Continuous validation in machine learning is the set of tools and processes, set up within both the CI/CD pipeline and monitoring system, that ensure model performance at deployment time.
While model validation is typically used to refer to the testing of offline model performance, the term “continuous” implies a focus on deployment.
Continuous is a key term used in MLOps—originating from DevOps—to highlight the importance of keeping production systems up to date and healthy with zero downtime in an automated way—and doing so as often and as early as possible.
Within this mindset, continuous validation entails continuous performance validation, continuous testing, and continuous monitoring.
We’ll dive into details about each of these processes below by providing a comprehensive definition of continuous validation, a review of its importance, and a walk-through of the most common tools used in the field.
Continuous validation aims to ensure the online performance of a model.
This model validation is performed by extensive testing, which happens in two distinct phases: at deployment and after deployment.
Deploying a model involves a variety of steps and components that go beyond the single model endpoint, such as feature retrieval or data validation. This is why it is more common and appropriate to talk about continuous validation of model pipelines, rather than of models.
We will look at each continuous validation phase separately.
At deployment, continuous validation entails continuous testing during CI/CD.
CI/CD for machine learning is itself a continuous process, as it stands for continuous integration and continuous deployment. This process starts typically with a new code release, but it can also be triggered in response to a system action such as the arrival of new data or an automated retraining. It involves a series of steps that leads to a reliable automatic release of a new model, one of the main steps being continuous testing.
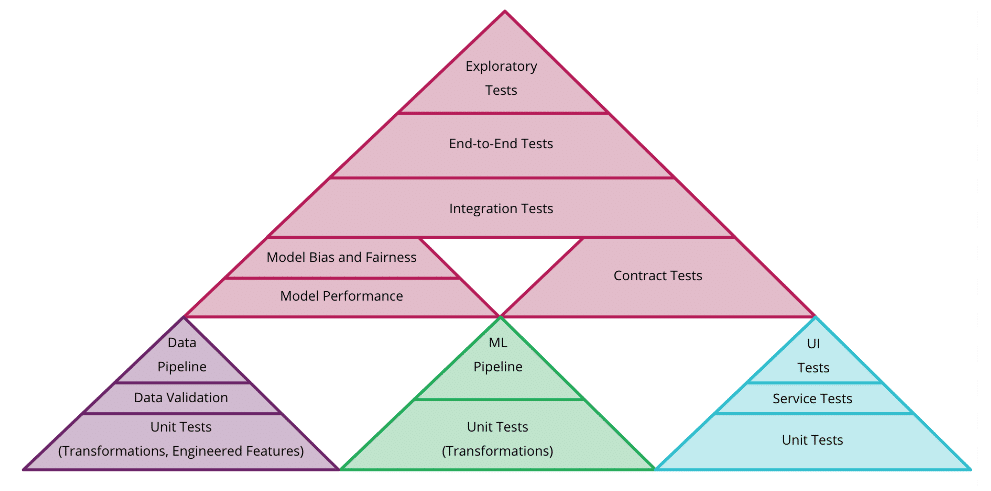
Figure 1: Continuous testing in machine learning (Source: martinfowler.com)
Continuous testing in MLOps aims to validate data, the model, and code. While the tests for code are well-defined by DevOps practices, the tests for the other ML-specific artifacts are solely under the remit of MLOps and deserve special focus.
When testing data and models, unit tests should be performed to ensure the input, logic, and output of each functionality behave as expected. For example, you may want to test that a normalization function outputs your input feature in the expected range.
Similarly, the correct behavior of the end-to-end data and model pipelines should be tested on average and edge-case data inputs. For the former, you want to test range, shape, and the most relevant statistical properties of the processed data. For the latter, you want to ensure the offline metrics meet the expected standards.
When testing data, additional data validation steps are performed to ensure the functioning of compound pre-processing phases such as data splitting.
Higher-level tests combining the three artifacts are then performed to validate the end-to-end pipeline.
In a reliable MLOps system, this continuous validation process should be fully automated together with the end-to-end CI/CD pipeline.

After deployment, continuous validation entails continuous monitoring and continuous performance validation of the model pipeline.
The aim is to test online performance over time of both the infrastructure and the model.
Infrastructure monitoring validates the system’s performance on various metrics including latency and throughput, hardware utilization with a special focus on RAM and the processor, and network traffic. This process ensures that the infrastructure can support the expected traffic; it also provides the possibility to smartly tweak hardware choices over time to optimize cost and performance on actual traffic.
Model monitoring validates the model’s performance, with a special interest in the early detection of bias and drift.
Both types of monitoring metrics are typically organized in dashboards, with automated alerts set up to promptly act on unexpected behaviors from out-of-range values to outages.
In a reliable MLOps system, this validation is semi-automated, as human intervention to periodically check dashboards and manually review alerts is desirable.
Continuous validation is fundamental to ensuring a reliable end-to-end ML production system, which lets you unlock the opportunity to embrace a truly agile, production-first approach to developing ML initiatives. This is something all practitioners agree teams should advocate and champion, as it has been proven to be the key differentiator of successful applied ML.
With comprehensive testing before and after deployment, machine learning engineers can thus seamlessly keep production model pipelines performant and not stress when on call (another critical factor not to be underestimated).
When reviewing tools for continuous validation, it is important to keep in mind that what is right for you depends on your specific infrastructure setup and requirements.
Still, some tools and functionalities have become prominent in the community, and we will focus on these here, separately for each of the two continuous validation phases.
At deployment, some relevant CI/CD tools are GitHub Actions, TeamCity, and Google Cloud Build. All these tools provide fundamental functionalities to look out for such as:
It is important to note that the community has not converged yet towards a standardized set of practices for continuous testing. We recommend creating a priority list of tests to incorporate over time following the MoSCoW approach.
For an example of how to build effective Git-based CI/CD for machine learning, refer to this webinar led by the Head of OSS ML Strategy at Microsoft, David Aronchick.
After deployment, some relevant monitoring tools are MLRun, Prometheus, ARize, and Amazon SageMaker Model Monitor. Key functionalities are:
All in all, when selecting MLOps tools, we always recommend considering ease of integration, adoption, and maintenance.
While multiple specialized solutions exist, end-to-end ML pipelines are composed of many steps that are often interconnected. Unless your needs are very unique and require specialized solutions, an all-around MLOps platform that can seamlessly cover your current and future MLOps needs, such as Iguazio, is often the best option.





