Will Kubernetes Sink the Hadoop Ship?
Yaron Haviv | November 26, 2018
The popularity of Kubernetes is exploding. IBM is acquiring RedHat for its commercial Kubernetes version (OpenShift) and VMware just announced that it is purchasing Heptio, a company founded by Kubernetes originators. This is a clear indication that companies are increasingly betting on Kubernetes as their multi-cloud clustering and orchestration technology.
At the same time, in far, far away IT departments, developers are struggling with a 10+-year-old clustering technology built specifically for big data called Hadoop. Surprisingly enough, some of them still think it makes sense to manage big data as a technology silo, while early adopters are realizing that they can run their big data stack (Spark, Presto, Kafka, etc.) on Kubernetes in a much simpler manner. Furthermore, they can run all of the cool post-Hadoop AI and data science tools like Jupyter, TensorFlow, PyTorch or custom Docker containers on the same cluster.
This trend is taking its toll, as Hadoop’s two leading rivals, Cloudera and Hortonworks have recently decided to merge. The slow market growth just couldn’t justify the existence of two companies any longer.
The History of Hadoop and the Kubernetes Transformation
Hadoop was formed a decade ago, out of the need to make sense of piles of unstructured weblogs in an age of expensive and non-scalable databases, data warehouses and storage systems.
Hadoop’s value proposition was letting developers write all of their data to hundreds or even thousands of servers, fitted with many cheap disks orchestrated using a minimalistic distributed file system (HDFS), and clusters had long-running MapReduce jobs to aggregate and extract meanings and patterns out of data.
Since then Hadoop has evolved and tried to take on new challenges, adding orchestration (YARN) and endless Apache projects. Some disappeared as fast as they came like “Storm” The MapReduce stack of tools (Pig and Hive) and their main alternative is Spark which can run on Hadoop YARN or other clusters (such as Kubernetes).
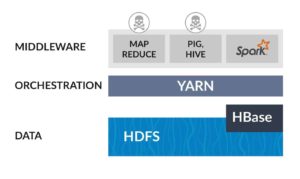
Users deploying Hadoop in the cloud usually find it much simpler and cheaper to run it over cloud storage layers such as Amazon S3 or managed databases such as Amazon RedShift and Google BigQuery. When doing so, why choose an old and labor-intensive clustering technology like YARN, when they can switch to the newer and simpler Kubernetes?
YARN limits users to Hadoop and Java focused tools while recent years have shown an uptake in post Hadoop data science frameworks including microservices and Python-based tools. So what if a user doesn’t want to give up on Hadoop but still enjoy modern AI microservices?
The answer is just using Kubernetes as your orchestration layer. It will host different services including big data tools (Apache Spark or Presto), data-science and AI tools (Jupyter, TensorFlow, PyTorch, etc.) and any other application or data microservice. For data, it’s probably best to keep using managed cloud storage systems and databases, which are cheaper and simpler to maintain than the Hadoop file system.
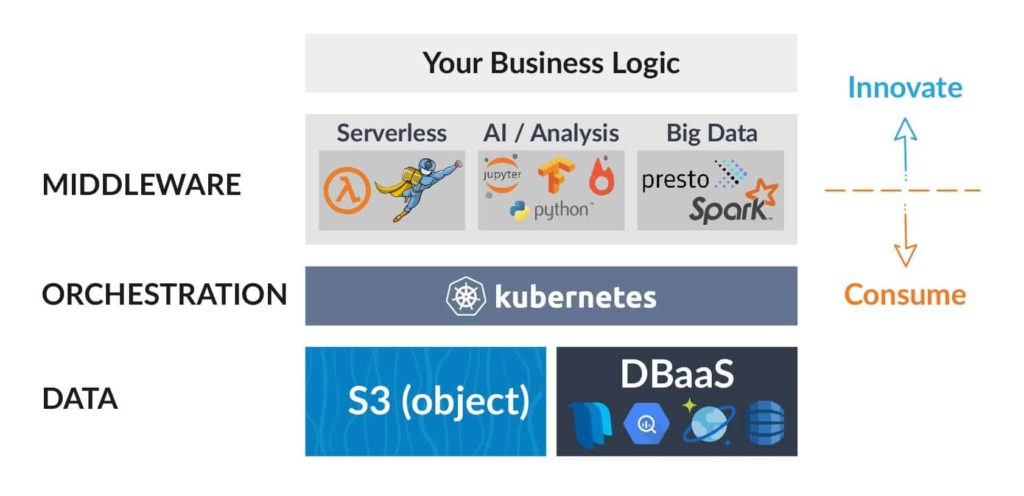
Serverless, Another Nail in Hadoop's Coffin
Code development, testing, scaling and operationalization are the biggest barriers to competing efficiently in a digital world. Companies must adopt cloud and AI technologies and cannot afford to spend time on managing infrastructure and servers. This premise led to the evolution of serverless technologies in which a developer submits code and requirements and the serverless platform automates the deployment, scaling and management of the application.
Up until now, serverless was limited to proprietary cloud technologies like AWS Lambda or Azure Functions. However, new open-source and multi-cloud serverless technologies such as OpenWhisk, Nuclio, and Fn designed to run over Kubernetes, are outperforming and out-featuring cloud provider serverless options. Frameworks like Nuclio have added specific features for big data, stream processing and AI workloads.
What if I Need to Run On-Prem or at the Edge?
One of Kubernetes’ greatest advantages is its portability, enabling users to build clusters which span multiple clouds or are distributed across locations. Portability also facilitates the development or testing of microservices in the cloud and deployment in one or many edge locations automatically.
Companies like Iguazio are providing self-service platforms which can be deployed in the cloud or on-premises and include cloud-like data services, serverless functions and popular big data and AI microservices. Using a Kubernetes based managed platform enables developers to focus on building applications instead of tedious integrations, infrastructure troubleshooting and closing security holes.
(This post by Yaron Haviv was originally published in The New Stack).


