From AutoML to AutoMLOps: Automated Logging & Tracking of ML
Guy Lecker | August 23, 2022
AutoML with experiment tracking enables logging and tracking results and parameters, to optimize machine learning processes. But current AutoML platforms only train models based on provided data. They lack solutions that automate the entire ML pipeline, leaving data scientists and data engineers to deal with manual operationalization efforts. In this post, we provide an open source solution for AutoMLOps, which automates engineering tasks so that your code is automatically ready for production.
For more in-depth explanations and a live demo of the solution, you can watch the webinar this blog post is based on, here.
Experiment Tracking: Benefits and Challenges
Traditionally, machine learning models are developed by data scientists and engineers obtaining data from a data warehouse, a data lake or standalone files. They need to prepare it, train their model or use an AutoML service, evaluate the model for accuracy and finally generate a model for production.
This process needs to be tracked, so data professionals can understand how any parameter changes they make impact the model’s behavior and accuracy. Data scientists often use experiment tracking for monitoring and logging model results, since it provides them with better decision making (understanding which parameters and inputs yield the best results and reusing them in future models) and visualization (for better understanding the experiment results and model performance evaluation).
Experiment tracking can also help with tracking additional aspects of the ML workload:
- Accelerating the process of moving results from a successful experiment to production
- Simplifying pipelines - building and deploying pipelines in an easier manner by using the outputs of one step as inputs to another
- Profiling resource usage and optimizing code - to save on resources like CPUs and GPUs
- Collecting data and metadata required for production deployment automatically - ensuring the data is there instead of having to do it automatically.
- And more.
However, current experiment tracking solutions require many hours of manual work to implement and they do not address the full ML operational cycle.
What is the Full ML Operational Cycle?
In ML reality, data does not just land in a bucket or appear in a CSV or Excel spreadsheet format. Rather, it is generated from live data streams, like HTTP and API endpoints.
As a result, training takes place automatically over microservices and in a distributed fashion and results need to be stored in a manner that can be used in production. Finally, the production line is usually a pipeline, rather than a single endpoint, with gathering, enriching and monitoring data capabilities. These require a lot more operationalization efforts, which often takes place in the form of bloated code and glue logic.
The Solution: AutoMLOps
Tracking needs to span the entire ML pipeline and enable passing the data, parameters, results and models between the different steps of the pipeline. This does not just save resources and ensure efficient training, it also retrospectively tracks which parameters were used in each and every step in the ML pipeline - to enable monitoring and feedback. To support this, we need a database, common APIs or a metadata model.
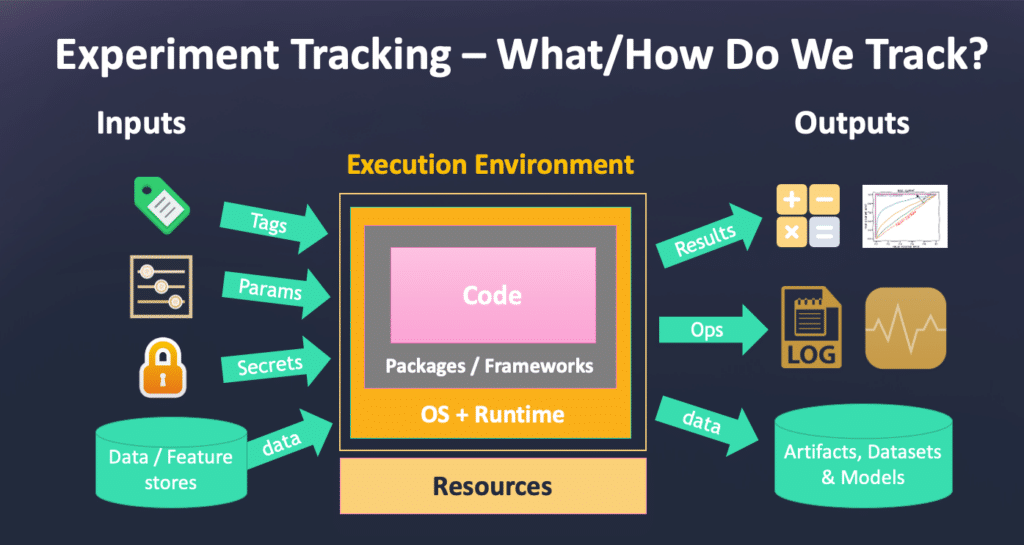
Incorporating AutoMLOps by provisioning and automating the MLOps pipeline with experiment tracking enables:
- Injecting parameters or code into our tasks and logging results
- Integrating with CI/CD, Git and reporting systems
- Distributing the workloads automatically
- Passing data to and from cloud resources and databases
- Gathering the data and metadata for operational aspects
- Security hardening and protection
- Versioning across components and steps
- And more
How can AutoMLOps be implemented?
Open Source Technologies for AutoMLOps: Introducing MLRun and Nuclio
MLRun and Nuclio are two open source technologies that can help with AutoMLOps. MLRun enables MLOps orchestration and Nuclio is a serverless processing engine, allowing automation of workload deployment for tracking and running the entire process. They operate by adding one line of code or calling one API call that will wrap your code and enable all the AutoMLOps features we mentioned.
MLRun does not support a full AutoML, but it does offer an easy AutoMLOps enablement to existing code. One of the ways is to use apply_mlrun - the one line of code that can be added to a training / evaluation function to connect it to the full AutoMLOps cycle. It will automatically take the model and log it to the system, enable tracking, auto-evaluation, and more importantly, take the model into production in one API call.
How Does MLRun Work?
MLRun consists of four components that all run on top of Nuclio’s serverless technology.
- Feature Store - for preparing and generating data
- Real-Time Serving Pipeline - online serving pipelines
- Monitoring and Re-training - for monitoring, drift detection and automated retraining
- CI/CD for ML - integrating CI/CD access code, data and models
Read more from the MLRun documentation here.
Serverless Deployment and Tracking with MLRun
MLRun operates on top of Nuclio’s serverless function architecture. With MLRun, data scientists or engineers can take a piece of code, push a button or call an API, and that piece of code will turn into a fully managed and elastic service. The piece of code gets compiled in a container along with its dependencies. They run in a sandbox and all tags, labels, parameters, etc. are pushed into your code automatically. Once the job finishes, the results and data are all tracked.
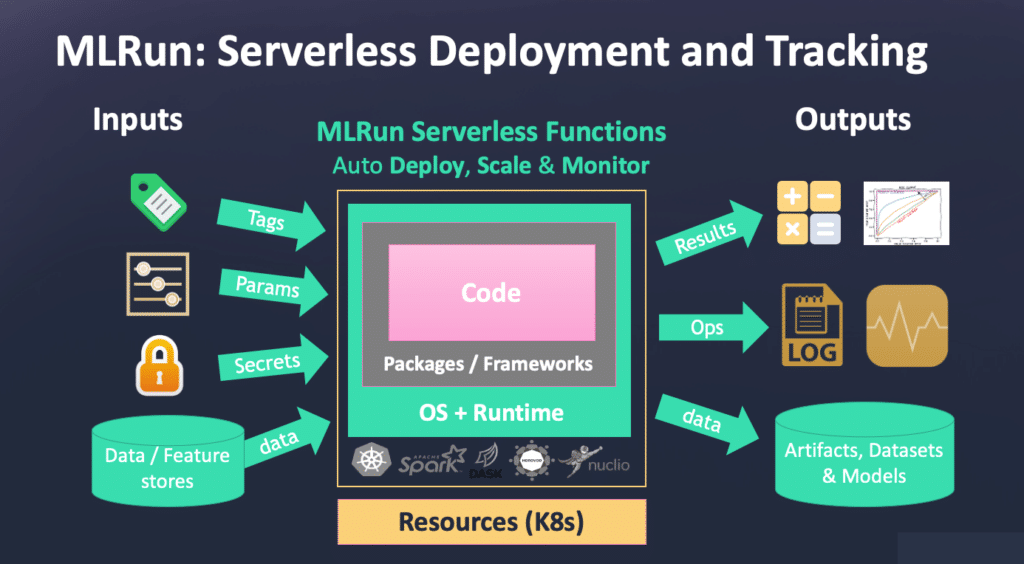
Automating MLOps with MLRun
This makes the entire MLOps process automated, instead of having ML engineers running manual and complex processes. Code can be built into a fully managed microservices in just one click or API call.
After adding a single line of code to our code (e.g, a training function), MLRun will automatically analyze it, and then it will:
- Log artifacts and metrics
- Add data lineage
- Log or save the model and its metadata
- Auto-scale the code
- Provide pipeline support
- Adapt GPUs
- Add checkpoints
- Add monitoring
- Automatically track and execute
- And more
The code is automatically ready for production, after inserting a single line of code.
Next Steps for AutoMLOps
AutoMLOps enables automating ML deployment tasks, so code is ready for production. Open source framework MLRun supports AutoMLOps, by:
- Converting code to managed microservices and reusable components
- Auto-tracking experiments, metrics, artifacts, data, models
- Registering models along with their required metadata and optimal production formats
- Auto-scaling and automatically optimizing resource usage (such as CPUs / GPUs)
- Codeless integration with different frameworks


