Implementing Gen AI in Practice
Yaron Haviv | January 22, 2024
Across the industry, organizations are attempting to find ways to implement generative AI in their business and operations. But doing so requires significant engineering, quality data and overcoming risks. In this blog post, we show all the elements and practices you need to to take to productize LLMs and generative AI. You can watch the full talk this blog post is based on, which took place at ODSC West 2023, here.
Definitions: Foundation Models, Gen AI, and LLMs
Before diving into the practice of productizing LLMs, let’s review the basic definitions of GenAI elements:
- Foundation Models (FMs) - Large deep learning models that are pre-trained with attention mechanisms on massive datasets. These models are adaptable to a wide variety of downstream tasks, including content generation.
- GenAI / Generative AI - The methods used to generate content with algorithms. Typically, foundation models are used.
- Large Language Models (LLMs) - A type of foundation model that can perform a variety of NLP tasks. These include generating and classifying text, answering questions in a conversational manner and translating text from one language to another
The Landscape: The Race to Open and Commercial LLMs
As mentioned, gen AI is garnering industry-wide interest. This has encouraged rapid evolution and intense competition between organizations. New and innovative solutions are constantly emerging, making it hard to pinpoint a single "winning" solution.
One notable trend in this space is the rise of specialized or application-specific LLMs. Unlike generalized models, these models are becoming more vertical-oriented, catering to specific needs and sectors. Another trend is enhanced traction being gained by open models, since they effectively address intellectual property (IP) challenges, and are continuously improving.
For businesses and developers, this means they need to maintain a flexible approach in design strategies. For example, decoupling the LLM from the core architecture of systems. Such a strategy ensures adaptability, allowing for the seamless integration of different LLMs as they evolve and as your requirements change. By staying agile and open to various options, you can effectively leverage the advancements in GenAI and any market changes to your advantage.
Three LLM Customization Methods
There are three main ways to customize LLMs and ensure they provide you with business value.
1. Prompt Engineering
Feeding the model with engineered requests (prompts), including specific content, details, clarifying instructions and examples that guide the model into the expected and most accurate answer.
Tradeoff:
- Lower inference performance
- Limited prompt data size
- High API calls costs (due to the large prompts)
Prompting is a good solution if you have lots of requests, like when starting to build your own model
2. Fine Tuning and Transfer Learning
Using an existing pre-trained model and further training it with an application-specific dataset. For example, on the custom brand voice. This significantly reduces the time and cost of computation due the training dataset size, helps achieve better accuracy, enables fixing issues, and reduces hallucinations and risks elements.
Tradeoff:
- Training costs and complexity
- Extra validation and testing
- Serving costs (not per call)
- Continuous deployment
3. RLHF (Reinforcement Learning from Human Feedback)
Re-training a model based on feedback received from human evaluators in order to increase accuracy and “fix” mistakes.
Tradeoff:
- Pipeline complexity
- Efficient human labeling
- Labeling costs
Protecting Against LLM Risks Is Top Priority
When productizing GenAI applications, significant engineering efforts should be allocated to test and protect against various LLM risks. Such risks include:
- Fairness/bias - Ensuring outputs are unbiased and fair, avoiding perpetuation of stereotypes or discriminatory practices.
- Intellectual property and privacy - Protecting the intellectual property rights and the data in the LLMs while safeguarding user privacy.
- Toxicity - Filtering out and preventing the generation of harmful or offensive content.
- Regulatory non-compliance - Aligning LLM functionalities with various legal and regulatory standards to avoid compliance issues.
- Misuse - Preventing the exploitation of LLMs for unethical or malicious purposes.
- Hallucination - Minimizing the risk of LLMs generating factually incorrect or misleading information.
In the examples below you can see examples of LLM risks:
1. A hallucination when the GenAI application incorrectly explains what RLHF is:
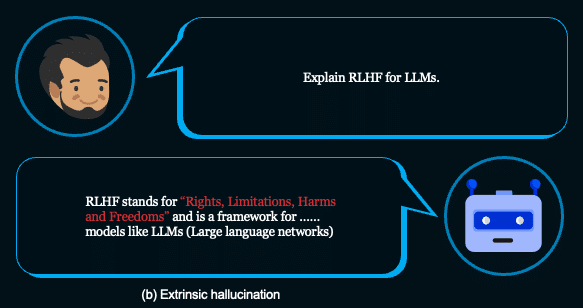
2. Misuse of ChatGPT that was fixed in the launched version of the GPT-4 model:

Mitigating these risks starts with the training data. If you train the model on private data there's a good chance you'll get private data in the response. If you train a model on blogs that have toxic language or bias language towards different genders you get the same results. The result will be the inability to trust the model’s results.

Productizing GenAI Requires Significant Engineering
Many data professionals tend to focus on building prototypes and MVPs. But the challenges start after developing the LLM and when attempting to productize the solution. These include the aforementioned risks, as well as scale, performance, costs, and more.
In addition, MLOps practices like building data, experting tracking, versioning, artifacts and others, also need to be part of the gen AI productization process. For example, when indexing a new version of a document, it’s important to take care of versioning in the ML pipeline. Otherwise, the system will be working with two versions, which could result in conflicting information that impacts accuracy, and also wastes tokens.
Four Steps for Moving from Gen AI Prototyping to a Production GenAI Application:
1. Prototype - Use data samples, scratch code and interactive development to prove the use case.
2. Production App - Build resilient and modular production pipelines with automation, scale, testing, observability, versioning, security, risk handling, etc.
3. Monitoring - Monitor all resources, data, model and application metrics to ensure performance. Then identify risks, control costs, and measure business KPIs.
4. Feedback - Collect production data, metadata, and metrics to tune the model and application further, and to enable governance and explainability.
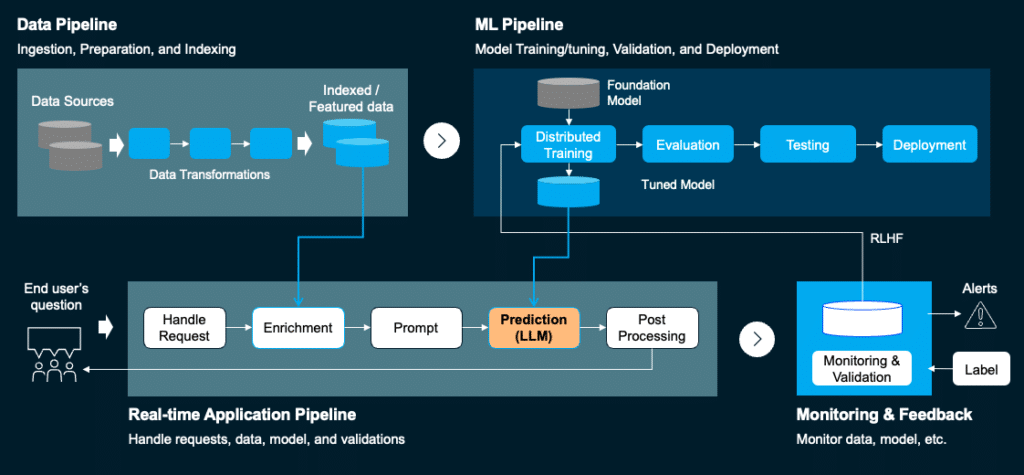
To Productize a GenAI Application, Four Architectural Elements are Needed:
1. The data pipeline - Takes the data from different sources (document, databases, online, data warehouses, etc.), performs transformations, cleans, arranges, versions, tags, labels, indexes, etc.
2. The ML pipeline - Trains/tunes, validates and deploys, while mitigating risks and validating prompts. For example, in this stage you might develop 1,000 different questions with random patterns and examine the results.
3. The application pipeline - Handles requests, data and model validations, including user context and authentication.
4. The multi-stage pipeline - Monitors, performs rolling upgrades, ensures the model behaves correctly and meets target goals, etc. This element also enables a feedback loop like RLHF or with automated feedback.
Efficient Data Processing Addresses Risks and Improves Quality
Let’s deep dive into the first element - data pipelines. The importance of data pipelines lies in the fact that data pipelines improve quality. They can ensure:
- Quality filtering - Filtering language, metrics, statistics, keywords, and more. This helps cleanse the data. For example, remove symbols or URLs or other pieces that don’t contribute to data.
- De-duplication - Removing sections that repeat themselves, at the sentence, document or set-level. This also makes indexing more efficient.
- Privacy reduction - Detecting and removing PII, like emails, phone numbers, SSNs, etc.
- Tokenization - Analyzing and labeling the content. For example, indexing in a vector database, indexing keywords, label the year of the document to be used as a filter, and more. Tokenization can be performed once we know the data structure, like where the PDF headers are.
Open Source MLRun: Collaboration, Automation Observability and Openness
MLRun is an open-source, scalable MLOps framework, designed to help data scientists and ML engineers manage and automate ML lifecycle, including development, deployment, monitoring and governance of ML applications. MLRun can help manage the end-to-end ML lifecycle, by providing tools for everything from running experiments and managing data to deploying models in production. This also includes automating the conversion from more interactive data science code or Python into fully operational pipelines and instrumentation, scaling and other aspects.
When it comes to gen AI productization, MLRun scales and accelerates the process by providing the following:
- A real-time multi-stage inference pipeline
- A scalable data, training and validation pipeline
- Automated monitoring and tracking
- Automating the flow of data prep, tuning, validating, CI/CD, and optimizing the LLM to specific data efficiently over elastic resources (CPUs, GPUs, ..)
- Rapid deployment of scalable real-time serving and application pipelines, which host the LLM as well as the required data integration and business logic.
- Built-in monitoring for the LLM data, training, model, and resources, with automated model re-tuning.
- Support for various LLMs and flexible deployment options (any cloud, on-prem).
Try MLRun for yourself: https://github.com/mlrun/mlrun

