Future-Proofing Your App: Strategies for Building Long-Lasting Apps
Nick Schenone | May 29, 2024
The generative AI industry is changing fast. New models and technologies (Hello GPT-4o) are emerging regularly, each more advanced than the last. This rapid development cycle means that what was cutting-edge a year ago might now be considered outdated.
The rate of change demands a culture of continuous learning and technological adaptation. To ensure AI applications remain relevant, effective, secure and capable of delivering value, teams need to keep up with the latest research, technological developments and potential use cases. They also need to understand regulatory and ethical implications of deploying AI models, taking into consideration issues like data privacy, security and ethical AI use.
But building gen AI pipelines and operationalizing LLMs requires significant engineering resources. How can organizations ensure their architecture remains robust, resilient, scalable and secure, so it can support up-to-date LLM deployment and management?
The Solution: Designing Modular Pipelines with Swappable Components
To stay relevant and future-proof, applications need to be designed with adaptability in mind. One of the most strategic approaches to addressing this need is designing your AI architecture in a modular fashion, where different components of the pipelines can be swapped out or updated as needed without overhauling the entire system.
The benefits of a modular architecture include:
- The ability to easily upgrade components and modules in your framework with minimal adjustments.
- Reducing the risk associated with changes, since updates are confined to specific modules. This containment makes it easier to trial new features and roll them back if they don’t perform as expected.
- Updating a single component is less costly than redeveloping an entire application.
- Development time decreases. Teams can work on different modules in parallel and integrating new features becomes a plug-and-play process rather than a lengthy integration effort.
- Each pipeline can easily scale up and down based on demand and without affecting the other pipelines.
How to Build a Modular Gen AI Architecture
A resilient and adaptive gen AI architecture is made up of four distinct but interconnected pipelines—data, training/fine-tuning and application. This structure allows each component to evolve independently as new technologies emerge, without disrupting the overall functionality.
The 4 Gen AI Architecture Pipelines
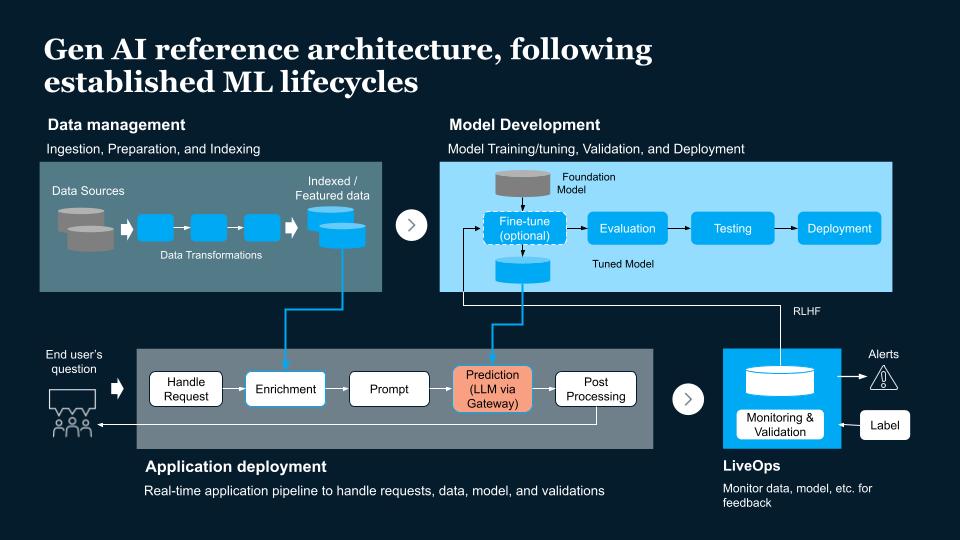
The four pipelines are:
1. The Data Pipeline
The data pipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data. This pipeline helps cleanse and prepare the data for model training and fine-tuning, supplies real-time data for responsive generative AI applications and supports RAG applications.
2. The Training/Fine-Tuning Pipeline
This pipeline ensures that the generative AI models are up-to-date and optimized for the specific tasks they are designed to perform. This includes:
- Initial training of the model on a large dataset to capture a broad understanding of the language or task
- Adjusting the model on a more specialized dataset to optimize performance for specific tasks or domains.
- Regularly evaluating the model against benchmarks and real-world tasks to ensure it maintains high accuracy and relevance.
An AI architecture can include multiple training pipelines for different models and datasets.
3. The Application Pipeline
The application pipeline is responsible for handling user requests, sending data to the model so it generates responses (model inference) and validation that those responses are accurate, relevant and delivered promptly. This is the model that brings business value to the organization.
4. The LiveOps Pipeline
This is a monitoring system for gathering application and data telemetry to identify resource usage, application performance, risks, etc. The monitoring data can be used to further enhance the application performance.
Guardrails for Protecting Against LLM Risks
Throughout these four pipelines, organizations should implement guardrails that ensure fair and unbiased outputs, intellectual property protection, safeguarding user privacy, alignment with legal and regulatory standards and more. For example, this could include removing PII automatically or setting up mechanisms to prevent the model from generating harmful or biased responses.
Swappable Modular Components Throughout the 4 Pipelines
By separating these pipelines and creating a modular architecture, teams can easily swap in and out components based on their needs. Here are a few examples of what components can be swapped:
In the data pipeline, teams can swap:
- Data sources
- Transformation strategies, like tokenization or normalization, as well as more sophisticated processes like PII detection and removal
- Knowledge retrieval methods
- Data storage targets - A traditional file system, a database, a vector store, etc.
In the training pipeline, teams can swap:
- The model itself, whether a version or a type. For example, based on user input or requirements, teams might switch from a full LLM to a smaller, more specialized model.
- The execution environment. Not relying on one cloud vendor and using containers can help achieve this. Containers are portable and can run anywhere, from local machines to various cloud environments.
- Fine-tuning techniques. QLORA, for example, allows for fine tuning a small number of parameters using a very small amount of compute. In the future, there may be more new developments and techniques.
In the application pipeline, teams can swap:
- Logging inputs + responses to various data sources (database, stream, file, etc.)
- Additional data sources (RAG, web search, etc.) that enrich incoming requests
- Business logic
- Request routing (customer support queries, marketing queries, etc.)
- Classical ML models and LLMs
- If using QLORA to fine-tune, teams can swap out domain specific fine tuned adapters while using the same base model (e.g. customer support fine-tuned adapter vs. marketing fine-tuned adapter. Both are just a small set of fine-tuned parameters that can be swapped out as needed while both using the same base LLM such as Llama or Mistral).
- Prompts
- How responses are formatted and delivered. For example, whether to log additional data for analysis or modify the response based on user preferences, this should be manageable without major overhauls.
The application pipeline is the most important pipeline to maintain modularity. This is because it drives the application with business logic, model inference, additional data, etc.
In the LiveOps pipeline, teams can swap tools for:
General monitoring
- Log aggregation, like Loki or ELK
- Monitoring infrastructure: CPU, memory, GPU, latency, etc. The most common tools in use are Prometheus and Grafana
- Alerting, based on logs, infra, or ML monitoring outputs
ML specific monitoring
- Experiment tracking: Parameters, models, results, etc.
- Data quality / drift detection: Calculating data drift on new batch or real-time data compared to historical data
- Model performance / drift detection: Calculating model performance on new data compared to historical data
LLM specific monitoring
- Checking response quality and user feedback
- Hallucination detection and adherence to facts / provided context
- Bias and fairness
Guardrails swapping:
- User input validation to prevent irrelevant queries, prompt injection, etc.
- Model output validation to prevent hallucination, bias, etc.
- Regulatory requirements. These are probably industry-specific.
Swapping at the Code and Infra Level
Swapping can happen on the code level or infra level. This might look like implementing multiple training or data-enrichment components that can be swapped out as needed depending on the pipeline. On the infra level, this might be leveraging something like containers so that the application is environment agnostic and can run in various clouds or on-prem.
It might also mean that different pieces of the application are connected in a de-coupled way, such as making HTTP requests or via some event stream like Kafka. These are both industry standard ways to connect pieces of an application in a way that makes it easy to swap pieces out.
Gaining Visibility into the “Black Box”
In addition to the technological advantages, there is another distinct advantage of a swappable architecture. This is the visibility it provides for developers and the organizations.
As models become more complex and capable, they often turn into what are colloquially known as "black boxes”. Their internal workings are opaque and difficult for even experienced developers to understand. This lack of transparency can be a significant barrier for development, debugging and ensuring ethical and responsible AI usage.
Since modular systems break up a behemoth AI architecture into smaller pieces, developers have a clearer understanding and greater control over the system. This leads to AI applications that are not only powerful and efficient but also ethical and responsible. They will be trusted and valued by users, fostering wider adoption and more sustainable development in the long run.
Eating Our Own Dogfood
At Iguazio (acquired by McKinsey) we regularly create demos to show what a gen AI architecture looks like in action. Recently, we developed a call center demo that included multiple, swappable steps.
Each of the components in these steps can be easily swapped. In fact, when we developed the demo they were swapped to achieve different outcomes. Any changes we made didn’t affect the rest of the pipeline and easily made a positive impact without any overhead.
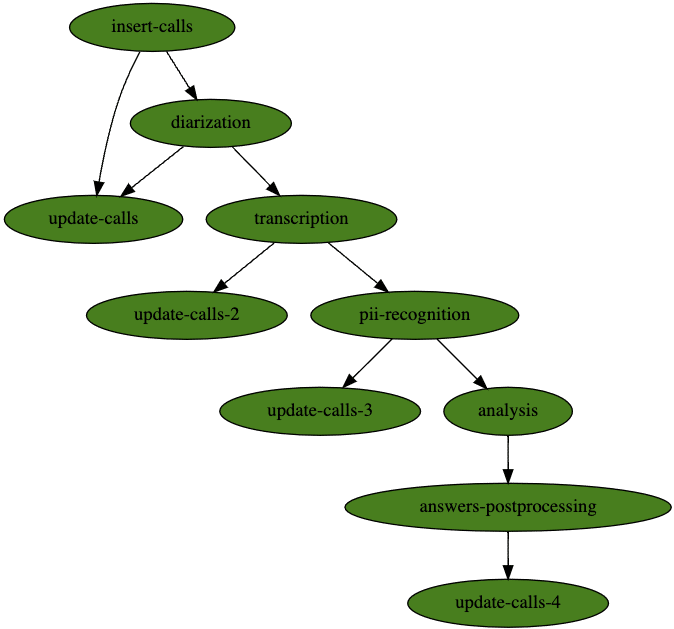
For example, in the call analysis pipeline, there is a "diarization" step that went through a few iterations. For context, diarization puts speaker labels on segments of time (e.g. speaker 1 spoke from 0:01 to 0:03, speaker 2 spoke from 0:03 to 0:04, etc.)
1. The first iteration had no diarization at all.
2. The second was adding it using a library called pyannote that works well but is quite heavy and requires a GPU.
3. The third iteration was adding parallelization of this pyannote component across multiple GPUs to increase efficiency and reduce time.
4. The fourth iteration was changing approaches completely and leveraging the format of the audio data itself to more efficiently perform diarization. We switched from pyannote to silvero-vad, which is a very simple voice activity detector model. This allows it to be run on a CPU and easily parallelized across multiple CPU cores.
It is important to note that this approach only works because of the specific format of the data. The call center data is stored in a way such that each speaker is on a separate channel (speaker 1 on the left, speaker 2 on the right). This means you can use a very simple voice activity detector model to determine when each person is speaking. At the end of the day, this is all diarization is.
For more info, check out this MLOps Community webinar.
Conclusion
As new technologies emerge, they bring with them new capabilities. Keeping track of these advancements and understanding which can enhance your application will ensure your organization maintains a competitive advantage. A modular architecture can help teams swiftly integrate new updates and features into existing applications. This agility ensures that applications can evolve at the same pace as the AI models and technologies they depend on, without requiring your constant manual oversight or intervention. With the future unknown and developing fast, being open to anything that comes along is the sure way to remain future-proof.
Learn more about how to build a resilient and scalable gen AI factory here.


