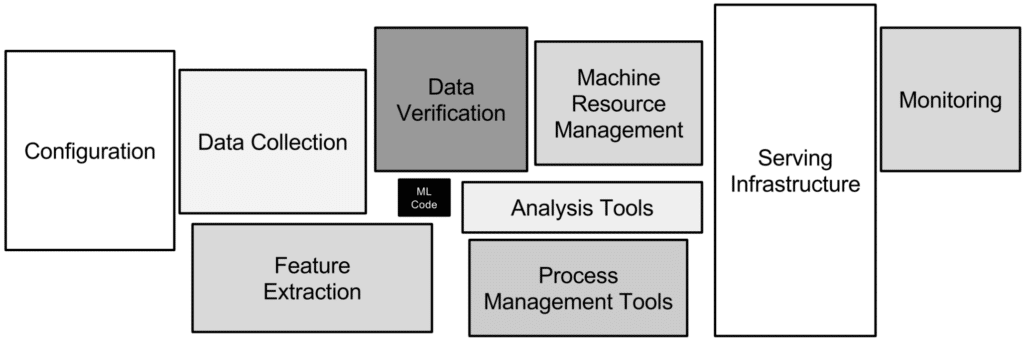
Figure 1: The components of an ML production pipeline (Source)
Because developing performant models requires a lot of time and resources, and given that each new machine learning application always comes with novel requirements, establishing a machine learning infrastructure that is robust, reliable, and scalable is the real differentiator of any successful ML unit.
In this post, we provide an overview of what a machine learning infrastructure is in relation to the end-to-end ML lifecycle and discuss the main benefits of implementing it correctly. We also explore deep learning and real-time inference, the two ML applications that require the most mature infrastructure design.
Machine learning infrastructure refers to both the software (i.e., tools and frameworks) and hardware backbone on which machine learning models are trained and deployed, as typically portrayed by a machine learning production architecture.
To understand how to successfully design a machine learning infrastructure, it is useful to review what the end-to-end ML lifecycle looks like and map the infrastructure components for each step.
There are eight phases in the end-to-end ML lifecycle:
Every ML initiative begins with a use case. Being centered on scoping and designing, this is the only phase of the ML lifecycle that does not map to an infrastructure component. Still, it is recommended to ensure early on that the proposed solution can be supported by the existing infrastructure or, if an infrastructure is not already in place, to start highlighting the main requirements for the ML model architecture and ensure feasibility.
This phase involves performing an initial investigation into available data, its quality, and its predictive power. This requires a data lake, data catalog, data ingestion pipelines, and data analysis tool. Data scientists need to be able to rely on the infrastructure to handle data consistently and securely.
In this phase, data is transformed into more representative features. Feature engineering builds on the infrastructure defined for the Exploratory Data Analysis phase to further provide a feature store capability that should be scalable, traceable, and fast.
This is when the ML model training code is created and fine-tuned. This phase requires computing infrastructure, as well as an experimentation environment, model registry, and metadata store. Here, it’s crucial to select a winning machine learning framework for modeling, such as scikit-learn or TensorFlow, which has tuned parameters that both provide the best offline performance and can be efficiently productionized given the chosen infrastructure.
This phase involves evaluating the trained model’s offline performance to ultimately create a model(s) report that can be reviewed by multiple teams. KPIs should be designed and reported from both a technical perspective (accuracy, roc curve, etc.) and business perspective (click-through rate, revenue, etc.). State-of-the-art infrastructures provide useful visualization and reporting capabilities, with the ability to easily compare A/B testing results as well.
This phase focuses on automating the development steps defined above for efficiency, reliability, and resource saving. To automate the pipeline, you will need a workflow orchestration tool that, ideally, seamlessly supports all the infrastructure components previously mentioned.
This phase involves getting predictions from the trained model, either in batch or online.
It requires CI/CD with thorough testing, endpoints, and APIs to be created with specific procedures for rollback, versioning, and more.
This phase ensures that dashboards and alerts are set up based on hardware metrics (such as memory utilization and number of retries), data and model metrics (such as feature fill rate and scores distribution), and business KPIs. Feature drift and concept drift are two very important scenarios to monitor here.
While these eight phases each have unique infrastructure requirements, they all need storage, compute, networking, access control, and security.
Similarly, together with the architecture, you should design processes that specify within-team and across-team collaboration, as well as how data, model and code are to be handled throughout the lifecycle. This involves ML development, which is typically handled by data scientists, and ML production, which is typically handled by ML engineers.
A well-designed machine learning infrastructure is flexible, scalable, highly performant, compliant, and highly available. Such an infrastructure can:
With a well-designed architecture also come well-defined processes and workflows that support a truly agile approach and reduce the friction towards moving models into production.
Deep learning training and real-time inference are the ML applications that most require a mature infrastructure.
A deep-learning infrastructure can support:
A real-time inference infrastructure can support:
When defining which components and maturity to introduce into your machine learning infrastructure, keep in mind that the more complex the solution, the harder it is to self manage. For mature ML businesses with enterprise-level requirements, and to future-proof any ML initiative, a managed with a cloud or third-party solution that provides end-to-end ML infrastructure is usually the best choice.
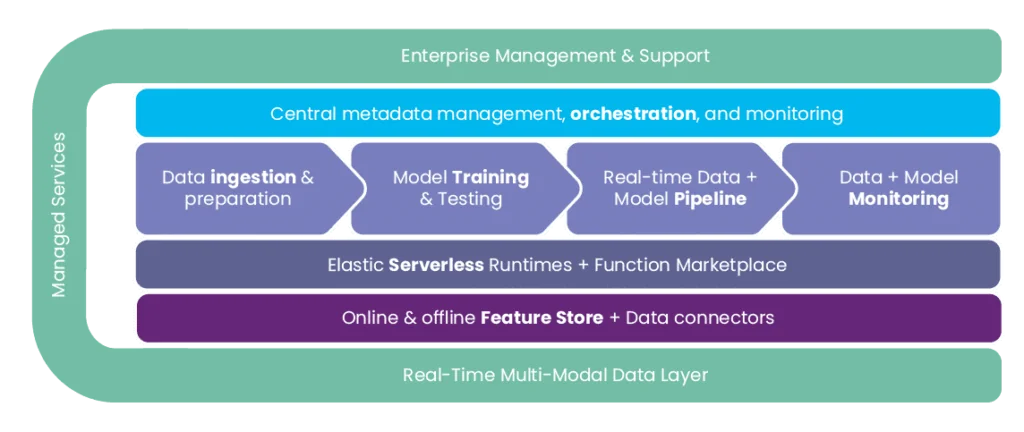
Figure 2: The Iguazio MLOps platform (Source)
Iguazio offers state-of-the-art machine learning infrastructure management with advanced capabilities, including GPU management, effortless orchestration of ML and deep learning pipelines, real-time feature engineering with an integrated feature store, and built-in end-to-end model monitoring.




