Introducing the Platform
Welcome to the Iguazio AI Platform
An initial introduction to the Iguazio AI Platform and the platform tutorials:
- Platform Overview
- Data Science Workflow
- The Tutorial Notebooks
- Getting-Started Tutorial
- End-to-End Use-Case Application and How-To Demos
- Installing and Updating the MLRun Python Package
- Additional Platform Resources
- Miscellaneous
Platform Overview
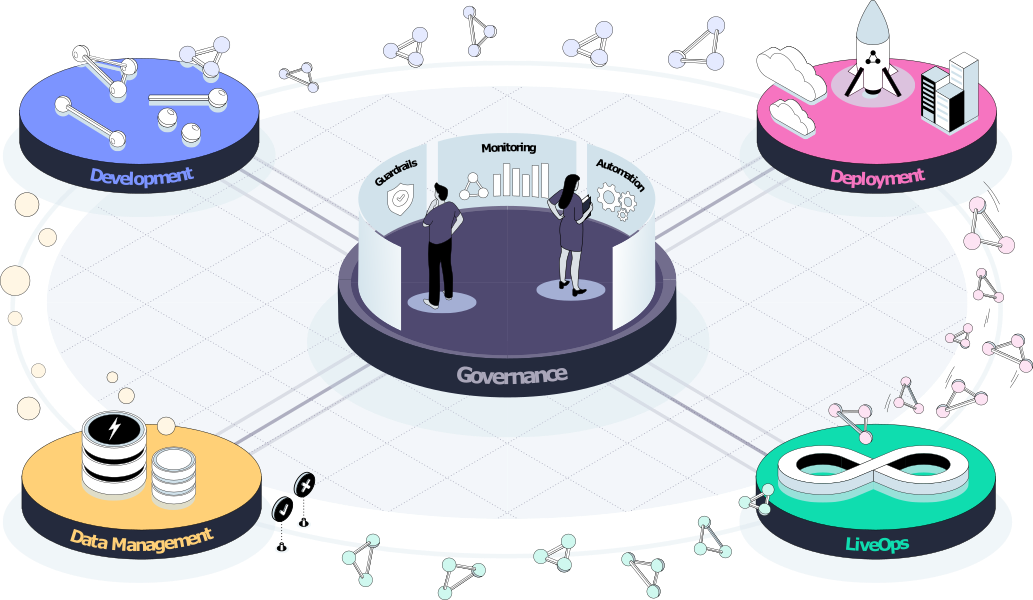
The Iguazio AI Platform ("the platform") is a fully integrated and secure data science platform that powers operational and responsible (gen) AI pipelines. It provides:
- Data Management: Ensure data quality through data ingestion, transformation, cleansing, versioning, tagging, labeling, indexing, and more.
- Development and CI/CD: Train and customize LLMs and AI models with high-quality model fine-tuning, RAG, RAFT, & more. Validate and deploy with CI/CD for AI/ML.
- Deployment/Inference: Bring business value to live applications through a real-time application pipeline that handles requests, data, model, and validations.
- Monitoring & LiveOps: Continuously monitor AI applications to improve performance, address regulation needs, remove PII, mitigate bias, and more.
The platform components/capabilities used to implement the workflow are:
- A data science workbench that includes integrated analytics engines, and Python packages. You can work with your favorite IDE (e.g. Pycharm, VScode, Jupyter, Colab, etc.). Read how to configure your client against the deployed MLRun server in Setting Up your Environment.
- The MLRun open-source orchestration framework for simplified management of your continuous ML and gen AI applications across their lifecycles.
- The Nuclio real-time serverless functions framework for model serving.
- Integration with third-party data sources such as Amazon S3, HDFS, SQL databases, and streaming or messaging protocols.
- Real-time dashboards based on Grafana.
Data Science Workflow
The platform provides a complete data science workflow in a single ready-to-use platform that includes all the required building blocks for creating data science applications from research to production:
- Collect, explore, and label data from various real-time or offline sources
- Run gen AI and ML training and validation, at scale, over multiple CPUs and GPUs
- Deploy models and applications into production with serverless functions
- Log, monitor, and visualize all your data and services
The Tutorial Notebooks
The home directory of the platform's running-user directory (/User/<running user>) contains pre-deployed tutorial Jupyter notebooks with code samples and documentation to assist you in your development — including a MLRun demos repository with end-to-end use-case applications (see the next sections).
Note:
- To view and run the tutorials from the platform, use your IDE that supports Jupyter notebook (for example, PyCharm and VSCode). (Alternatively, create a Jupyter Notebook service.)
- The welcome.ipynb notebook and main README.md file provide the same introduction in different formats.
Getting-Started Tutorial
Start by running the Quick start tutorial to familiarize yourself with the platform and experience firsthand some of its main capabilities.
Demos
Iguazio provides full end-to-end use-case application and how-to demos that demonstrate how to use the platform, its MLRun service, and related tools to address data science requirements for different industries and implementations.
| Demo | Description |
|---|---|
| Call center | This demo showcases how to use LLMs to turn audio files, from call center conversations between customers and agents, into valuable data — all in a single workflow orchestrated by MLRun. MLRun automates the entire workflow, auto-scales resources as needed, and automatically logs and parses values between the different workflow steps. |
| Banking LLM monitoring and feedback loop | This demo illustrates how to train, deploy, and monitor an LLM using an approach described as "LLM as a judge." |
| Banking agent demo | This demo showcases a modular, production-grade banking customer service chatbot. It combines traditional machine learning (churn propensity) and large language models (LLMs) in a single, observable inference pipeline. The system features conditional routing based on guardrails (banking topic and toxicity filtering), and dynamically adapts model behavior using conversation history, sentiment, and churn risk. |
Demos download to the $HOME directory, unless you specify the --path:
--path - demos folder download path e.g. --path=./demos.
Default: HOME/demos directory
By default, the script retrieves the files from the latest release that matches the version of the installed mlrun package (see Installing and Updating the MLRun Python Package).
Before running the script, close any open files in the demos directory.
(For Iguazio AI Platform Jupyter service users: You can view the tutorial notebooks and demos from within the service. When downloading the demos, the files are copied to the /v3io/users/<username>/demos
directory, where <username> is the name of the running user ($V3IO_USERNAME) unless you set the -u|--user flag to another username.)
For full usage instructions, run the script with the -h or --help flag:
!/User/demos/update_demos.sh --help
Installing and Updating the MLRun Python Package
The demo applications and many of the platform tutorials use MLRun — Iguazio's end-to-end open-source MLOps solution for managing and
automating your entire analytics and machine-learning life cycle, from data ingestion through model development to full pipeline deployment in production.
MLRun is available in the platform via a default (pre-deployed) shared platform service (mlrun).
However, to use MLRun from Python code (such as in the demo and tutorial notebooks), you also need to install the (mlrun).
The version of the installed package must match the version of the platform's MLRun service and must be updated whenever the service's version is updated.
It's recommended to use your own IDE (see Setting up your Environment). However, if you use the pre-installed Jupyter, you can use the platform-provided
/User data mount.
Use the following command to run this script for the initial package installation (after creating a new Jupyter Notebook service) and whenever the MLRun service is updated; (run the command for each Jupyter Notebook service):
!/User/align_mlrun.sh
Additional Resources
- MLRun documentation
- Platform Services
- Python SDK for management APIs: a Python SDK for controlling and performing operations on the the Iguazio system via REST-API
- Nuclio for creating and deploying Nuclio “serverless” applications
Miscellaneous
Creating Virtual Environments in Jupyter Notebook
A virtual environment is a named, isolated, working copy of Python that maintains its own files, directories, and paths so that you can work with specific versions of libraries or Python itself without affecting other Python projects. Virtual environments make it easy to cleanly separate projects and avoid problems with different dependencies and version requirements across components. See Creating Python Virtual Environments with Conda for step-by-step instructions for using conda to create your own Python virtual environments, which appear as custom kernels in Jupyter Notebook.
The V3IO Directory
The v3io directory that you see in the file browser of the Jupyter UI displays the contents of the v3io data mount for browsing the platform data containers.
For information about the platform's data containers and how to reference data in these containers, see Data Containers.
Support
The Iguazio support team will be happy to assist with any questions.