High Availability (HA)
Overview
The On-Prem Operational Cluster and Cloud Operational Cluster configurations of the Iguazio AI Platform ("the platform") are high-availability (HA) clusters. They are designed from the ground up as a shared-nothing (SN) architecture — a distributed architecture with no single point of failure (SPOF). Every cluster has at least three data nodes and supports data replication, ensuring high availability.
Data-Replication and Failover
The platform's data-distribution architecture ensures that there are always two copies of each data element. The system provides strong consistency at the object level: only one consistent state can be observed by all users at any given point in time. The provided solution uses high-end and enterprise-grade hardware in terms of reliability. The platform uses Non-Volatile Memory Express (NVMe) drives with 2M hours of mean time between failure (MTBF) and 5 drive writes per day (DWPD) endurance.
The data distribution is done by using a variant of the consistent hashing algorithm with a fixed number of partitions. Each data node in the cluster is divided into virtual nodes (VNs). Each data container is divided into slices ("partitions"), which are the basic units for data distribution and recovery. Each slice is handled by both a primary and a secondary VN. Each pair of primary and secondary VNs has a very limited set of shared slices. Consequently, in the event of a software or hardware failure, the service remains available without interruption while maintaining load balancing.
The platform is designed to support CAP-theorem CP (consistent but not available under network partitions) over AP (available but not consistent under network partitions). This means that in the possible event of partitioning, data availability is sacrificed to preserve consistency.
The platform's data-distribution implementation consists of two planes— a control plane and a data plane.
The Control Plane
The control plane determines the cluster members and creates a slice-mapping table. This plane:
- Uses the Raft consensus algorithm to define for each container the slice distribution among the VNs.
- Uses a variation of a consistent-hashing algorithm to distribute the container data across the VNs.
The Data Plane
The data plane provides strong consistency. This plane:
- Replicates I/O between the primary VN and its secondary VN.
- Ensures that a minimal number of hops is required to complete an I/O operation by sending the I/O request to the primary VN and handling retries for different failure scenarios.
- Distributes the data among the VNs according to the distribution rules defined by the control plane.
The data plane uses the V3IO library, which serves as the platform's I/O interface and controls access to data. This library uses a mathematical function to identify the parent slice of each data element and map the slice to its primary VN by using the control plane's slice-mapping table. This mapping is dynamically updated as a result of relevant changes to the cluster, such as in the event of a scale-out scenario or upon a system failure. The V3IO library is linked to the user application and its implementation is entirely transparent, so users don't need to be aware of the internal distribution mechanism.
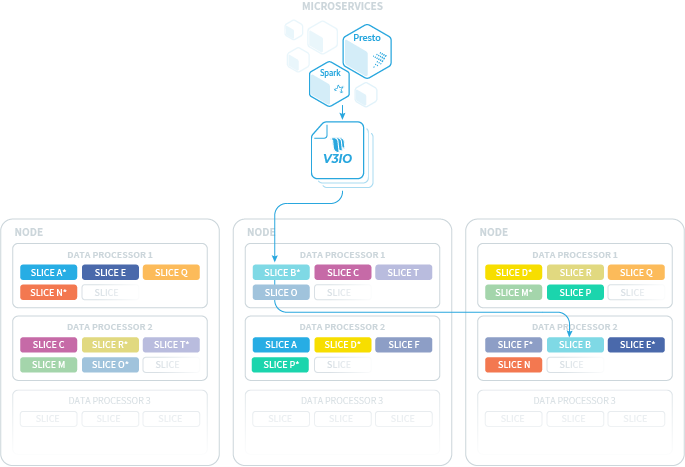
Slice Distribution
Following are some key principles of the platform's slice-distribution algorithm:
- Same number of primary and secondary roles per VN — to support load balancing.
- Balanced peer to peer pairing — to minimize rebuild times.
- Per-container slice table — to ensure that the same object name will fall under different slices for different containers.
The following image demonstrates slice distribution:
Write I/O Flow
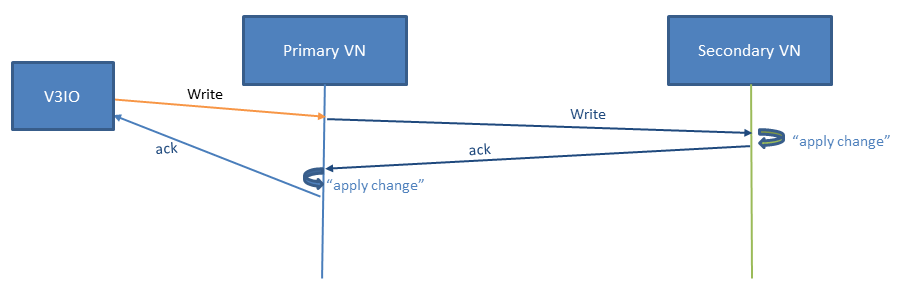
The following diagram describes a write I/O flow, demonstrating these concepts:
- Strong consistency guarantees that every acknowledged write can be viewed immediately and upon any failure.
- Atomic updates guarantee that only the old or new data image is visible at any given point in time, enabling multiple parallel uncoordinated application updates.
Auto switch to online
When a cluster goes offline, the system automatically attempts to change it back to online after 10 minutes, by default. You can modify this value in cluster.yml. The state of the cluster is not modified: if it was degraded when it went offline, it stays degraded when it returns to online. Results are written to the Events log.