Ingesting and Preparing Data
Learn about different methods for ingesting data into the Iguazio AI Platform, analyzing the data, and preparing it for the next step in your data pipeline.
Overview
The Iguazio AI Platform ("the platform) allows storing data in any format. The platform's multi-model data layer and related APIs provide enhanced support for working with NoSQL ("key-value"), time-series, and stream data. Various steps of the data science life cycle (pipeline) might require different tools and frameworks for working with data, especially when it comes to the different mechanisms required during the research and development phase versus the operational production phase. The platform features a wide set of methods for manipulating and managing data, of different formats, in each step of the data life cycle, using a variety of frameworks, tools, and APIs — such as Spark SQL and DataFrames, Spark Streaming, Trino SQL queries, pandas DataFrames, Dask, the V3IO Frames Python library, and web APIs.
This tutorial provides an overview of various methods for collecting, storing, and manipulating data in the platform, and refers to sample tutorial notebooks that demonstrate how to use these methods.
For an in-depth overview of the platform and how it can be used to implement a full data science workflow, see In-Depth Platform Overview.
For information about the available full end-to-end use-case application and how-to demos, see Introducing the Platform.
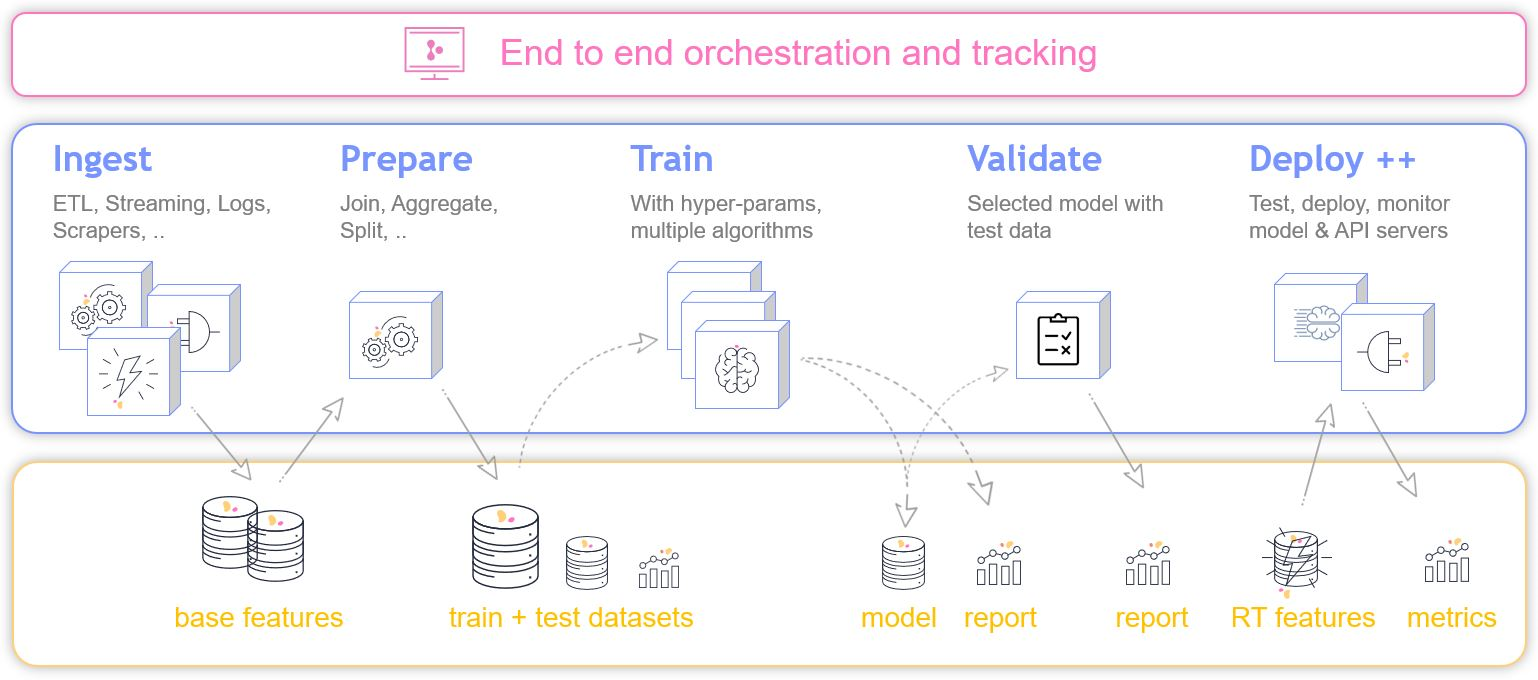
Basic Flow
The virtual-env tutorial walks you through basic scenarios of ingesting data from external sources into the platform's data store and manipulating the data using different data formats. The tutorial includes an example of ingesting a CSV file from an AWS S3 bucket; converting it into a NoSQL table using Spark DataFrames; running SQL queries on the table; and converting the table into a Parquet file.
The Platform's Data Layer
The platform features an extremely fast and secure data layer (a.k.a. "data store") that supports storing data in different formats — SQL, NoSQL, time-series databases, files (simple objects), and streaming. The data is stored within data containers can be accessed using a variety of APIs — including simple-object, NoSQL ("key-value"), and streaming APIs. For detailed information, see the data-layer APIs overview and the data-layer API references.
Platform Data Containers
Data is stored within data containers in the platform's distributed file system (DFS), which makes up the platform's data layer (a.k.a. "data store"). There are predefined containers, such as the "users" container, and you can also create additional custom containers. For detailed information about data containers and how to use them and reference data in containers, see Data Containers and API Data Paths.
The Simple-Object Platform API
The platform's Simple-Object API enables performing simple data-object and container operations that resemble the Amazon Web Services (AWS) Simple Storage Service (S3) API. In addition to the S3-like capabilities, the Simple-Object Web API enables appending data to existing objects. See Data Objects and the Simple-Object Web API Reference. For more information and API usage examples, see the v3io-objects tutorial.
The NoSQL (Key-Value) Platform API
The platform's NoSQL (a.k.a. key-value/KV) API provides access to the platform's NoSQL data store (database service), which enables storing and consuming data in a tabular format. See Working with NoSQL Data. For more information and API usage examples, see the v3io-kv tutorial.
The Streaming Platform API
The platform's Streaming API enables working with data in the platform as streams. See the Streaming Web API Reference. For more information and API usage examples, see the v3io-streams tutorial. In addition, see the Working with Streams section in the current tutorial for general information about different methods for working with data streams in the platform.
Reading Data from External Databases
You can use different methods to read data from external databases into the platform's data store, such Spark over JDBC or SQLAlchemy.
Using Spark over JDBC
Spark SQL includes a data source that can read data from other databases using Java database connectivity (JDBC). The results are returned as a Spark DataFrame that can easily be processed using Spark SQL, or joined with other data sources. The spark-jdbc tutorial includes several examples of using Spark JDBC to ingest data from various databases — such as MySQL, Oracle, and PostgreSQL.
Using SQLAlchemy
The read-external-db tutorial outlines how to ingest data using SQLAlchemy — a Python SQL toolkit and Object Relational Mapper, which gives application developers the full power and flexibility of SQL — and then use Python DataFrames to work on the ingested data set.
Working with Spark
The platform has a default pre-deployed Spark service that enables ingesting, analyzing, and manipulating data using different Spark APIs:
- Using Spark SQL and DataFrames
- Using the Spark Streaming API — see Using Streaming Streaming under "Working with Spark".
Using Spark SQL and DataFrames
Spark lets you write and query structured data inside Spark programs by using either SQL or a familiar DataFrame API. DataFrames and SQL provide a common way to access a variety of data sources. You can use the Spark SQL and DataFrames API to ingest data into the platform, for both batch and micro-batch processing, and analyze and manipulate large data sets, in a distributed manner.
The platform's custom NoSQL Spark DataFrame implements the Spark data-source API to support a custom data source that enables reading and writing data in the platform's NoSQL store using Spark DataFrames, including enhanced features such as data pruning and filtering (predicate push down); queries are passed to the platform's data store, which returns only the relevant data. This allows accelerated and high-speed access from Spark to data stored in the platform.
The spark-sql-analytics tutorial demonstrates how to use Spark SQL and DataFrames to access objects, tables, and unstructured data that persists in the platform's data store.
For more information about running SQL queries with Spark, see Running Spark SQL Queries under "Running SQL Queries on Platform Data".
Working with Streams
The platform supports various methods for working with data streams, including the following:
- Using Nuclio to Get Data from Common Streaming Engines
- Using the Platform's Streaming Engine
- Using Spark Streaming
Using Nuclio to Get Data from Common Streaming Engines
The platform has a default pre-deployed Nuclio service that uses Iguazio's Nuclio serverless-framework, which provides a mechanism for analyzing and processing real-time events from various streaming engines. Nuclio currently supports the following streaming frameworks — Kafka, Kinesis, Azure Event Hubs, platform streams (a.k.a. V3IO streams), RabbitMQ, and MQTT.
Using Nuclio functions to retrieve and analyze streaming data in real time is a very common practice when building a real-time data pipeline. You can stream any type of data — such as telemetry (NetOps) metrics, financial transactions, web clicks, or sensors data — in any format, including images and videos. You can also implement your own logic within the Nuclio function to manipulate or enrich the consumed stream data and prepare it for the next step in the pipeline.
Nuclio serverless functions can sustain high workloads with very low latencies, thus making them very useful for building an event-driven applications with strict latency requirements.
For more information about Nuclio, see the Nuclio Serverless Functions.
Using the Platform's Streaming Engine
The platform features a custom streaming engine and a related stream format — a platform stream (a.k.a. V3IO stream). You can use the platform's streaming engine to write data into a queue in a real-time data pipeline, or as a standard streaming engine (similar to Kafka and Kinesis), so you don't need to use an external engine.
The platform's streaming engine is currently available via the platform's Streaming Web API.
In addition, the platform's Spark-Streaming Integration API enables using the Spark Streaming API to work with platform streams, as explained in the next section (Using Spark Streaming).
The v3io-streams tutorial demonstrates basic usage of the streaming API.
Using Spark Streaming
You can use the Spark Streaming API to ingest, consume, and analyze data using data streams. The platform features a custom Spark-Streaming Integration API to allow using the Spark Streaming API with platform streams.
Running SQL Queries on Platform Data
You can run SQL queries on NoSQL and Parquet data in the platform's data store, using any of the following methods:
- Running full ANSI Trino SQL queries using SQL magic
- Running Spark SQL queries
- Running SQL queries from Nuclio functions
Running Full ANSI Trino SQL Queries
The platform has a default pre-deployed Trino service that enables using the Trino open-source distributed SQL query engine to run interactive SQL queries and perform high-performance low-latency interactive analytics on data that's stored in the platform.
To run a Trino query from a Jupyter notebook, all you need is to use an SQL magic command — %sql followed by your Trino query.
Such queries are executed as distributed queries across the platform's application nodes.
The basic-data-ingestion-and-preparation tutorial demonstrates how to run Trino queries using SQL magic.
Note that for running queries on Parquet tables, you need to work with Hive tables. The csv-to-hive tutorial includes a script that converts a CSV file into a Hive table.
Running Spark SQL Queries
The spark-sql-analytics tutorial demonstrates how to run Spark SQL queries on data in the platform's data store.
For more information about the platform's Spark service, see Working with Spark in this tutorial.
Running SQL Queries from Nuclio Functions
In some cases, you might need to run SQL queries as part of an event-driven application. The nuclio-read-via-presto tutorial demonstrates how to run an SQL query from a serverless Nuclio function.
Running SQL Queries from MLRun Jobs
In some cases, you might need to run SQL queries as part of an MLRun job. The mlrun-read-via-presto tutorial demonstrates how to run an SQL query from an MLRun job using Trino.
Working with Parquet Files
Parquet is a columnar storage format that provides high-density high-performance file organization.
The parquet-read-write tutorial demonstrates how to create and write data to a Parquet table in the platform and read data from the table.
After you ingest Parquet files into the platform, you might want to create related Hive tables and run SQL queries on these tables.
The parquet-to-hive tutorial demonstrates how you can do this using Spark DataFrames.
Accessing Platform NoSQL and TSDB Data Using the Frames Library
V3IO Frames ("Frames") is a multi-model open-source data-access library, developed by Iguazio, which provides a unified high-performance DataFrame API for working with data in the platform's data store.
Frames currently supports the NoSQL (key-value) and time-series (TSDB) data models via its NoSQL (nosql|kv) and TSDB (tsdb) backends.
The frames tutorial provides an introduction to Frames and demonstrates how to use it to work with NoSQL and TSDB data in the platform.
See also the Frames API reference.
Getting Data from AWS S3 Using curl
A simple way to ingest data from the Amazon Simple Storage Service (S3) into the platform's data store is to run a curl command that sends an HTTP request to the relevant AWS S3 bucket, as demonstrated in the following code cell. For more information and examples, see the basic-data-ingestion-and-preparation tutorial.
%%sh
CSV_PATH="/User/examples/stocks.csv"
curl -L "https://s3.wasabisys.com/iguazio/data/stocks/2018-03-26_BINS_XETR08.csv" > ${CSV_PATH}
Running Distributed Python Code with Dask
Dask is a flexible library for parallel computation in Python, which is useful for computations that don't fit into a DataFrame. Dask exposes low-level APIs that enable you to build custom systems for in-house applications. This helps parallelize Python processes and dramatically accelerates their performance. The dask-cluster tutorial demonstrates how to use Dask with platform data.
Dask is pre-deployed in the platform's Jupyter Notebook service. For more information about using Dask in the platform, see the Dask application service.
Running DataFrames on GPUs using NVIDIA cuDF
The platform allows you to use NVIDIA's RAPIDS open-source libraries suite to execute end-to-end data science and analytics pipelines entirely on GPUs. cuDF is a RAPIDS GPU DataFrame library for loading, joining, aggregating, filtering, and otherwise manipulating data. This library features a pandas-like API that will be familiar to data engineers and data scientists, who can use it to easily accelerate their workflows without going into the details of CUDA programming. The gpu-cudf-vs-pd tutorial demonstrates how to use the cuDF library and compares performance benchmarks with pandas and cuDF.
For more information about the platform's GPU support, see Running Applications over GPUs.
Visualizing Data with Grafana
The platform has a Grafana service with predefined dashboards that leverage the monitoring service to display monitoring data, such as performance statistics, for application services.
You can also define custom Grafana dashboards for monitoring, visualizing, and understanding data stored in the platform, such as time-series metrics and NoSQL data.
You can read and analyze data from the platform's data store and visualize it on Grafana dashboards in the desired formats, such as tables and graphs.
This can be done by using the custom iguazio data source, or by using a Prometheus data source for running Prometheus queries on platform TSDB tables.
You can also issue data alerts and create, explore, and share dashboards.
You can use Iguazio's https://github.com/v3io/grafwiz Python library to create an deploy Grafana dashboards programmatically, as demonstrated in the grafana-grafwiz tutorial.