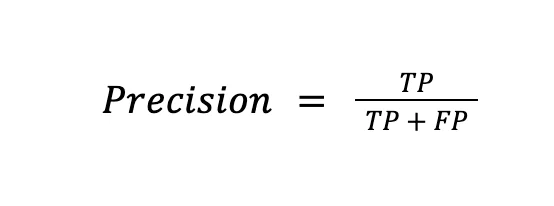No machine learning (ML) model is 100% accurate in performing its learned task. Multiple metrics exist to evaluate a model’s performance, each with its unique interpretation of the model’s error.
Choosing the right metric for a use case in machine learning is as fundamental as selecting the right algorithm. The correct metric will ensure the model properly solves the associated business problem, and a proper testing procedure further warrants that this offline evaluation is representative of the online performance we can expect for the deployed model.
When performing supervised classification tasks, three metrics are a must: accuracy, precision, and recall.
This article focuses on recall and provides an introduction to this machine learning metric, a discussion of when to use it, and a walk-through of how to improve it.
Recall, also known as the true positive rate (TPR), is the percentage of data samples that a machine learning model correctly identifies as belonging to a class of interest—the “positive class”—out of the total samples for that class.
As previously mentioned, recall is a metric used for classification in supervised learning, and we can look at binary classification to understand it better.
Let’s take the example of a binary classifier that labels images as cat or dog, where dog is the positive class. We want to evaluate the performance of the trained image classifier on a test set composed of 1,000 unseen images.
The predicted labels can be correctly identifying or misclassifying the true labels. We can summarize this information using a confusion matrix.
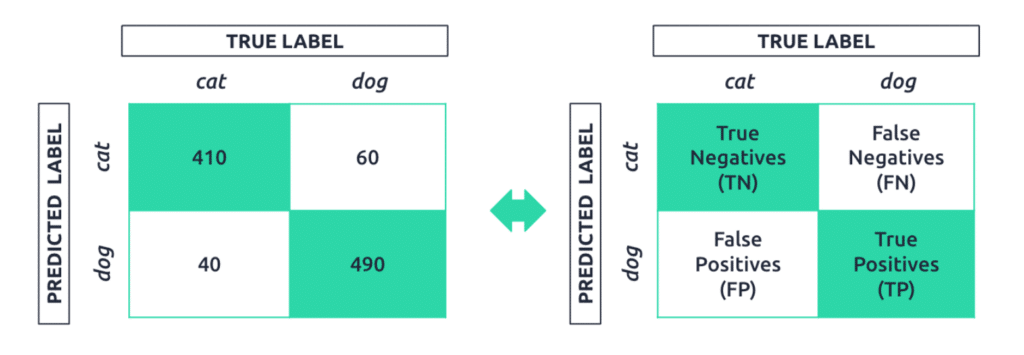
Figure 1: On the right are the values of the confusion matrix for the example binary image classifier;
on the left is an explanation of the cells in the confusion matrix.
The confusion matrix reports information around true negatives (TN), false negatives (FN), false positives (FP), and true positives (TP).
Machine learning recall is calculated on top of these values by dividing the true positives (TP) by everything that should have been predicted as positive (TP + FN). The recall formula in machine learning is:
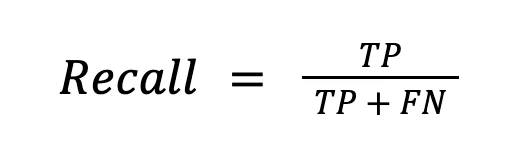
This provides an idea of the sensitivity of the model, or put in simpler terms, the probability that an actual positive will test positive.
In our example, we have defined the class dog to be the class we are most interested in predicting. Using the formula we’ve just derived, we can define recall as the number of images correctly identified as dog divided by the total number of images labeled as dog:
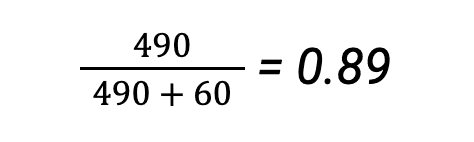
If we had defined cat as the positive class, then recall would have been:
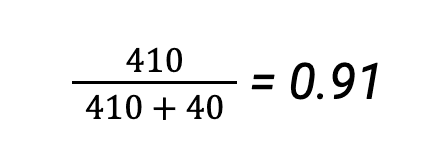
It’s possible to report an overall recall for the classifier as the average between each class weighted by their support for our reference example, i.e.:
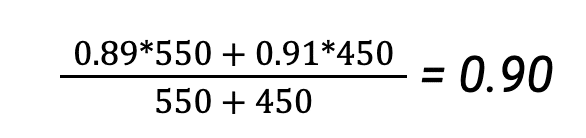
However, we would not recommend using recall in a use case where classes have the same relevance. We’ll see why next.

Recall in machine learning should be used when trying to answer the question “What percentage of positive classifications was identified correctly?”
It is the correct metric to choose when minimizing false negatives is mission-critical. This typically happens when the cost of acting on a false positive is low and/or the opportunity cost of passing up on a true positive is high. This often happens when the use cases are imbalanced.
Following this insight, the use of recall as an evaluation metric is:
A metric such as accuracy which gives the same importance to the positive and negative class would be misleading for these use cases—a classifier could achieve an almost-perfect 98% accuracy for a rare disease detector with a 2% disease rate, and no disease would actually be identified.
| ⓘ Precision is the percentage of data samples that a machine learning model correctly identifies for the positive class out of all samples predicted to belong to that class.
Precision answers the question “What percentage of positive classifications was indeed correct?” |
A 100% recall means that there are no false negatives, i.e., every negative prediction is correct. To improve recall, we thus need to minimize the number of false negatives.
When looking at methods on how to increase recall in machine learning, we can choose to focus on improving the data, the algorithm, the predictions, or a combination of those.
The data approach involves reviewing the feature set of misclassified data samples to search for specific characteristics that confuse the classifier. This may lead to more data cleaning, data preprocessing, feature engineering, or even new data collection.
When looking at improving the algorithmic approach, hyperparameter tuning is the best choice to increase recall where both model hyperparameters and training regime are tuned using recall as the metric to optimize. Other—more advanced—approaches are defining a loss function that penalizes false negatives or prototyping a different state-of-the-art model architecture.
Most commonly though, we’d look at improving the predictions by thresholding.
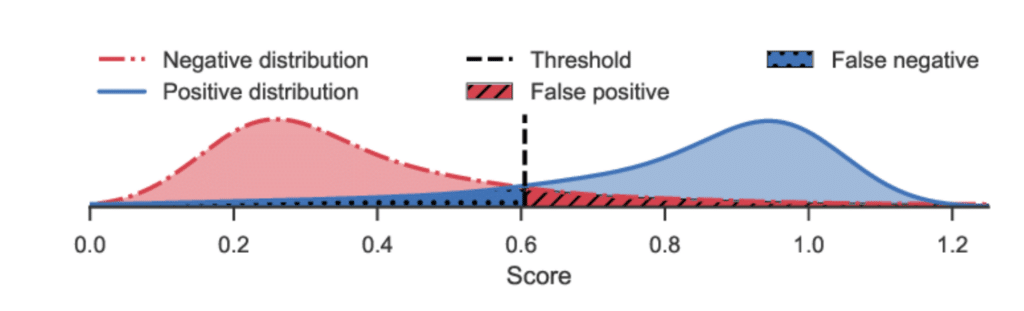
Figure 2: Example threshold and score distribution for a binary classification problem (Source: ResearchGate)
The output of a binary classifier is a real value between 0 and 1 that defines the probability of the data sample belonging to the positive class. Set by default to 0.5, the threshold tells us how to move from a probability to binary class. If changed to a higher value, we can optimize recall by reducing the number of predicted false negatives.
We can see from the plot above that recall and precision are reciprocal metrics: Improving one decreases the other, and vice versa. Selecting the right threshold for a classifier is a compromise between the two metrics.
Precision and recall each provide a unique insight into the model’s performance, which is why it is always recommended to look at both as well as other relevant metrics:
These metrics are particularly useful when comparing models.
While performing model experimentation, we recommend keeping track of all runs, metrics, and artifacts for reproducibility, collaboration, and efficiency.
MLRun is a great tool for experiment tracking with any framework, library, and use case and can be deployed as part of Iguazio’s MLOps platform for end-to-end data science.