Working with NoSQL (Key-Value) Data
Overview
The platform provides a NoSQL database service, which supports storage and consumption of data in a tabular format.
A table is a collection of data objects known as items (rows), and their attributes (columns).
For example, items can represent people with attribute names such as
You can manage and access NoSQL data in the platform by using the NoSQL Frames, Spark DataFrame, or web APIs.
Terminology Comparison
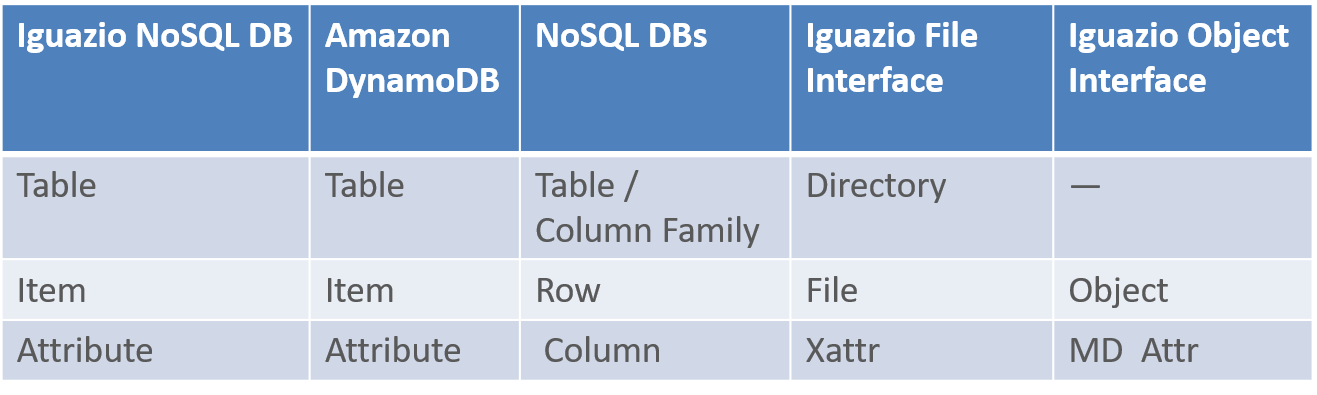
The following table compares the Iguazio AI Platform's NoSQL DB terminology with that of similar third-party tools and the platform's file interface:
Creating Tables
NoSQL tables in the platform don't need to be created prior to ingestion. When writing data to a NoSQL table, if the table doesn't exit, it's automatically created in the specified path as part of the write operation.
Deleting Tables
Currently, most platform APIs don't have a dedicated method for deleting a table.
An exception to this is the
rm -r <path to table>The following examples delete a "mytable" table from a "mycontainer" container:
-
Local file-system command —
rm -r /v3io/mycontainer/mytable -
Hadoop FS command —
hadoop fs -rm -r v3io://mycontainer/mytable
Partitioned Tables
Table partitioning is a common technique for optimizing physical data layout and related queries. In a partitioned table, some item attributes (columns) are used to create partition directories within the root table directory using the format
When defining table partitions, follow these guidelines:
- Partition the table according to the queries that you expect to be run most often.
For example, if you expect most queries to be by
day , define a singleday partition. However, if you expect most queries to be based on other attributes, partition your table accordingly; for example, if most queries will be bycountry ,state , andcity , createcountry/state/city partition directories. - Bear in mind that the number of partitions and their sizes affect the performance of the queries: to optimize performance, avoid partitions that are too small (less than 10Ks of items) by consolidating partitions, especially if you have many partitions. For example, partitioning a table by seconds or minutes will result in a huge amount of very small partitions and therefore querying the table is likely to be inefficient, especially if you expect to have occasional scans of a larger period of time (such as a year).
Read Optimization
By default, read requests (queries) on a NoSQL table are processed by scanning all items in the table, which affects performance. However, the platform's NoSQL APIs support two types of read optimizations that can be used to improve performance:
Both optimizations involve queries on the table's primary key or its components and rely on the way that data objects (such as table items) are stored in the platform: the name of the object is the value of its primary-key attribute; the object is mapped to a specific data slice according to the value of its sharding key (which is also the primary key for simple object names); and objects with a compound primary key that have the same sharding-key value are sorted on the data slice according to the value of their sorting key. See Object Names and Primary Keys.
It's recommended that you consider these optimizations when you select your table's primary key and plan your queries. For more information and best-practice guidelines, see Best Practices for Defining Primary Keys and Distributing Data Workloads.
Faster Item-Specific Queries
The fastest table queries when using the platform's NoSQL Web API are those that uniquely identify a specific item by its primary-key value.
Such queries are processed more efficiently because the platform searches the names of the object files only on the relevant data slice and stops the search when the requested item is located.
See the web-API
Range Scans
A range scan is a query for specific sharding-key values and optionally also for a range of sorting-key values, which is processed by searching the sorted object names on the data slice that is associated with the specified sharding-key value(s). Such processing is more efficient than the standard full table scan, especially for large tables.
When using Frames, or NoSQL Spark DataFrames, the platform executes range scans automatically for compatible queries. When using the NoSQL Web API, you can select whether to perform a range scan, a parallel scan, or a standard full table scan.
Note that to support and use range scans effectively, you need to have a table with a compound <sharding key>.<sorting key> primary key that is optimized for your data set and expected data-access patterns.
When using a NoSQL Spark DataFrame, the table must also contain sharding- and sorting-key user attributes.
Note that range scans are more efficient when using a string sorting-key attribute.
For more information and best-practice guidelines, see the Best Practices for Defining Primary Keys and Distributing Data Workloads guide, and especially the Using a Compound Primary Key for Faster NoSQL Table Queries and Using a String Sorting Key for Faster Range-Scan Queries guidelines.