Working with Data Streams ("Streaming")
Overview
Streams are used for storing sequenced information that is rapidly and continuously produced and consumed. Stream data is stored as a continuous series of data records, which can include any type of data. The platform treats the data as a binary large object (blob).
For optimal performance and scalability, the platform allows dividing a stream into multiple shards, so that records are ingested and consumed sequentially per shard. See the detailed explanation in the Stream Sharding and Partitioning section in this document.
After a data container is created and configured, you can create one or more streams in the container. The following image shows a container with Web Clicks and Server Logs streams:
A producer adds records to a stream. For example, an IoT device that sends sensor data to the platform is a producer. A consumer retrieves and processes stream data sequentially.
Streams are identified by their user-assigned names, which must be unique within the parent container's relative stream path.
When creating a stream, you also set its retention period. All stream records are guaranteed to be available for consumption during the stream's retention period. After this period elapses, existing records might be deleted to make room for new records, starting from the earliest ingested records.
You can manage and access stream data in the platform by using the Spark or web APIs.
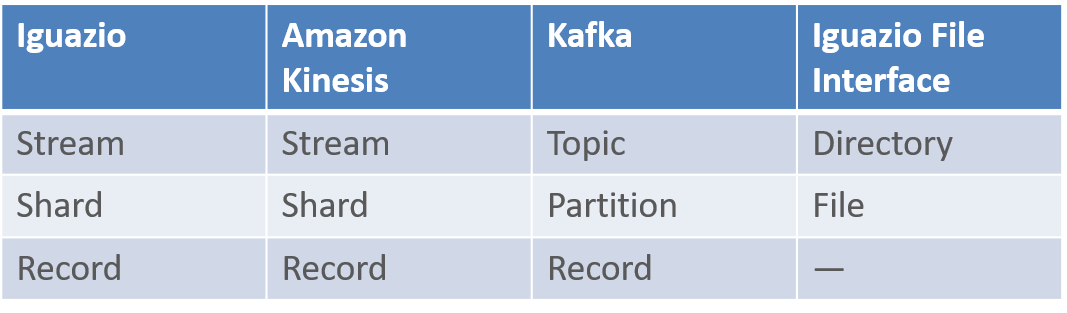
Terminology Comparison
The following table compares the Iguazio AI Platform's streaming terminology with that of similar third-party tools and the platform's file interface:
Stream Sharding and Partitioning
For optimal performance and to enable scalability of consumers, records are best distributed among shards, which are uniquely identified data sets within a stream.
When a record is added to a stream, it is assigned to a specific shard from which it can subsequently be retrieved.
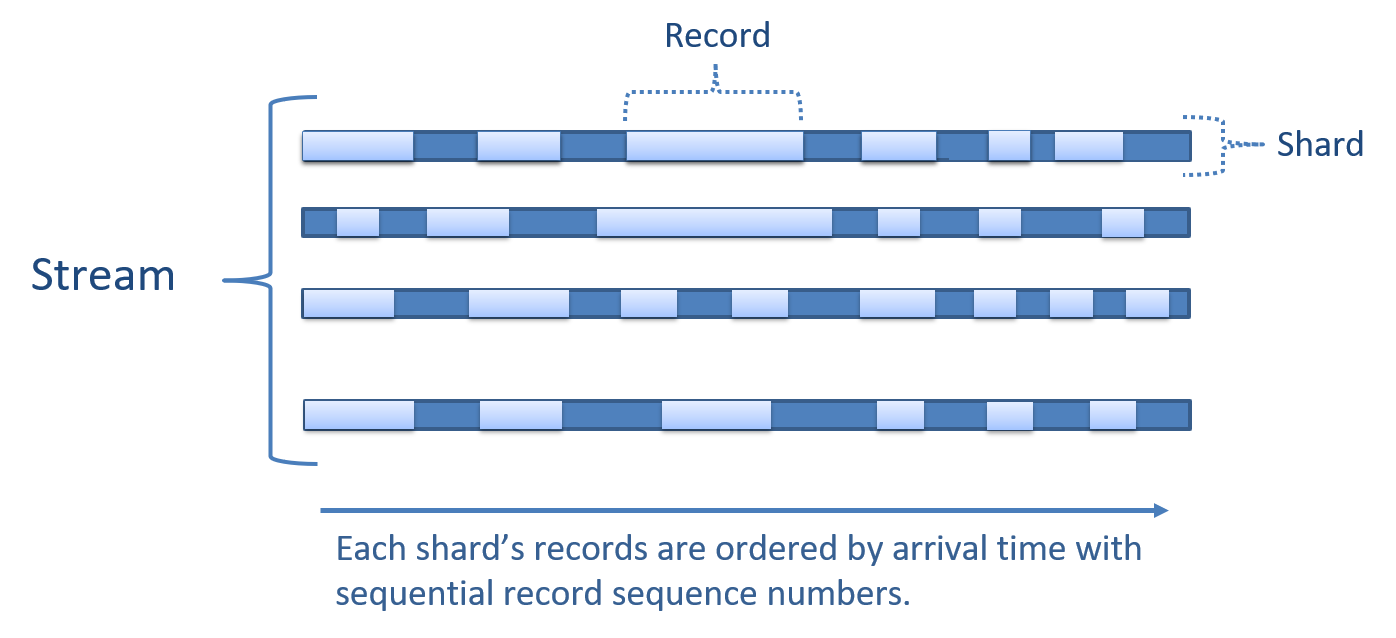
Sequencing of records by their ingestion time (the time the data arrived at the platform) is guaranteed within each shard but not across shards.
By default, the platform handles assignment of records to shards internally, using the Randomized Round Robin (RRR) algorithm. However, the producer can select to assign new stream records to specific shards by providing the shard ID for each record. Alternatively, the producer can select to use custom partition keys to influence the designation of records to shards: as explained in the following Record Metadata section, the producer can optionally provide partition-key metadata for new records. The platform uses a hash function to map a record's partition key (if provided) to a specific shard, so that in the context of a fixed shard structure all records with the same key are mapped to the same shard (subject to the documented exceptions). This mechanism allows you to group similar records together and ensure a specific sequence of record consumption. If both a shard ID and a partition key are provided, the record is assigned based on the shard ID and the partition key does not affect the shard assignment.
When creating a stream, you must configure its shard count (the number
of shards in the stream).
You can increase the shard count at any time, but you cannot reduce it.
From the platform's perspective, there is virtually no cost to creating even thousands of shards.
Note that after increasing a stream's shard count, new records with a previously used partition key are assigned either to the same shard that was used for this partition key or to a new shard. All records with the same partition key that are added after the shard-count change will be assigned to the same shard (be it the previously used shard or a new shard).
The following diagram depicts a platform data stream with sequenced shard records:
Record Metadata
The platform returns to the consumer, together with the records, metadata for each record. The metadata includes the record's sequence number and ingestion time, as well as the following optional user metadata if provided by the producer during the record submission:
- Client information
- Custom client information, which is opaque to the platform (provided as a blob). You can use this metadata, for example, to save the data format of a record, or the time at which a sensor or application event was triggered.
- Partition key
- A partition key to associate with the record. Records with the same partition-key values are typically assigned to the same shard (unless you override the partition key with a shard ID) — see Stream Sharding and Partitioning.
Stream Record Consumption
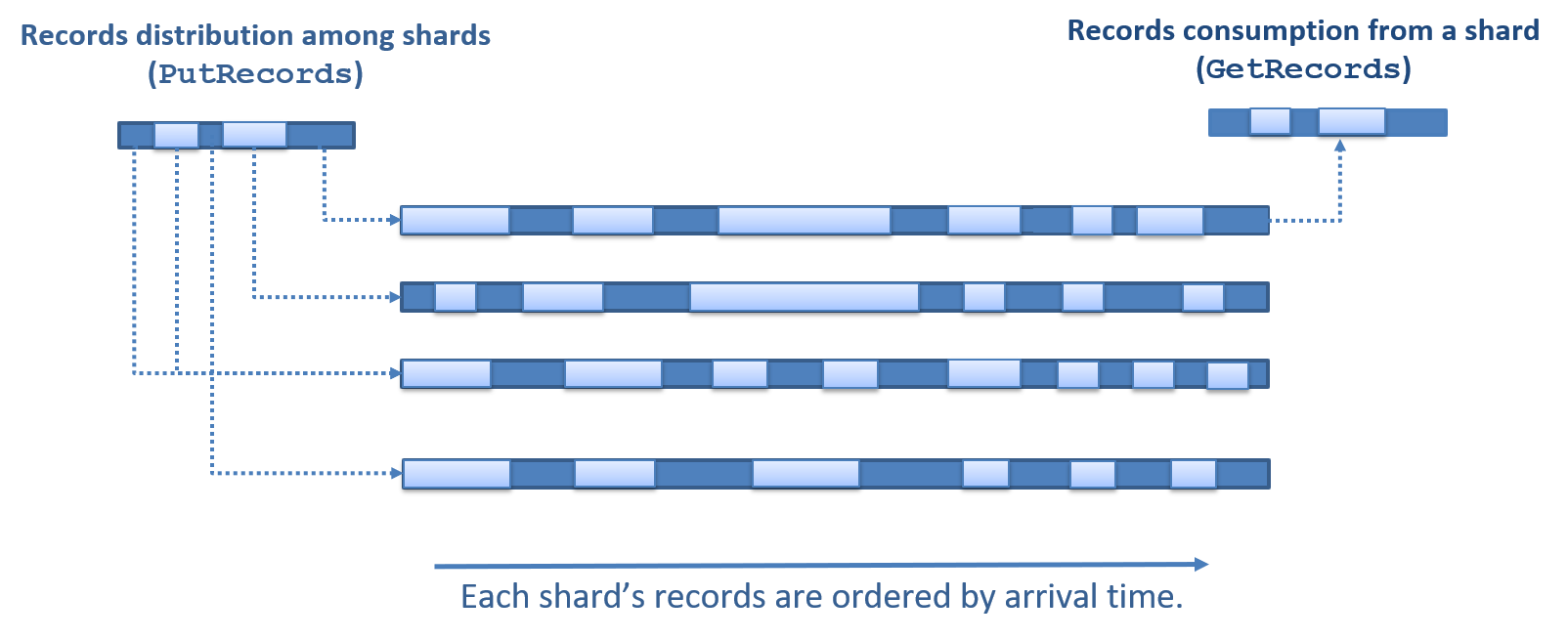
Multiple consumer instances can consume data from the same stream. A consumer retrieves records from a specific shard. It is recommended that you distribute the data consumption among several consumer instances ("workers"), assigning each instance one or more shards.
For each shard, the consumer should determine the location within the shard from which to begin consuming records. This can be the earliest ingested record, the end of the shard, the first ingested record starting at a specific time, or a specific record identified by its sequence number (a unique record identifier that is assigned by the platform based on the record's ingestion time). The consumer first uses a seek operation to obtain the desired consumption location, and then provides this location as the starting point for its record consumption. The consumption operation returns the location of the next record to consume within the shard, and this location should be used as the location for a subsequent consumption operation, allowing for sequential record consumption.
The following diagram demonstrates records ingestion into multiple stream shards (for example, using the Streaming Web API
View Stream Consumption
You can view the stream consumption of the V3IO consumer groups at the project level.
In the
Deleting Streams
Currently, most platform APIs don't have a dedicated method for deleting a stream. However, you can use the file-system interface to delete a stream directory from the relevant data container:
rm -r <path to stream>The following examples delete a "mystream" stream from a "mycontainer" container:
-
Local file-system command —
rm -r /v3io/mycontainer/mystream -
Hadoop FS command —
hadoop fs -rm -r v3io://mycontainer/mystream