Building Machine Learning Pipelines with Real-Time Feature Engineering
Adi Hirschtein | September 30, 2021
Real-time feature engineering is valuable for a variety of use cases, from service personalization to trade optimization to operational efficiency. It can also be helpful for risk mitigation through fraud prediction, by enabling data scientists and ML engineers to harness real-time data, perform complex calculations in real time and make fast decisions based on fresh data, for example to predict credit card fraud before it occurs. A feature store can help make this process repeatable and reproducible, saving time and effort on building additional AI services. This blog post will explain how real-time feature engineering can be seamlessly performed with an online feature store, and how with seamless integration to an MLOps platform, model monitoring, drift detection and automatic re-triggering of training can be performed, keeping your models at peak accuracy even in changing environments.
This article is based on the talk Adi Hirschtein, VP Product at Iguazio, gave at the ML in Finance summit. You can view the entire presentation here.
ML Pipelines in Organizations
Companies invest a lot of time and resources putting together a machine learning (ML) team. However, 85% of their projects never make it to production. This is due to business as well as technical challenges.
Business Challenges in Building ML Pipelines
From the business side, silos between data scientists, ML engineers and DevOps make it challenging for everyone to collaborate on the machine learning pipeline in an efficient way. On top of that, organizations also need to incorporate aspects like security, network, management and logs. To answer these challenges, organizations need to come up with a strategy to build a “machine learning factory”, to seamlessly generate more and more machine learning models, on an ongoing basis.
Technological Challenges in Building ML Pipelines
From the technological side, the main obstacle is around data. Firstly, there’s the challenge of how to ingest and combine data from different sources (for example real-time data coming from mobile apps, social feeds, sensors and smart devices, as well as offline data coming from billing, CRM or ERP systems). Secondly, there’s the challenge of how to create, synchronize, access and monitor features—in an accurate and resourceful way. For example, finding an efficient and accurate way to run all sorts of transformations at scale. Examples of transformations include calculating aggregations for min, max ,std etc. on a sliding window, joining data from various sources, filtering data, and so on. Finally, there’s the challenge of how to make sure the same features are available for both training and serving, to avoid any risk of train/serve skew.
ML Pipelines in Real-Time
Taking these features from research to production is challenging enough, and doing so in real time is even more difficult. This is because real-time feature engineering requires running quick feature calculations with low-latency response times.
Let’s look at a Z-score calculation, for example. Simply speaking, Z-score is a statistical measure that represents how far a data point is from the rest of the dataset. In more technical terms, Z-score tells how many standard deviations away a given observation is from the mean. Let's say the Z-score is calculated by taking the current transaction amount minus the average amount over a period of time, and then dividing it by the standard deviation. When calculating the score in real time, those sliding windows are constantly moving along time and require calculating from live events and storing it in a fast key value for quick retrieval. This is because the calculations require an extremely fast event-processing mechanism, which can run complex algorithms.
On top of that, it is often required to enrich the feature vector with data from batch processing, like the user score. This turns the feature into a wide feature vector with a dynamic feature set that can be used in the serving environment.
Introducing the Feature Store
The most efficient way to create and share features that can be used for both development and production is by using a feature store. With a feature store, you take raw data, process it, and create features that can be used for machine learning models at scale. The source of the data could be a database, an object store, a data lake, http requests or events coming in from a streaming engine (e.g. kafka or kinesis). A good feature store empowers data scientists to create complex features using simple Python SDK. Under the hood, the processing engine can run as micro services on a distributed cluster using a variety of processing engines like Spark, Dask, Spark streaming, Nuclio etc. Once created, these features can be shared and reused across the organization.
In addition to being a catalog, a feature store provides a robust transformation service for complex transformations, like sliding window aggregations, joining different sets of data, filtering data, and more. Creating those features can be done using simple Python APIs without the need to involve data engineering and write Java or Spark code. It is all performed with the same logic, for both training and serving.
The features are kept in two types of storage: offline and online. An offline feature set is typically saved as parquet files on an object store and it is used for storing large volumes of training data.
The online feature store is saved in a fast key value database for a quick retrieval as part of an online model serving. The online feature store keeps the latest value of any feature for every key, thus allowing an online app such as fraud detection to get the latest features for a specific transaction in real time.
Getting Started on Real-Time Feature Engineering with a Feature Store
Iguazio offers an integrated online and offline feature store for real-time feature engineering. Let’s see how it works.
Step 1 - Data Ingestion & Feature Creation
The first step is to get the raw data and create and define the feature sets using a simple Python SDK. This can be done from a Jupyter notebook or IDEs such as Pycharm or Vscode. In this step the data scientist gets the raw data and starts building various features based on his assumptions on what features are more relevant for his model. This process is an iterative process, the data scientist needs to train the model on the set of features until the feature set definition is good enough and ready to be deployed for an operational pipeline.
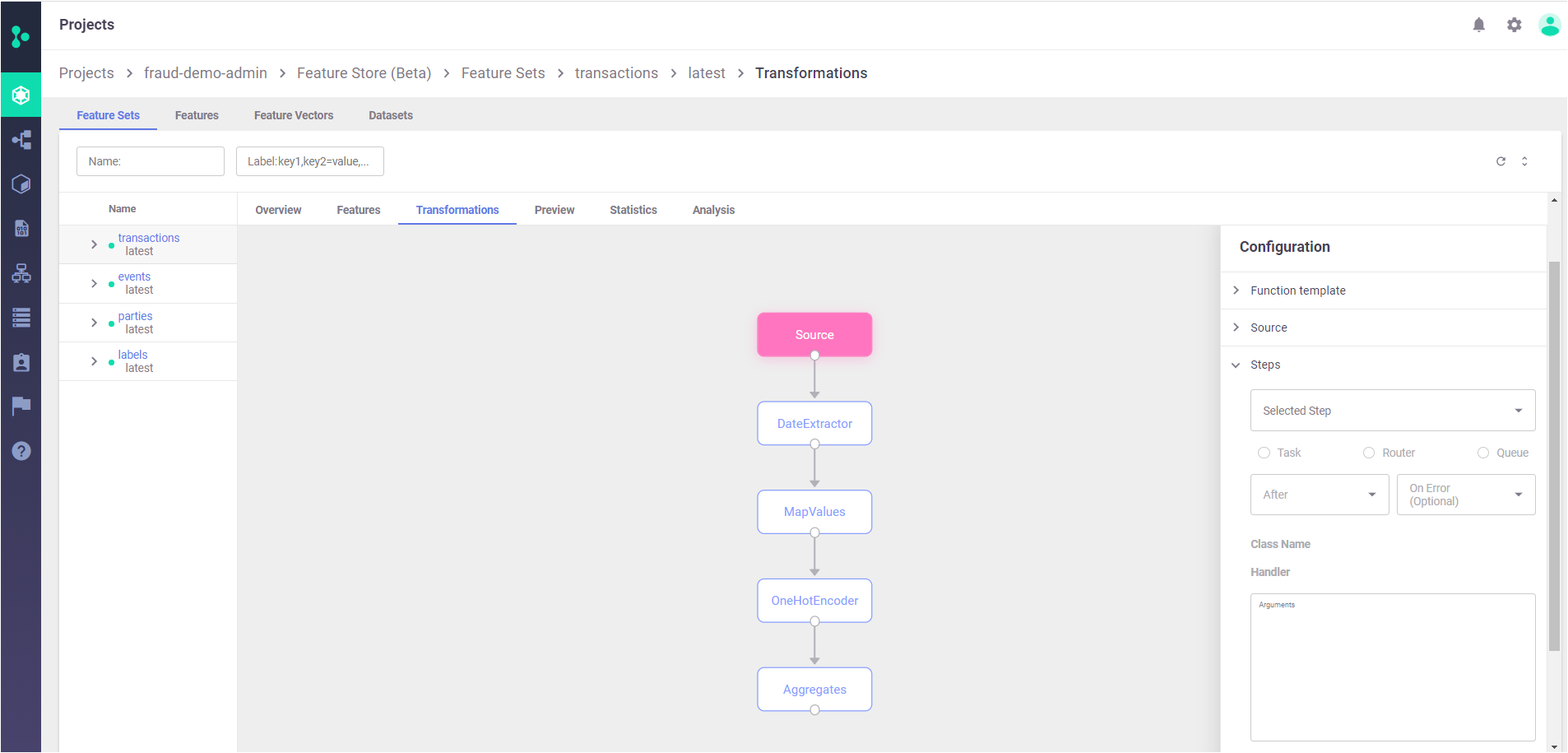
Step 2 - Model Training
Once the feature sets are ready, it’s time to create a feature vector which would be the input for the model. The feature vector is a logical definition that will be used for both model training and inference. It can be composed of features across multiple feature sets. Note that you can save the feature vector to a parquet file and then train the model with a versioned parquet file for better tracking and lineage.
In a typical scenario, the data scientist will run multiple experiments with different models and features till he gets to the “winning” models. During those iterations the feature sets and feature vector would be updated until the final version is ready for deployment.
Step 3 - Deploy a Real-Time Pipeline
Once the feature sets are ready, it’s time to take the same logic that was used for training the model and deploy a real-time function that runs the same logic, but this time the source will be live events coming from a streaming engine.
The important point here is that there is no need to re-write the code. The same logic and code are used, and when the deploy function command is run, a function is created with an endpoint that has a real-time graph consisting of all the relevant transformation processes as steps in the graph. This graph can scale up or down based on the workload and can support a large volume of events. The data ingestion itself goes to two places—an offline feature store which is stored as a parquet file and also to a fast key value database which the application will use for fast data retrieval to get the feature vector to the model in real time.
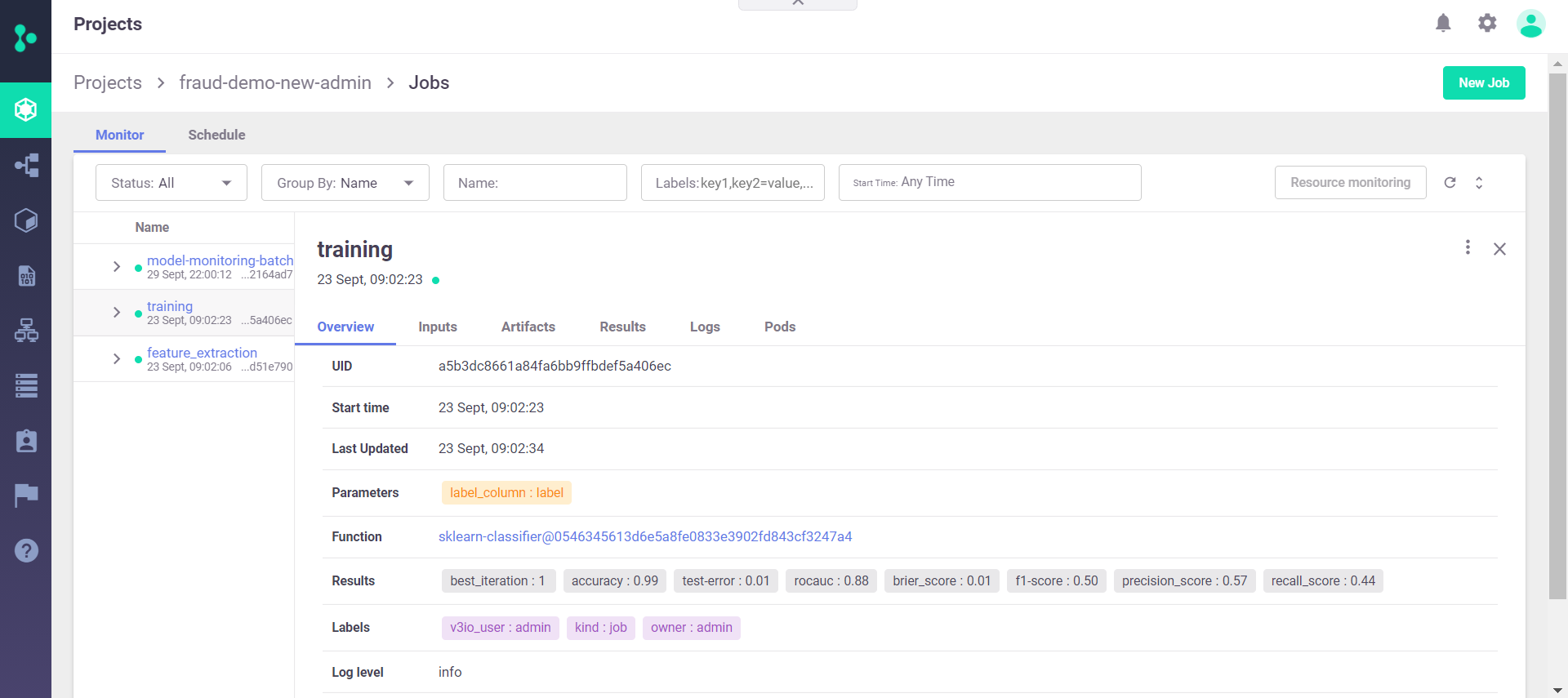
Step 4 - Model Serving and Monitoring
Once we have the model and the ingestion pipeline is ready, the next step is to deploy the model. The input for the model would be the feature vector that was defined in the previous steps, which has all the relevant features for running our model.
The Iguazio MLOps Platform provides model monitoring and drift detection out of the box.
The function that deploys the model can be set with “tracking” and as such it will run an internal mechanism in the platform that monitors the model endpoints and saves the feature vector and labels and runs a drift detection process that is based on both production data and the feature that was trained in the feature store.
When drift is detected, users can trigger an automated pipeline to re-train the model and the new training runs on a feature set that comprises the production data! And all of this can be achieved out of the box without any additional engineering effort.
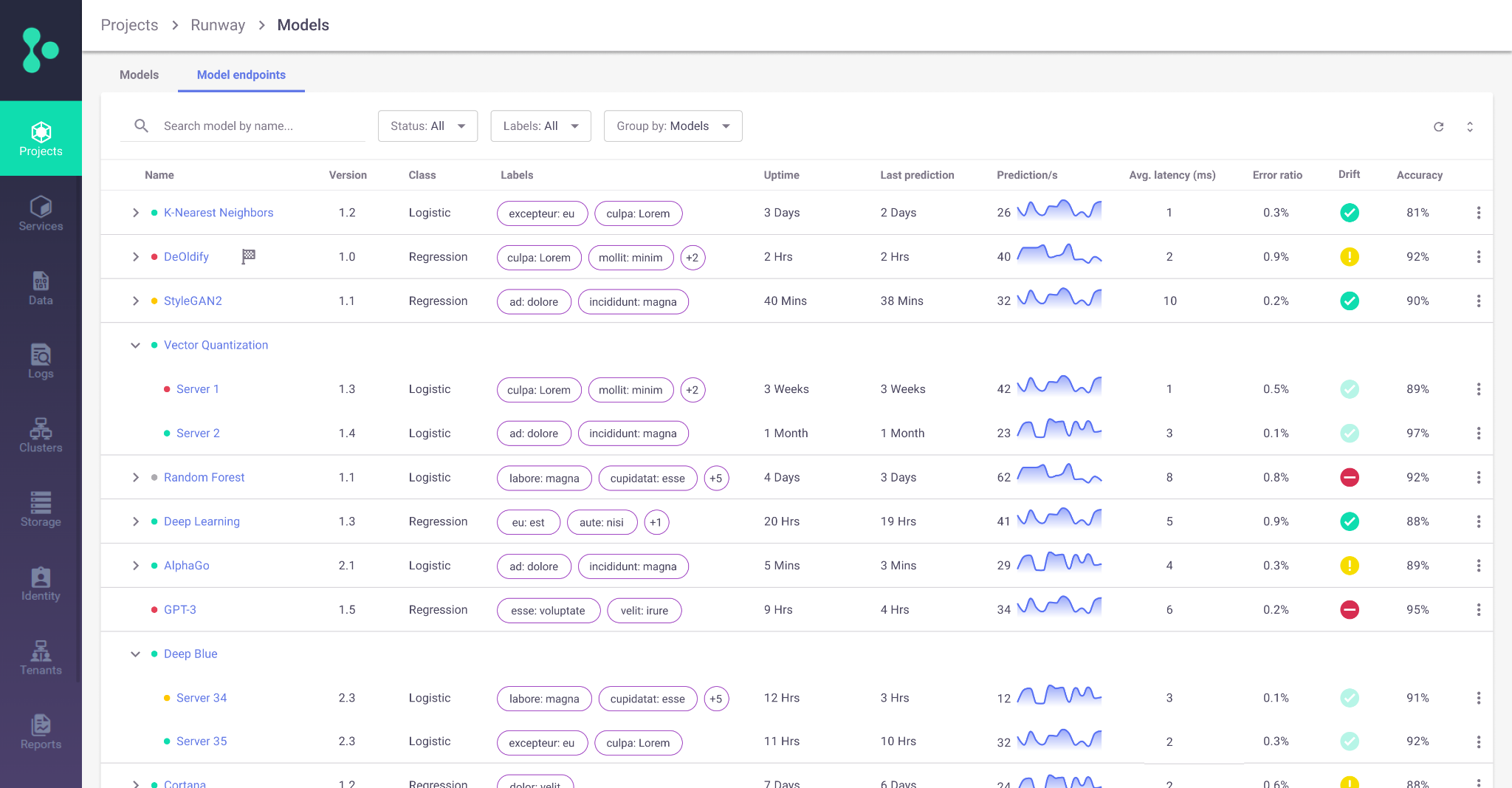
In addition to the SDK, Iguazio provides a rich user interface where users can easily search for features, feature sets and feature vectors along with detailed reports. For example, for each feature set, users can view its metadata, transformation logic, statistics, and more. Users can also get a view that links between models to the feature vector that was used for the training.
There are also sets of reports for model monitoring where users can view both operational views (e.g. transactions per second, latency, errors etc.) and model drift information. Drilling down from a model endpoint opens up all the relevant information on the features that are being sent to the model along with comprehensive drift information.
Conclusion
Real-time use cases like fraud prediction are complex to engineer, but with an online feature store, real-time feature engineering can be faster, more accurate and even efficient. A feature store is an important part of ML architecture for complex real-time use cases, because it enables the entire team to collaborate on building those complex features in a much easier way, monitor those features for potential drift and re-trigger a new training process that is based on production data. In addition, it automates a lot of steps in the pipeline in a way that minimizes the DevOps effort to virtually zero.
To learn more about the Iguazio Data Science Platform and feature store, or to find out how we can help you bring your data science to life, contact our experts.
To find out more and see the entire demo, check out this documentation, or watch the full recording of the ML in Finance session here:


