Orchestrating ML Pipelines at Scale with Kubeflow
Yaron Haviv | March 10, 2022
Still waiting for ML training to be over? Tired of running experiments manually? Not sure how to reproduce results? Wasting too much of your time on devops and data wrangling?
Spending lots of time tinkering around with data science is okay if you’re a hobbyist, but data science models are meant to be incorporated into real business applications. Businesses won’t invest in data science if they don’t see a positive ROI. This calls for the adoption of an “engineered” approach — otherwise it is no more than a glorified science project with data.
Engineers use microservices and automated CI/CD (continuous integration and deployment) in modern agile development. You write code, push and it gets tested automatically on some cluster at scale. It then goes into some type of beta/Canary testing phase if it passes the test, and onto production from there. Kubernetes, a cloud-native cluster orchestrator, is the tool now widely used by developers and devops to build an agile application delivery environment.
Leading ML engineers and AI/ML-driven companies are already using Kubernetes, which comes with pre-integrated tools and scalable frameworks for data processing, machine learning and model deployment. Some Kubernetes data pipeline frameworks also enable horizontal scaling and efficient use of GPUs, which further cut down overall wait times and costs.
Don’t settle for proprietary SaaS/cloud solutions or legacy architectures like Hadoop. Get a Kubernetes-based solution for a scalable and forward-looking data science platform. The following post reviews best practices for the process and Kubernetes frameworks used to scale and operationalize data science endeavors and provides detailed information about the Kubeflow ML toolkit for Kubernetes (K8s), including the very popular Kubeflow Pipelines.
The Data Science Pipeline
Data scientists generally go through the following steps during a development phase:
- Data collection from CSV or dense formats (e.g. Parquet) which entail manual extraction from external sources.
- Manual data labeling, exploration and enrichment to identify potential patterns and features.
- Model training and validation.
- Model testing with real/fresh data, or as part of a bigger application.
- Rinse and repeat when unhappy with the outcome.
Once done with development, against all odds, models are deployed into a production environment where fancy dashboards are on display to identify anomalies or predict behavior. Those of us who are more advanced in our AI journey also create AI-driven user interactions/apps or trigger alerts and actions.
But then data changes… model accuracy drifts… the users ask for update in apps and dashboard, etc… Now we find ourselves running much of the pipeline again to produce new models. This is where we start Googling a continuous development and integration approach, but more on that later.
Software developers enjoy a wide and mature variety of platforms for implementing a CI/CD approach to application development, but data scientists are still limited in this area. An effective CI/CD system is vital to the data science pipeline, and the requirements are specific to ML elements.
While there are several services that effectively incorporate CI/CD into ML pipelines, they place data scientists into a siloed position in which they must build, train, track, and deploy in a closed technology stack, separate from engineers.
Rather than asking ML teams to embark on a steep learning curve, they should be able to use their preferred frameworks, platforms, and languages to experiment, build and train their models, and quickly deploy to production, while also collaborating in one place.
The tools required to build our pipeline can be divided into the following six categories:
A. Automated data collectors from offline or online sources.
B. Interactive tools for data labeling, exploration and model development.
C. Analytics tools/databases to aggregate, join and pivot data at scale.
D. Parallel model training frameworks.
E. Model and API serving frameworks.
F. Management, monitoring and dashboards.
The only sane way to integrate all these tools under one platform is with Kubernetes!
Kubernetes, The ML Platform of Choice
Kubernetes hosts several packaged and pre-integrated data and data science frameworks on the same cluster. These are usually scalable or they auto-scale, and they’re defined/managed with a declarative approach: specify what your requirements are and the service will continuously seek to satisfy them, which provides resiliency and minimizes manual intervention.
Kubeflow is an open source project that groups leading relevant K8 frameworks. Kubeflow components include Jupyter notebooks, Kubeflow Pipelines (workflow and experiment management), scalable training services (for Tensorflow, PyTourch, Horovod, MXNet, Chainer), model serving solutions, and Iguazio’s open source serverless framework Nuclio. Kubeflow also offers examples and pre-integrated/tested components.
In addition to typical data science tools, Kubernetes can host data analytics tools such as Spark or Presto, various databases and monitoring/logging solutions such as Prometheus, Grafana, Elastic Search, etc. It also enables the use of serverless functions (i.e. auto built/deployed/scaled code like AWS Lambda) for a variety of data-related tasks or APIs/model serving, read more on that in my post (Serverless: Can It Simplify Data Science Projects?).
The key advantage of Kubernetes vs proprietary cloud or SaaS solutions is that its tools are regularly added and upgraded, Google’s search and Stack overflow are often the fastest path to help and the solution can be deployed everywhere (any cloud or even on-prem or on a laptop). A community project also forces associated components/services to conform to a set of standards/abstractions which simplify interoperability, security, monitoring, etc.
You can build and manage a Kubernetes MLOps platform yourself (follow the doc), or use managed and pre-integrated solutions from cloud providers or companies like Iguazio.
Building an Efficient Data Science Pipeline with Kubeflow
Unfortunately, just betting on a credible platform is not enough. I speak from experience when I tell you that life gets much easier once you adopt three guiding rules:
- Make it functional — create reusable abstract functions/steps which can accept parameters.
- Make it scalable — apply parallelism to every step (or as often as possible, within reason).
- Automate — avoid manual and repetitive tasks by using declarative semantics and workflows.
The current trend in data science is to build “ML factories,” where, much like in agile software development, ML teams build automated pipelines that take data, pre-process it, run training, generate, deploy and monitor the models. The declarative and automated deployment and scaling approach offered by Kubernetes is a great baseline, but it’s missing a way to manage such pipelines on top of that.
Pipelines, part of the Kubeflow project, is a set of services and UI aimed at creating and managing ML pipelines. We can write our own code or build from a large set of pre-defined components and algorithms contributed by companies like Google, Amazon, Microsoft, IBM, NVIDIA, Iguazio, etc.
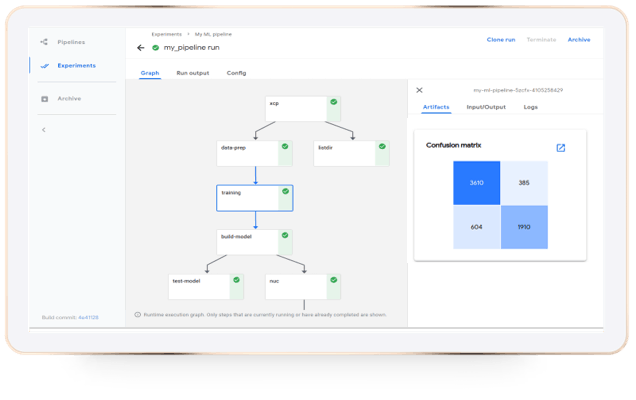
Once we have a workflow, we have a lot of flexibility: we can run it once, at scheduled intervals, or trigger it automatically. The pipelines, experiments and runs are managed, and their results are stored and versioned. Pipelines solve the major problem of reproducing and explaining our ML models. It also means we can visually compare between runs and store versioned input and output artifacts in various object/file repositories.
A major challenge is always running experiments and data processing at scale. Pipelines orchestrate various horizontal-scaling and GPU-accelerated data and ML frameworks. A single logical pipeline step may run on a dozen parallel instances of TensorFlow, Spark, or Nuclio functions. Pipelines also have components which map to existing cloud services, so that we can submit a logical task which may run on a managed Google AI and data service, or on Amazon’s SageMaker or EMR.
Kubeflow and its Pipelines, like most tools in this category, are still evolving, but it has a large and vibrant multi-vendor community behind it, including tools that provide Kubeflow orchestration. The highly-engaged Kubeflow community ensures a viable and open framework. Much like the first days of Kubernetes, cloud providers and software vendors had their proprietary solutions for managing containers, and over time they’ve all given way to the open source standard demanded by the community.


