A Data Flywheel in the context of AI is a self-reinforcing loop where data, AI models and product usage continuously feed and improve each other. This helps AI services, applications and agents gain momentum over time, just like a real flywheel, improving quality and business value while cutting costs.
For example, a data flywheel for a generative AI customer support chatbot can learn new ways users phrase questions, resulting in improved routing and resolution accuracy and reduced ticket escalations. This would make it more widely adopted across teams, generating even more data for continued improvement.

The data flywheel effect creates a compounding advantage for AI applications. As more data comes in, the LLM improves, thus improving the AI application. This results in higher business value, with more attracted and retained users. Consequently, more users result in more data, further spinning the flywheel.
Strategic Data Asset Creation – With the system constantly turning usage into valuable, proprietary training data. Organizations strengthen long-term IP, supporting future AI initiatives across the organization.

A data flywheel is made up of multiple components, used to run the service or agent, gather feedback, feed it back and orchestrate the process. Here’s how it works:
Step 1: Data Generation – Business, inference and monitoring data are ingested by the app. For example, when AI application users interact with a product (e.g. an app, recommendation engine, chatbot). These interactions create valuable data, like clicks, preferences, behaviors, errors, etc., used as the flywheel database.
Step 2: Model Training & Improvement – The data is fed back into AI/ML models. The models are retrained or fine-tuned, improving predictions, personalization, or automation. An orchestrator like MLRun can run this entire process, capturing logs, orchestrating feedback and monitoring deployed models.
Step 3: Better Performance – Improved AI models provide more accurate, helpful, or engaging experiences. This could result in better recommendations, smarter chatbots, faster automation, lower use of compute resources, etc., i.e high business value. Then, users respond positively to the app’s better performance. This means even more usage, more trust and more interactions.
Step 4: More Data – The resulting higher engagement leads to even more data, and ideally higher-quality data, which restarts the loop.
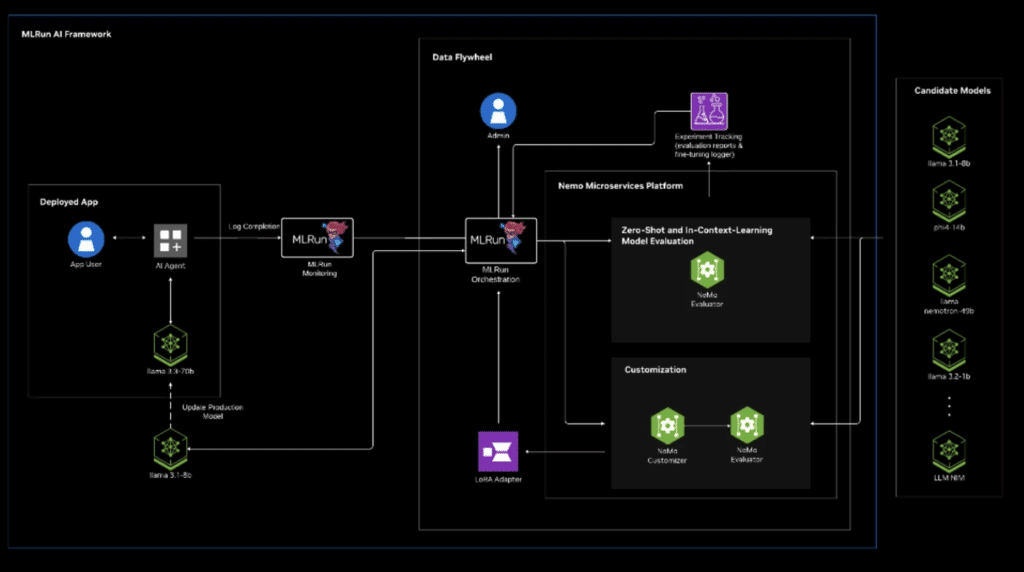
Here’s an example of a data flywheel powered by MLRun and NVIDIA that trains small models based on large model performance:
Data AI flywheels boost operational efficiency through automation and reusable infrastructure, lowering costs and complexity. As performance improves, user experience and trust increase, attracting more users and unlocking new use cases. These network effects accelerate growth, helping AI systems scale.
In addition, this process can be easily replicated for multiple models, workflows and services, addressing real enterprise needs.
What is needed to keep the flywheel spinning?
Here’s how to build and implement a data flywheel in your organization:
MLRun integrates with NVIDIA’s NeMo microservices and creates a powerful, production-grade infrastructure for managing observable data flywheels. MLRun handles orchestration of data logging, performance monitoring, and pipeline execution, while NeMo provides modular services like LoRA-based fine-tuning, prompt-tuning, SFT, RAG evaluation and LLM-as-a-Judge assessment. Logs captured during inference are stored (e.g., in Elasticsearch), triggering MLRun workflows that invoke NeMo components for retraining or evaluation. This tightly coupled system enables domain-specific model optimization with minimal manual coding, scalable benchmarking and fast redeployment. Read more here.

